
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 구글 검색 결과 크롤링 on Google, you do not find the information you need! Here are the best content compiled and compiled by the Chewathai27.com/to team, along with other related topics such as: 구글 검색 결과 크롤링 구글 검색 결과 크롤링, 파이썬, 구글 크롤링, 구글 크롤링 차단, 구글 크롤링 요청, 구글 크롤링 프로그램, 구글 검색결과 변경, 셀레니움 구글 검색, 구글 스칼라 크롤링
Table of Contents
경영학도의 파이썬 일기장 : 네이버 블로그
- Article author: blog.naver.com
- Reviews from users: 24873
 Ratings
Ratings - Top rated: 4.8
- Lowest rated: 1
- Summary of article content: Articles about 경영학도의 파이썬 일기장 : 네이버 블로그 이번 시간에는 구글에서 키워드를 검색한 후 검색 결과의 제목과 url주소를 크롤링하는 방법을 배워보도록 하겠다. 구글 크롤링은 네이버 크롤링과 … …
- Most searched keywords: Whether you are looking for 경영학도의 파이썬 일기장 : 네이버 블로그 이번 시간에는 구글에서 키워드를 검색한 후 검색 결과의 제목과 url주소를 크롤링하는 방법을 배워보도록 하겠다. 구글 크롤링은 네이버 크롤링과 …
- Table of Contents:
구글 검색결과 크롤링
- Article author: strangefate.github.io
- Reviews from users: 22752 Ratings
- Top rated: 4.3
- Lowest rated: 1
- Summary of article content: Articles about 구글 검색결과 크롤링 구글 검색결과 크롤링. 본 크롤링 코드는 구글 검색결과중 게시글 제목과 URL을 검색결과 10페이지까지 크롤링합니다. 14일 밤, 엑셀로 정리된 키워드 … …
- Most searched keywords: Whether you are looking for 구글 검색결과 크롤링 구글 검색결과 크롤링. 본 크롤링 코드는 구글 검색결과중 게시글 제목과 URL을 검색결과 10페이지까지 크롤링합니다. 14일 밤, 엑셀로 정리된 키워드 … StrangeFate의 블로그입니다.
- Table of Contents:
모더나 백신 후기_졸리고 어지럽고 가슴아프고
파이콘 한국 2021 티켓 구매 오픈
BeautifulSoup와 selenium 이용한 구글 검색화면 크롤링 실습
- Article author: velog.io
- Reviews from users: 1014 Ratings
- Top rated: 4.4
- Lowest rated: 1
- Summary of article content: Articles about BeautifulSoup와 selenium 이용한 구글 검색화면 크롤링 실습 -\ 어떤 거 검색할래? -\ 파이썬 -\ 그래(크롬창을 열고 닫음, 결과 보여줌). 파이썬 파일로 저장해서 그런 건지는 모르겠지만, 자바스크립트처럼 … …
- Most searched keywords: Whether you are looking for BeautifulSoup와 selenium 이용한 구글 검색화면 크롤링 실습 -\ 어떤 거 검색할래? -\ 파이썬 -\ 그래(크롬창을 열고 닫음, 결과 보여줌). 파이썬 파일로 저장해서 그런 건지는 모르겠지만, 자바스크립트처럼 … 크롤링 정규수업을 복습하다가, 영 혼자 해결을 못해서 유튜브로 조금 더 학습을 해봤다. 기존에 주피터 노트북에서만 하던 걸 벗어나 VS Code에서 .py 파일로
- Table of Contents:

ì ë³´ 구ì±: Google ê²ìì ìë ë°©ì
- Article author: www.google.com
- Reviews from users: 23723 Ratings
- Top rated: 4.6
- Lowest rated: 1
- Summary of article content: Articles about ì ë³´ 구ì±: Google ê²ìì ìë ë°©ì 사용자가 검색할 때 Google은 유용한 정보를 찾기 위해 전 세계의 모든 도서관을 합친 것보다 더 많은 정보가 저장된 검색 색인에서 수천억 개의 웹페이지와 기타 … …
- Most searched keywords: Whether you are looking for ì ë³´ 구ì±: Google ê²ìì ìë ë°©ì 사용자가 검색할 때 Google은 유용한 정보를 찾기 위해 전 세계의 모든 도서관을 합친 것보다 더 많은 정보가 저장된 검색 색인에서 수천억 개의 웹페이지와 기타 … ì¬ì©ìê° ê²ìí ë Googleì ì ì©í ì 보를 찾기 ìí´ ì ì¸ê³ì 모ë ëìê´ì í©ì¹ ê²ë³´ë¤ ë ë§ì ì ë³´ê° ì ì¥ë ê²ì ìì¸ìì ìì²ìµ ê°ì ì¹íì´ì§ì 기í ì½í ì¸ ë¥¼ ì´í´ë´ ëë¤.
