
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me pca 파이썬 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://chewathai27.com/to team, along with other related topics such as: pca 파이썬 Python PCA 구현, 파이썬 PCA 시각화, PCA(n_components), PCA n_components 의미, Scikit-learn PCA, PCA 예제, PCA 해석, 파이썬 이미지 PCA
Table of Contents
PCA(주성분 분석)_Python(파이썬) 코드 포함 : 네이버 블로그
- Article author: m.blog.naver.com
- Reviews from users: 27633
 Ratings
Ratings - Top rated: 4.9
- Lowest rated: 1
- Summary of article content: Articles about PCA(주성분 분석)_Python(파이썬) 코드 포함 : 네이버 블로그 PCA(주성분 분석)_Python(파이썬) 코드 포함 … PCA는 단순히 주성분 분석이라기보다는 주성분이 될 수 있는 형태로 내가 가지고 있는 기존 데이터에 … …
- Most searched keywords: Whether you are looking for PCA(주성분 분석)_Python(파이썬) 코드 포함 : 네이버 블로그 PCA(주성분 분석)_Python(파이썬) 코드 포함 … PCA는 단순히 주성분 분석이라기보다는 주성분이 될 수 있는 형태로 내가 가지고 있는 기존 데이터에 …
- Table of Contents:
카테고리 이동
딥상어동의 딥한 생각
이 블로그
머신러닝 딥러닝
카테고리 글
카테고리
이 블로그
머신러닝 딥러닝
카테고리 글
3.5 PCA — 데이터 사이언스 스쿨
- Article author: datascienceschool.net
- Reviews from users: 42143 Ratings
- Top rated: 3.1
- Lowest rated: 1
- Summary of article content: Articles about 3.5 PCA — 데이터 사이언스 스쿨 PCA(Principal Component Analysis)는 주성분 분석이라고도 하며 고차원 데이터 집합이 주어졌을 때 원래의 고차원 데이터와 가장 비슷하면서 더 낮은 차원 데이터를 … …
- Most searched keywords: Whether you are looking for 3.5 PCA — 데이터 사이언스 스쿨 PCA(Principal Component Analysis)는 주성분 분석이라고도 하며 고차원 데이터 집합이 주어졌을 때 원래의 고차원 데이터와 가장 비슷하면서 더 낮은 차원 데이터를 …
- Table of Contents:
붓꽃 데이터의 차원축소¶
차원축소와 투영¶
PCA의 수학적 설명¶
사이킷런의 PCA 기능¶
이미지 PCA¶
주식 가격의 PCA¶
[머신러닝] 실습으로 보는 PCA(주성분 분석)가 필요한 이유
- Article author: chancoding.tistory.com
- Reviews from users: 24523 Ratings
- Top rated: 4.9
- Lowest rated: 1
- Summary of article content: Articles about [머신러닝] 실습으로 보는 PCA(주성분 분석)가 필요한 이유 실습으로 알아보는 PCA의 필요성 scikit-learn의 IRIS 데이터와 PCA library를 활용해서 … 파이썬 데이터 분석, 머신러닝 등을 공부하는 사람이라면 …
- Most searched keywords: Whether you are looking for [머신러닝] 실습으로 보는 PCA(주성분 분석)가 필요한 이유 실습으로 알아보는 PCA의 필요성 scikit-learn의 IRIS 데이터와 PCA library를 활용해서 … 파이썬 데이터 분석, 머신러닝 등을 공부하는 사람이라면 실습으로 알아보는 PCA의 필요성 scikit-learn의 IRIS 데이터와 PCA library를 활용해서 PCA실습을 진행하고 왜 PCA가 필요한지 알아보도록 하겠습니다. PCA에 대한 기본 개념의 아래 글을 참고해주세요. 2020/03/..
