
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 랜덤 변수 on Google, you do not find the information you need! Here are the best content compiled and compiled by the Chewathai27.com/to team, along with other related topics such as: 랜덤 변수 랜덤변수 정의, 확률과 랜덤변수, 확률변수, 랜덤 변수 실험, 랜덤변수의 함수, 랜덤 변수 파이썬, 랜덤변수 종류, 랜덤변수 의학
Random variables(랜덤변수) & Distribution function(CDF,누적분포함수) & Density function(PDF,확률밀도함수) : 네이버 블로그
- Article author: m.blog.naver.com
- Reviews from users: 17697
 Ratings
Ratings - Top rated: 3.0
- Lowest rated: 1
- Summary of article content: Articles about Random variables(랜덤변수) & Distribution function(CDF,누적분포함수) & Density function(PDF,확률밀도함수) : 네이버 블로그 Random variables(랜덤변수, rv)란 event들을 집합이 아닌 조금 더 일반적으로 정의하기 위해 나온 개념으로써, 전체 events들의 집합인 sample sapce S를 … …
- Most searched keywords: Whether you are looking for Random variables(랜덤변수) & Distribution function(CDF,누적분포함수) & Density function(PDF,확률밀도함수) : 네이버 블로그 Random variables(랜덤변수, rv)란 event들을 집합이 아닌 조금 더 일반적으로 정의하기 위해 나온 개념으로써, 전체 events들의 집합인 sample sapce S를 …
- Table of Contents:
카테고리 이동
공대생을 위한 공부방
이 블로그
확률변수론
카테고리 글
카테고리
이 블로그
확률변수론
카테고리 글
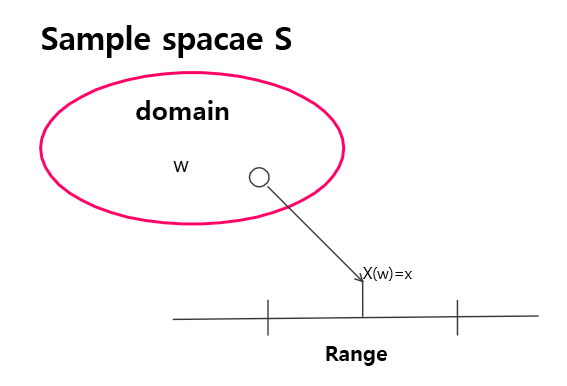
랜덤 변수
- Article author: contents.kocw.or.kr
- Reviews from users: 42123 Ratings
- Top rated: 3.9
- Lowest rated: 1
- Summary of article content: Articles about 랜덤 변수 (예) 이산랜덤변수 X의 누적분포함수가 다음과 같을 때 확률질량함수를 구하라. F. X. x … …
- Most searched keywords: Whether you are looking for 랜덤 변수 (예) 이산랜덤변수 X의 누적분포함수가 다음과 같을 때 확률질량함수를 구하라. F. X. x …
- Table of Contents:
확률 변수 – 위키백과, 우리 모두의 백과사전
- Article author: ko.wikipedia.org
- Reviews from users: 39418 Ratings
- Top rated: 3.9
- Lowest rated: 1
- Summary of article content: Articles about 확률 변수 – 위키백과, 우리 모두의 백과사전 확률론에서 확률 변수(確率變數, 영어: random variable)는 확률 공간에서 다른 가측 공간으로 가는 가측 함수이다. 시행의 결과에 따라 값이 결정되는 변수를 … …
- Most searched keywords: Whether you are looking for 확률 변수 – 위키백과, 우리 모두의 백과사전 확률론에서 확률 변수(確率變數, 영어: random variable)는 확률 공간에서 다른 가측 공간으로 가는 가측 함수이다. 시행의 결과에 따라 값이 결정되는 변수를 …
- Table of Contents:
정의[편집]
예[편집]
각주[편집]
참고 문헌[편집]
외부 링크[편집]

RV
- Article author: www.ktword.co.kr
- Reviews from users: 49364 Ratings
- Top rated: 3.1
- Lowest rated: 1
- Summary of article content: Articles about RV Discrete Random Variable, 이산 확률변수, Continuous Random Variable, … Top ▷ 기초과학 ▷ 수학 ▷ 확률/통계 ▷ 확률 과정 ▷ 랜덤과정 용어 … …
- Most searched keywords: Whether you are looking for RV Discrete Random Variable, 이산 확률변수, Continuous Random Variable, … Top ▷ 기초과학 ▷ 수학 ▷ 확률/통계 ▷ 확률 과정 ▷ 랜덤과정 용어 …