- Table of Contents:

Python 웹 크롤링 (Web Crawling) 06. 구글 크롤링
- Article author: j-ungry.tistory.com
- Reviews from users: 25722 Ratings
- Top rated: 3.2
- Lowest rated: 1
- Summary of article content: Articles about Python 웹 크롤링 (Web Crawling) 06. 구글 크롤링 오늘은 맨날 네이버만 크롤링 하다가 구글을 크롤링 해볼거당 … 구글에 파이썬 검색 … 놀랍게도 url 이 바뀌었지만 검색 결과는 똑같다 ! …
- Most searched keywords: Whether you are looking for Python 웹 크롤링 (Web Crawling) 06. 구글 크롤링 오늘은 맨날 네이버만 크롤링 하다가 구글을 크롤링 해볼거당 … 구글에 파이썬 검색 … 놀랍게도 url 이 바뀌었지만 검색 결과는 똑같다 ! 공부용이라 소스코드 들쭉날쭉할 수 있음 (참고할 사람들은 소스코드 유의깊게보기) 참고는 프로그래머 김플 스튜디오 유튜브 오늘은 맨날 네이버만 크롤링 하다가 구글을 크롤링 해볼거당 야호 웹 크롤링 3번 게..
- Table of Contents:
정구리의 우주정복
Python 웹 크롤링 (Web Crawling) 06 구글 크롤링 본문
파이썬 / 검색어로 검색된 결과를 주소와 제목을 불러오기
- Article author: beauty886699.tistory.com
- Reviews from users: 1597 Ratings
- Top rated: 3.6
- Lowest rated: 1
- Summary of article content: Articles about 파이썬 / 검색어로 검색된 결과를 주소와 제목을 불러오기 구글에서 검색한 검색결과의 주소와 제목을 크롤링으로 가져오기 쉽죠? # import urllib.parse import quote_plus import urllib.parse from bs4 … …
- Most searched keywords: Whether you are looking for 파이썬 / 검색어로 검색된 결과를 주소와 제목을 불러오기 구글에서 검색한 검색결과의 주소와 제목을 크롤링으로 가져오기 쉽죠? # import urllib.parse import quote_plus import urllib.parse from bs4 … 구글에서 검색한 검색결과의 주소와 제목을 크롤링으로 가져오기 쉽죠? # import urllib.parse import quote_plus import urllib.parse from bs4 import BeautifulSoup from selenium import webdriver import tim..네이버뉴스, 쿠팡파트너스, 다음뉴스네이버뉴스, 쿠팡파트너스, 다음뉴스반가워요~ 여러분에게 유익하고 실시간 할인정보를 공유하려고 해요~ 이 포스팅은 제휴마케팅의 활동의 일환으로 이에 따른 일정액의 수수료를 제공받고 있어요~ 계속 업데이트 할게요~ 반가워요~!
(비즈니스 문의: [email protected]) - Table of Contents:
FLASK 4 – 웹 크롤링 구글검색결과 웹 페이지에 표시하기
- Article author: whereisend.tistory.com
- Reviews from users: 12069 Ratings
- Top rated: 3.9
- Lowest rated: 1
- Summary of article content: Articles about FLASK 4 – 웹 크롤링 구글검색결과 웹 페이지에 표시하기 웹 크롤링을 하기 전, 필요한 라이브러리에 대해 설명한다. requests 파이썬에서 HTTP 요청을 보내는 모듈이다. BeautifulSoup HTML과 XML 문서를 … …
- Most searched keywords: Whether you are looking for FLASK 4 – 웹 크롤링 구글검색결과 웹 페이지에 표시하기 웹 크롤링을 하기 전, 필요한 라이브러리에 대해 설명한다. requests 파이썬에서 HTTP 요청을 보내는 모듈이다. BeautifulSoup HTML과 XML 문서를 … 웹 크롤링을 하기 전, 필요한 라이브러리에 대해 설명한다. requests 파이썬에서 HTTP 요청을 보내는 모듈이다. BeautifulSoup HTML과 XML 문서를 파싱하기 위해 사용하는 파이썬 패키지 페이지에 대한 구문 분석..