- Table of Contents:
차밍이
[머신러닝] 실습으로 보는 PCA(주성분 분석)가 필요한 이유 본문PCA(주성분 분석 Principal Component Analysis)
LogisticRegression 적용
티스토리툴바
![[머신러닝] 실습으로 보는 PCA(주성분 분석)가 필요한 이유](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fb1pMOi%2FbtqCn1oUQew%2FZQG46SsR2wptajKi7xCvP0%2Fimg.png)
[Sklearn] 파이썬 사이킷런 PCA 구현 및 시각화 예제
- Article author: jimmy-ai.tistory.com
- Reviews from users: 23284 Ratings
- Top rated: 4.9
- Lowest rated: 1
- Summary of article content: Articles about [Sklearn] 파이썬 사이킷런 PCA 구현 및 시각화 예제 Python PCA(주성분 분석) 차원 축소 실습 코드 안녕하세요. 이번 시간에는 파이썬의 사이킷런 라이브러리를 활용하여 대표적인 차원 축소 기법인 … …
- Most searched keywords: Whether you are looking for [Sklearn] 파이썬 사이킷런 PCA 구현 및 시각화 예제 Python PCA(주성분 분석) 차원 축소 실습 코드 안녕하세요. 이번 시간에는 파이썬의 사이킷런 라이브러리를 활용하여 대표적인 차원 축소 기법인 … Python PCA(주성분 분석) 차원 축소 실습 코드 안녕하세요. 이번 시간에는 파이썬의 사이킷런 라이브러리를 활용하여 대표적인 차원 축소 기법인 주성분 분석(PCA)을 구현해보고 설명력 결과 해석 및 시각화를 해..
- Table of Contents:
Python PCA(주성분 분석) 차원 축소 실습 코드
티스토리툴바
![[Sklearn] 파이썬 사이킷런 PCA 구현 및 시각화 예제](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FDnYcF%2Fbtrs59XfQKF%2Fwk32M8XfkekFWW1gNWe0O1%2Fimg.png)
[Python] – PCA(주성분분석) 실습
- Article author: todayisbetterthanyesterday.tistory.com
- Reviews from users: 42506 Ratings
- Top rated: 3.6
- Lowest rated: 1
- Summary of article content: Articles about [Python] – PCA(주성분분석) 실습 [Python] – PCA(주성분분석) 실습. SuHawn 2020. 6. 30. 19:05. PCA는 Principal component analysis의 약자로 차원의 저주를 해결하기 위한 방법 중 하나이다. …
- Most searched keywords: Whether you are looking for [Python] – PCA(주성분분석) 실습 [Python] – PCA(주성분분석) 실습. SuHawn 2020. 6. 30. 19:05. PCA는 Principal component analysis의 약자로 차원의 저주를 해결하기 위한 방법 중 하나이다. PCA는 Principal component analysis의 약자로 차원의 저주를 해결하기 위한 방법 중 하나이다. 많은 변수들 사이에서 수학적인 연산을 통해 PC score를 얻어내고, 높은 PC score를 기반으로 LogisticRegression..ML/DL 을 공부하고, ADP를 취득하기 위한 학부생의 공부노트입니다.
- Table of Contents:
![[Python] - PCA(주성분분석) 실습](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FIfVdt%2FbtqFfXwxmEx%2FOyEYq7fo3PBeR3FD96yxek%2Fimg.png)
데이터 분석을 위한 통계(PCA – 주성분분석) feat.python
- Article author: alex-blog.tistory.com
- Reviews from users: 2862 Ratings
- Top rated: 3.7
- Lowest rated: 1
- Summary of article content: Articles about 데이터 분석을 위한 통계(PCA – 주성분분석) feat.python Statistic. 데이터 분석을 위한 통계(PCA – 주성분분석) feat.python. Alex, Yoon … …
- Most searched keywords: Whether you are looking for 데이터 분석을 위한 통계(PCA – 주성분분석) feat.python Statistic. 데이터 분석을 위한 통계(PCA – 주성분분석) feat.python. Alex, Yoon … 쉽게쉽게 떠올리자. ‘주성분 분석’ 주성분분석하면 생각해야할 용어들. 공분산 행렬, 벡터 등 여러가지들이 있습니다. 하지만 이것들은 주성분분석을 이해하고 떠올리는데 아무런 도움을 주지 않으므로 나름대로..