- Table of Contents:
양갱로그
FLASK 4 – 웹 크롤링 구글검색결과 웹 페이지에 표시하기 본문
티스토리툴바
구글서칭결과크롤링+CSV파일저장시키기 :: DailyCoding
- Article author: dlsdn73.tistory.com
- Reviews from users: 29219 Ratings
- Top rated: 4.0
- Lowest rated: 1
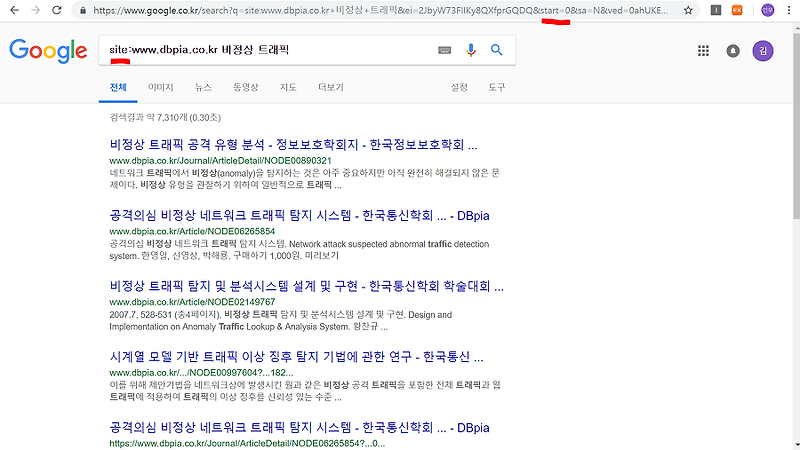
- Summary of article content: Articles about 구글서칭결과크롤링+CSV파일저장시키기 :: DailyCoding 그래서 site:www.dbpia.co.kr 비정상 트래픽 으로 검색을 해보았다. 검사결과는 위의 그림처럼 , 내가 검색하고자 하는 사이트별로 , 검색결과 … …
- Most searched keywords: Whether you are looking for 구글서칭결과크롤링+CSV파일저장시키기 :: DailyCoding 그래서 site:www.dbpia.co.kr 비정상 트래픽 으로 검색을 해보았다. 검사결과는 위의 그림처럼 , 내가 검색하고자 하는 사이트별로 , 검색결과 … 오늘은 구글에서 비정상트래픽을 검사한 뒤 , 서칭된 결과들을 바탕으로 , 본문기사의 url을 가져와서 , 그 url에 해당하는 논문의 초록을 가져와 볼 것이다. 먼저 , 구글에 “비정상트래픽”을 검색해 본다 검색..Daily Coding .
Share information . - Table of Contents:
구글서칭결과크롤링+CSV파일저장시키기
티스토리툴바
See more articles in the same category here: Top 804 tips update new.
BeautifulSoup와 selenium 이용한 구글 검색화면 크롤링 실습
크롤링 정규수업을 복습하다가, 영 혼자 해결을 못해서 유튜브로 조금 더 학습을 해봤다. 기존에 주피터 노트북에서만 하던 걸 벗어나 VS Code에서 .py 파일로 진행했다. 참고로 VS Code 활용하니까 자동 완성이 돼서 너무 편하고 좋았다..
[컴터와 나의 대화]-\ 어떤 거 검색할래?
-\ 파이썬
-\ 그래(크롬창을 열고 닫음, 결과 보여줌)
파이썬 파일로 저장해서 그런 건지는 모르겠지만, 자바스크립트처럼 문답을 실행해봐서 참신했다. 그 작업에 간접적으로 활용된 새로운 라이브러리도 있다.
우선 아래와 같이 라이브러리를 불러온다. 설치가 필요한 경우, vs code 내 터미널 창에서 pip install beautifulsoup4 와 pip install selenium 을 먼저 설치하고 아래 라이브러리를 불러온다. (주피터 노트북의 경우 대부분의 라이브러리가 자체적으로 설치 되어 있어서 pip를 할 필요는 없다. selenium은 없지만)
from urllib.parse import quote_plus from bs4 import BeautifulSoup from selenium import webdriver
유튜브 강사는 구글로 ‘파이썬’을 검색했을 때의 url을 찬찬히 봤다. 보면서, 다른 페이지로 이동하는 경우(이미지 검색, 뉴스 검색 등) 주소가 어떻게 달라지는지 살피고 아래와 같이 baseUrl과 검색어에 따라 달라지는 이후 부분인 plusUrl을 구분했다. 그리고 아래와 같은 인터랙션?이 가능하도록 했다. 코드 전체를 실행하면 ‘무엇을 검색할까요? :’가 나오고 거기에 ‘파이썬’을 입력하면 구글에서의 ‘파이썬’ 검색 결과를 크롤링하는 방식이다.
baseUrl = ‘https://www.google.com/search?q=’ plusUrl = input(‘무엇을 검색할까요? :’) url = baseUrl + quote_plus(plusUrl)
위에서 quote_plus가 나온다. 한글은 인터넷에서 바로 사용하는 방식이 아니라 변환이 필요한데 이때 역할을 해주는 친구다. 왜 아무리 한글로 해도 URL에 막 %CE%GD%EC 이런 거 나오잖아요? 그렇게 변환해주는 친구다.
이 이후에 큰 위기에 봉착했는데, 셀레니움을 위해 미리 깔았던 chromedriver가 정말… 화가 많이(순화) 날 정도로 동작하지 않았다. 같은 폴더 내에 설치했음에도 불구, path가 잘못 되었다느니 어쩌구 저쩌구 해서 결국 강사의 예시와 달리 path를 설정해주었다. 그 이후 url을 얻어 가져온 과정까지는 아래와 같다.
(그러고보니 이 과정에서는 html 파싱이 없는 듯하다. 그래도 되는 건가..?)
driver = webdriver.Chrome(executable_path= r’/Users/user/Desktop/python_trial/chromedriver’) driver.get(url) html = driver.page_source soup = BeautifulSoup(html)
그리고 나서 내가 원하는 부분, 즉 검색 결과 페이지의 제목과 링크를 얻기 위해 해당 구역의 class를 아래와 같이 변수 v로 지정했다. (강의에서는 print(type(v)) 했을 때 list형이 나왔는데, 나는 bs4.element.ResultSet이 나왔고 이 역시 list처럼 취급해 줄 수 있다고 한다.
v = soup.select(‘.yuRUbf’)
최종적으로 해당 내용들을 볼 수 있도록 for문을 활용하여 정리하고 셀레니움으로 인해 열렸던 크롬 화면을 닫으면 원하는 크롤링이 마무리된다.
for i in v: print(i.select_one(‘.LC20lb.DKV0Md’).text) # 제목 print(i.a.attrs[‘href’]) # 링크 print() driver.close() # 크롬 창 닫기
클래스 입력에 관한 몇 가지 이야기
클래스는 . 를 쓰고 아이디는 # 을 쓴다.
엘리먼트 사이에 공백이 있는 경우 공백 대신 . 을 쓴다.
특정 엘리먼트 하위 엘리먼트를 가져오고 싶으면 .upperelement .lowerelement 요렇게 마침표 사이를 한 칸 띄운다.
요렇게 마침표 사이를 한 칸 띄운다. 특정 엘리먼트 바로 하위 자식 엘리먼트를 가져오고 싶은 경우 이렇게도 쓸 수 있다. .motherelement > .childelement 그런데 바로 위 방법이 있는데 굳이..?
제목 부분에서 그냥 select가 아니라 select_one을 설정한 건 역시 리스트이기 때문이라고 했다. 근데 내가 확인해봤을 때는 오히려 str이 나와서 이 부분도 좀 미심쩍었다. (select_one은 클래스 이름이 .LC~로 시작하는 html 요소 중 첫 번째 요소만 반환한다.)
그리고 링크 부분은 v 에 해당하는 클래스 안에서 링크 태그에 해당하는 애들만 불러오는 방식인데 저렇게 조금 외워야 할 것 같이; 표기하였다.
그렇게 실행한 결과는 아래와 같다. 아직 VS code는 익숙하지 않아 이대로 올려둔다.