- Table of Contents:
데이터 분석을 위한 통계(PCA – 주성분분석) featpython 본문
티스토리툴바

sklearn.decomposition.PCA — scikit-learn 1.1.1 documentation
- Article author: scikit-learn.org
- Reviews from users: 40975 Ratings
- Top rated: 4.7
- Lowest rated: 1
- Summary of article content: Articles about sklearn.decomposition.PCA — scikit-learn 1.1.1 documentation Principal component analysis (PCA). Linear dimensionality reduction using Singular Value Decomposition of the data to project it to a lower dimensional … …
- Most searched keywords: Whether you are looking for sklearn.decomposition.PCA — scikit-learn 1.1.1 documentation Principal component analysis (PCA). Linear dimensionality reduction using Singular Value Decomposition of the data to project it to a lower dimensional …
- Table of Contents:

강의 99-02 차원 축소 (PCA 구현) – 토닥토닥 파이썬 – 머신 러닝 추가내용
- Article author: wikidocs.net
- Reviews from users: 37422 Ratings
- Top rated: 3.2
- Lowest rated: 1
- Summary of article content: Articles about 강의 99-02 차원 축소 (PCA 구현) – 토닥토닥 파이썬 – 머신 러닝 추가내용 PCA가 또 아름다운 점이 뭐냐면 선형대수 공부하는 분들이 정말 공부를 많이 해야되는 건데 너무 아름답게도 교과서에 나오게도 어넬리틱하게 풀림 x와 벡터가 있다고 … …
- Most searched keywords: Whether you are looking for 강의 99-02 차원 축소 (PCA 구현) – 토닥토닥 파이썬 – 머신 러닝 추가내용 PCA가 또 아름다운 점이 뭐냐면 선형대수 공부하는 분들이 정말 공부를 많이 해야되는 건데 너무 아름답게도 교과서에 나오게도 어넬리틱하게 풀림 x와 벡터가 있다고 … 온라인 책을 제작 공유하는 플랫폼 서비스
- Table of Contents:

See more articles in the same category here: Chewathai27.com/to/blog.
PCA(주성분 분석)_Python(파이썬) 코드 포함
PCA에 대해 공부하고 싶으면 위의 영상을 필히 보길 바란다.
나 같은 문과생들도 알기 쉽게 설명해준다.
본격적으로 들어가기 전에 한 가지 짚고 넘어갈 것이 있다.
PCA는 단순히 주성분 분석이라기보다는 주성분이 될 수 있는 형태로 내가 가지고 있는 기존 데이터에 어떤 변환을 가하는 것이다.
변환을 이해하기 위해서는 고윳값, 고유벡터, 내적, 직교 등의 선형대수학 원리에 대한 이해가 필요하다.
(관심 있으신 분은 이 영상을 꼭 보시길)
결론적으로 내가 가지고 있는 데이터에 어떤 기준에 의해서 어떤 변환이 생기게 되고 그 변환으로 인해 ‘주성분’이 추출된다.
그러므로, 이 주성분은 내가 원래 가지고 있는 데이터와 다르다. 변환된 데이터이다.
따라서, 원래 변수가 가지고 있는 의미 즉 열의 의미가 중요한 경우에는 PCA를 사용하면 안 된다.
왜냐하면, 위에서 말했듯이 PCA는 데이터에 변환을 가하는 것이기 때문이다.