전체 코드는 아래와 같다. (크롬드라이버 path는 삭제)
from urllib.parse import quote_plus from bs4 import BeautifulSoup from selenium import webdriver baseUrl = ‘https://www.google.com/search?q=’ plusUrl = input(‘무엇을 검색할까요? :’) url = baseUrl + quote_plus(plusUrl) # 한글은 인터넷에서 바로 사용하는 방식이 아니라, quote_plus가 변환해줌 # URL에 막 %CE%GD%EC 이런 거 만들어주는 친구 driver = webdriver.Chrome() driver.get(url) html = driver.page_source soup = BeautifulSoup(html) v = soup.select(‘.yuRUbf’) # print(type(v)) 강의에서는 list가 나오는데, 나는 bs4.element.ResultSet 나옴.. for i in v: print(i.select_one(‘.LC20lb.DKV0Md’).text) print(i.a.attrs[‘href’]) print() driver.close()
중간에 너무 걸림돌 걸림산이 많고 커서 맥주를 깠지만, 그래도 배운 점들이 있어 이렇게 남겨둔다.
김플 스튜디오님, 좋은 강의 감사합니다. 유튜브 링크
Python 웹 크롤링 (Web Crawling) 06. 구글 크롤링
반응형
공부용이라 소스코드 들쭉날쭉할 수 있음 (참고할 사람들은 소스코드 유의깊게보기)
참고는 프로그래머 김플 스튜디오 유튜브
오늘은 맨날 네이버만 크롤링 하다가 구글을 크롤링 해볼거당
야호
웹 크롤링 3번 게시글을 참고하면 이번께 더 쉬울듯
1. 웹 사이트 분석하기
구글에 파이썬 검색
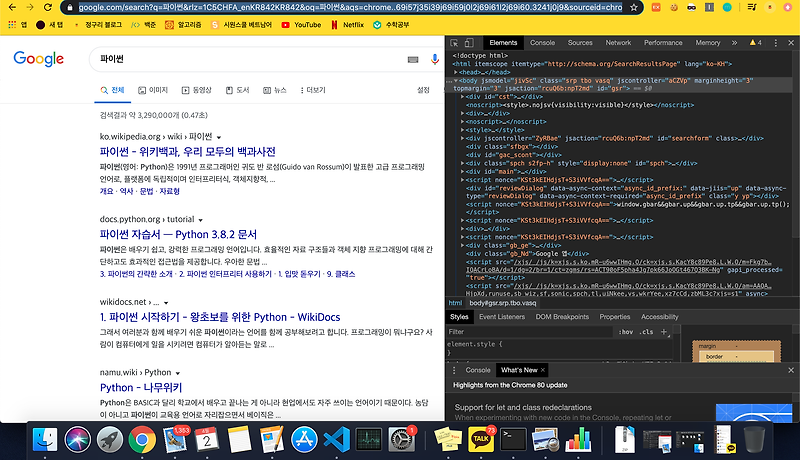
구글에 들어가 파이썬 이라고 검색을 해보면
세상에서 제일 복잡한 url 이 나온다 , 이렇게 복잡하면 분석하기가 힘듬
이때 search?q = ‘. . . ‘ 여기 부분이 실질적으로 검색을 하는 부분인데 이 뒷부분을 모두 지우고 검색을 해보쟈
url 바뀜
놀랍게도 url 이 바뀌었지만 검색 결과는 똑같다 ! 이렇게 우리는 기본 url 을 얻어버림
html 코드를 분석해보자
code 분석
div class = r 안에 내가 원하는 href 와 title 을 가지고 있다 따라서 r을 잘 가져오면 될듯
2. 코드 작성
from urllib.parse import quote_plus from bs4 import BeautifulSoup from selenium import webdriver search = input(“검색어를 입력하세요 : “) url = ‘https://www.google.com/search?q=’ newUrl = url + quote_plus(search) driver = webdriver.Chrome() driver.get(newUrl) html = driver.page_source #열린 페이지 소스 받음 soup = BeautifulSoup(html) r = soup.select(‘.r’) #클래스 r을 선택 select 로 가져오면 list 형식임 for i in r : print(i.select_one(‘.LC20lb.DKV0Md’).text) #select 를 안쓰는 이유는 select 를 쓰면 list 로 불러와져서 text 를쓸 수 없다 print(i.a.attrs[‘href’]) #a 태그의 href 속성 가져오기 print()
별다른 설명은 하지 않겠다 !! (웹크롤링 3번 게시글과 이때가지 한 게시글들과 유사함)
select_one 을 사용하는 이유 : select 를 쓰면 list 형태로 가져오게 되는데 list 형태는 text 를 사용하지 못한다
a 태그의 hret 를 가져오려면 i.a.attrs[‘href’] 이렇게 써주면 됨
이번껀 어렵지 않았다 ! selenium 을 좀 더 많이 사용해봐야지
반응형
검색어로 검색된 결과를 주소와 제목을 불러오기
반응형
구글에서 검색한 검색결과의 주소와 제목을 크롤링으로 가져오기
쉽죠?
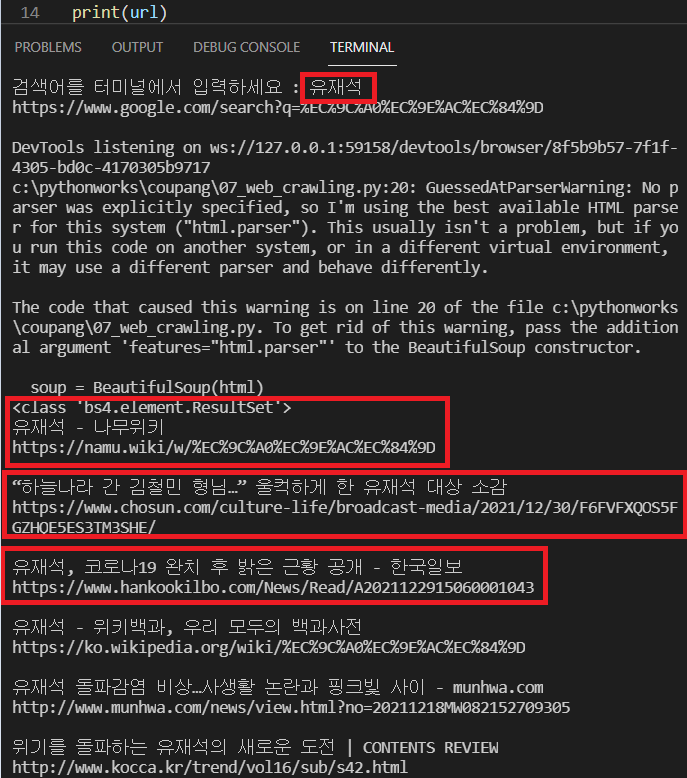
# import urllib.parse import quote_plus import urllib.parse from bs4 import BeautifulSoup from selenium import webdriver import time baseurl = ‘https://www.google.com/search?q=’ pluseurl = input(‘검색어를 터미널에서 입력하세요 : ‘) url = baseurl + urllib.parse.quote_plus(pluseurl) print(url) driver = webdriver.Chrome() driver.get(url) html = driver.page_source soup = BeautifulSoup(html) r = soup.select(‘.tF2Cxc’) #원하는 class / name을 F12에서 찾기 # select 는 list로 가져온다. #클래스는 앞에 . 점 붙여준다. print(type(r)) for i in r : print(i.select_one(‘.LC20lb.MBeuO.DKV0Md’).text) #제목 #select one을 사용하면 텍스트를 가져올 수 있다. #클래스에 빈칸은 점으로 바꿔준다. print(i.a.attrs[‘href’]) #링크 #a 태그 안에, href 를 속성을 갖는 링크 불루직 print() driver.close() #크롬 드라이버 닫아주기
결과를 보면 아래와 같이 나오죠?
내용이 도움이 되셨다면 구독 과 아래 허니게인도 확인해 보세요~
아주아주 작지만 도움이 되셨다면 같이 추천인 링크로 꼬옥 오셔요.
((추천인이 $5를 받는 건 아니니니 꼭 본인 혜택을 위해서 눌러서 해보세요. )
https://r.honeygain.money/OLIVE47A16
반응형
So you have finished reading the 구글 검색 결과 크롤링 topic article, if you find this article useful, please share it. Thank you very much. See more: 구글 검색 결과 크롤링, 파이썬, 구글 크롤링, 구글 크롤링 차단, 구글 크롤링 요청, 구글 크롤링 프로그램, 구글 검색결과 변경, 셀레니움 구글 검색, 구글 스칼라 크롤링