3.5 PCA — 데이터 사이언스 스쿨
from sklearn.decomposition import PCA pca1 = PCA ( n_components = 1 ) X_low = pca1 . fit_transform ( X ) X2 = pca1 . inverse_transform ( X_low ) plt . figure ( figsize = ( 7 , 7 )) ax = sns . scatterplot ( 0 , 1 , data = pd . DataFrame ( X ), s = 100 , color = “.2” , marker = “s” ) for i in range ( N ): d = 0.03 if X [ i , 1 ] > X2 [ i , 1 ] else – 0.04 ax . text ( X [ i , 0 ] – 0.065 , X [ i , 1 ] + d , “표본 {} ” . format ( i + 1 )) plt . plot ([ X [ i , 0 ], X2 [ i , 0 ]], [ X [ i , 1 ], X2 [ i , 1 ]], “k–” ) plt . plot ( X2 [:, 0 ], X2 [:, 1 ], “o-” , markersize = 10 ) plt . plot ( X [:, 0 ] . mean (), X [:, 1 ] . mean (), markersize = 10 , marker = “D” ) plt . axvline ( X [:, 0 ] . mean (), c = ‘r’ ) plt . axhline ( X [:, 1 ] . mean (), c = ‘r’ ) plt . grid ( False ) plt . xlabel ( “꽃받침 길이” ) plt . ylabel ( “꽃받침 폭” ) plt . title ( “Iris 데이터의 1차원 차원축소” ) plt . axis ( “equal” ) plt . show ()
[머신러닝] 실습으로 보는 PCA(주성분 분석)가 필요한 이유
반응형
실습으로 알아보는 PCA의 필요성
scikit-learn의 IRIS 데이터와 PCA library를 활용해서 PCA실습을 진행하고 왜 PCA가 필요한지 알아보도록 하겠습니다. PCA에 대한 기본 개념의 아래 글을 참고해주세요.
2020/03/02 – [머신러닝] – [머신러닝] PCA(principal component analysis) 차원 축소에 대해
사용한 라이브러리
# 기본 데이터 분석을 위한 Library import pandas as pd import numpy as np # 시각화 Library import matplotlib.pyplot as plt import seaborn as sns’ # Sklearn에 있는 기본 데이터셋을 가져오기 위한 from sklearn import datasets # sklearn의 PCA를 통해서 쉽게 PCA 적용가능 from sklearn.decomposition import PCA # 그렇지 않으면 Matrix만들고 COV 구해서 # eigen_vector, eigen_value를 구해야하는 등 과정이 복잡해진다.
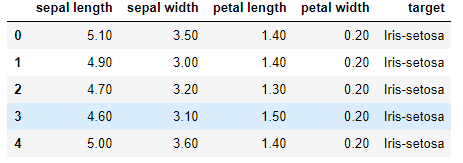
IRIS 데이터를 가져온 후 간단하게만 살펴보겠습니다. 파이썬 데이터 분석, 머신러닝 등을 공부하는 사람이라면
기본적으로 IRIS 데이터에 대해서 알고 있을 것이라고 생각합니다. 그러므로, 데이터 자체애 대한 설명은 생략하겠습니다.
데이터 살펴보기
Scatter_matrix 살펴보기
판다스의 scatter_matrix 함수를 사용해서 데이터 전체를 한 번에 시각화할 수 있습니다.
from pandas.plotting import scatter_matrix #loading dataset iris = datasets.load_iris() #creating data frame for pandas dataframe = pd.DataFrame(iris[‘data’], columns=iris[‘feature_names’]) scatter_matrix(dataframe, c=iris[‘target’],marker=’o’, s=10,alpha=.8, figsize=(12,8)) plt.show()
Featrue & Target 확인하기
독립 변수와 종속 변수를 확인한다.
독립 변수가 어느 정도 정규분포를 따르는지, 종속 변수 값들이 적절한지 확인합니다.
종속 변수가 99개와 1개 이런 식이면 PCA를 하는 의미가 없습니다.
독립 변수가 min값과 max값 쪽에 몰려있는 식으로 이분화되어있다면 이 또한 그다지 의미가 없으므로 기본적인 데이터의 상태를 확인합니다.
X = iris.data y = iris.target feature_names = iris.feature_names df_X = pd.DataFrame(X) df_Y = pd.DataFrame(y) df_Y[0].value_counts().plot(kind=’bar’) plt.show()
import seaborn as sns for i in range(df_X.shape[1]): sns.distplot(df_X[i]) plt.title(feature_names[i]) plt.show()
Target 변수는 0, 1, 2로 범주화되어있습니다. 또한, 150개가 50개씩 고르게 분포하고 있는 것을 확인할 수 있습니다.
Features 들은 정규분포에 가까운 그래프를 그려주는 것을 확인할 수 있습니다.
PCA(주성분 분석 : Principal Component Analysis)
# sklearn을 통해서 PCA 객체 생성 및 PC값을 구할 수 있습니다. pca = PCA() pca.fit(X) PC_score = pca.transform(X) PC_score[:5] >> array([[-2.68412563e+00, 3.19397247e-01, -2.79148276e-02, -2.26243707e-03], [-2.71414169e+00, -1.77001225e-01, -2.10464272e-01, -9.90265503e-02], [-2.88899057e+00, -1.44949426e-01, 1.79002563e-02, -1.99683897e-02], [-2.74534286e+00, -3.18298979e-01, 3.15593736e-02, 7.55758166e-02], [-2.72871654e+00, 3.26754513e-01, 9.00792406e-02, 6.12585926e-02]])
Transform을 통해서 아주 쉽게 PC값들을 구할 수 있습니다. array 형식으로 각 성분들의 값이 나타나는 것을 확인할 수 있습니다.
# pca의 eigen_vector pca.components_
pca를 통해 얻은 eigen_vector를 components_ 를 통해서 확인할 수 있습니다.
array([[ 0.36138659, -0.08452251, 0.85667061, 0.3582892 ], [ 0.65658877, 0.73016143, -0.17337266, -0.07548102], [-0.58202985, 0.59791083, 0.07623608, 0.54583143], [-0.31548719, 0.3197231 , 0.47983899, -0.75365743]])
PC 값의 설명력 정도
explained_variacne 를 통해서 PC값 들의 설명 정도를 확인할 수 있습니다.
pca.explained_variance_
array([4.22824171, 0.24267075, 0.0782095 , 0.02383509])
PC값이 클수록 설명력이 높습니다.
첫 번째, PC 값이 가장 크므로 가장 설명력이 높은 축일 것으로 생각할 수 있습니다.
마지막 두 개의 PC를 보면 값이 낮습니다.
마지막 값의 경우는 약 170배 정도의 설명력 차이가 나는 것을 알 수 있습니다. 즉, 거의 설명력이 없다고 생각할 수 있겠습니다. -> 그렇다고 전혀 없는 것은 아닙니다.
explained_variance를 비율로 확인할 수 있습니다.
ratio = pca.explained_variance_ratio_ ratio >> array([0.92461872, 0.05306648, 0.01710261, 0.00521218])
PC1 이 92%의 설명력을 가지고 PC4가 0.5%의 설명력을 가지고 있습니다.
df_v = pd.DataFrame(ratio, index=[‘PC1′,’PC2′,’PC3′,’PC4’], columns=[‘V_ration’]) df_v.plot.pie(y=’V_ration’) df_v
V_ration PC1 0.924619 PC2 0.053066 PC3 0.017103 PC4 0.005212
pie plot 을 통해서 설명력의 정도를 확인해 보았습니다.
PCA 분석
feature에 따른 분포 확인
X[0] , X[1] 을 통해서 IRIS 데이터를 확인해 보았습니다.
plt.figure() colors = [‘navy’, ‘turquoise’, ‘darkorange’] lw = 2 for color, i, target_name in zip(colors, [0,1,2] , iris.target_names): plt.scatter(X[y == i, 0], X[y == i, 1], color=color, alpha=.8, lw=lw, label=target_name) plt.legend(loc=’best’, shadow=False, scatterpoints=1) plt.title(‘PCA of IRIS dataset’)
PCA를 따른 데이터 분포 확인
PC1, PC2에 의한 분포를 확인해 보겠습니다.
plt.figure() colors = [‘navy’, ‘turquoise’, ‘darkorange’] lw = 2 for color, i, target_name in zip(colors, [0,1,2] , iris.target_names): plt.scatter(PC_score[y == i, 0], PC_score[y == i, 1], color=color, alpha=.8, lw=lw, label=target_name) plt.legend(loc=’best’, shadow=False, scatterpoints=1) plt.title(‘PCA of IRIS dataset’)
확실히 이전 scatter plot 보다 데이터들이 좀 더 구분이 잘 되는 것을 볼 수 있습니다.
LogisticRegression 적용
이번에는 모델을 적용해서 예측된 결과가 어느 정도 나오는지를 확인해보겠습니다. 그냥 feature와 PCscore의 차이가 어떻게 되는지 확인해보겠습니다.
from sklearn.linear_model import LogisticRegression from sklearn.metrics import confusion_matrix
4개의 feature와 4개의 PCscore를 모두 사용해서 결과를 확인해 보겠습니다.
feature 4개
clf = LogisticRegression(max_iter=1000, random_state=0, multi_class=’multinomial’) clf.fit(X,y) pred = clf.predict(X) confusion_matrix(y,pred) >> array([[50, 0, 0], [ 0, 47, 3], [ 0, 1, 49]], dtype=int64)
PC score 4개
clf.fit(PC_score,y) pred = clf.predict(PC_score) confusion_matrix(y,pred) >> array([[50, 0, 0], [ 0, 47, 3], [ 0, 1, 49]], dtype=int64)
두 값이 동일한 것을 알 수 있습니다. 모든 feature를 사용했을 때, 설명력이 동일하다고 생각할 수 있겠습니다.
이러한 경우 PCA를 왜 하는지에 대해 의문이 들 수 있습니다. 하지만 사용하는 feature의 개수가 줄어들면 확연하게 차이가 나는 것을 확인할 수 있습니다.
아래에서는 2개의 feature를 사용해서 LogisticRegression을 진행해서 비교해보겠습니다.
feature 2개
clf = LogisticRegression(max_iter=1000, random_state=0, multi_class=’multinomial’) clf.fit(X[:,:2],y) pred = clf.predict(X[:,:2]) confusion_matrix(y,pred) >> array([[50, 0, 0], [ 0, 37, 13], [ 0, 14, 36]], dtype=int64)
PC score 2개
clf2 = LogisticRegression(max_iter=1000, random_state=0, multi_class=’multinomial’) clf2.fit(PC_score[:,:2],y) pred = clf2.predict(PC_score[:,:2]) confusion_matrix(y,pred) >> array([[50, 0, 0], [ 0, 47, 3], [ 0, 2, 48]], dtype=int64)
두 결과가 확연하게 차이가 나는 것을 확인할 수 있습니다.
PC1이 상당히 많은 설명력을 가지고 있기 때문에 PC1과 PC2만으로도 대부분을 분류할 수 있습니다.
그 덕분에 model의 결과가 상당히 좋게 나온 것을 확인하였습니다.
반면 그냥 iris.data의 feature의 첫 번째와 두 번째는 그다지 설명력이 별로 좋지 못한 것을 확인할 수 있습니다. 이처럼 별 의미 없는 변수가 있을 수 있습니다. 실무에서 feature가 매우 많은 경우에는 이러한 것들을 빼고 계산하는 것이 훨씬 편하겠죠.
결론
PCA를 함으로써 성능을 높일 수 있다? 는 말은 조금 틀리다고 생각합니다. 어느 정도 성능을 유지하면서 연산 속도를 높일 수 있다고 보는 것이 옳은 것 같습니다. feature가 많을 때, 유사한 성능을 보이면서 빠르게 데이터를 분석할 수 있다.
PCA 를 적용한 모델 생성
실제 로지스틱 회귀분석 모델을 만들어서 결과를 예측해보는 과정에서 PCA를 적용하는 실습을 다음 포스팅을 통해서 진행해보겠습니다.
과연 PCA 자체로 성능을 높일 수 있는지 알아보고, 실제 train, test 데이터에 적용해보겠습니다.
[머신러닝] – [머신러닝] PCA 실습 (2) : 주성분분석이 성능을 높여주는가?참고자료
반응형
So you have finished reading the pca 파이썬 topic article, if you find this article useful, please share it. Thank you very much. See more: Python PCA 구현, 파이썬 PCA 시각화, PCA(n_components), PCA n_components 의미, Scikit-learn PCA, PCA 예제, PCA 해석, 파이썬 이미지 PCA