- Table of Contents:
랜덤변수의 함수와 샘플링 – 1
- Article author: pasus.tistory.com
- Reviews from users: 24136 Ratings
- Top rated: 5.0
- Lowest rated: 1
- Summary of article content: Articles about 랜덤변수의 함수와 샘플링 – 1 Y 가 랜덤변수(random variable) X 의 함수 Y = g ( X ) 로 주어진다면 Y 도 랜덤변수가 된다. X 의 누적분포함수 F X ( x ) 와 확률밀도함수 p X ( x ) … …
- Most searched keywords: Whether you are looking for 랜덤변수의 함수와 샘플링 – 1 Y 가 랜덤변수(random variable) X 의 함수 Y = g ( X ) 로 주어진다면 Y 도 랜덤변수가 된다. X 의 누적분포함수 F X ( x ) 와 확률밀도함수 p X ( x ) … \(Y\)가 랜덤변수(random variable) \(X\)의 함수 \(Y=g(X)\)로 주어진다면 \(Y\)도 랜덤변수가 된다. \(X\)의 누적분포함수 \(F_X (x) \)와 확률밀도함수 \(p_X (x) \)로부터 \(F_Y (y) \)와 \(p_Y (y) \)를 구해..
- Table of Contents:
태그
관련글
댓글0
전체 방문자
티스토리툴바

[확률 및 랜덤변수] 2. Random Variables
- Article author: jehunseo.tistory.com
- Reviews from users: 14490 Ratings
- Top rated: 3.8
- Lowest rated: 1
- Summary of article content: Articles about [확률 및 랜덤변수] 2. Random Variables 랜덤 변수 : sample space S의 원소를 실수평면에 연결할 수 있도록 하는 함수. ex. 동전 던지기 – head를 1로, tail을 2로 정의한다. …
- Most searched keywords: Whether you are looking for [확률 및 랜덤변수] 2. Random Variables 랜덤 변수 : sample space S의 원소를 실수평면에 연결할 수 있도록 하는 함수. ex. 동전 던지기 – head를 1로, tail을 2로 정의한다. 0. Notation 0. Notation 랜덤변수는 대문자로 표기 ex) W, X, Y, Z, …. 랜덤 변수의 값은 소문자로 표기 ex) w, x, y, z… 1. Definition 랜덤 변수 : sample space S의 원소를 실수평면에 연..Today I Learned…
- Table of Contents:
binomial distribution(이항분포)
Uniform Distribution
Exponential Distribution
Rayleigh Distribution
Conditional Distribution
티스토리툴바
![[확률 및 랜덤변수] 2. Random Variables](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FwaLmP%2FbtqCPBb2gQj%2FOGkz9nxoJXkufRM6aSwAVK%2Fimg.png)
12. 연속 랜덤 변수 (Continuous Random Variables)
- Article author: skyil.tistory.com
- Reviews from users: 38676 Ratings
- Top rated: 4.0
- Lowest rated: 1
- Summary of article content: Articles about 12. 연속 랜덤 변수 (Continuous Random Variables) 확률 밀도 함수 (Probability Density Function: PDF). 이산 랜덤 변수의 PMF와 같은 함수. fX … …
- Most searched keywords: Whether you are looking for 12. 연속 랜덤 변수 (Continuous Random Variables) 확률 밀도 함수 (Probability Density Function: PDF). 이산 랜덤 변수의 PMF와 같은 함수. fX … 연속 랜덤 변수는 적절한 구간 내의 모든 값을 취하는 랜덤 변수이다. 예를들어, 이 블로그에 5월 20일에 방문한 사람의 수는 이산 랜덤 변수이지만, 이 블로그에서 사람들이 머무른 평균 시간은 연속 랜덤 변수이..
- Table of Contents:
누적 분포 함수 (Cumulative Distribution Function CDF)
확률 밀도 함수 (Probability Density Function PDF)
연속 랜덤 변수의 확률
연속 랜덤 변수의 기댓값 분산 (Expected Value Variance)
연속 랜덤 변수의 성질
댓글
이 글 공유하기
다른 글
14 가우시안 랜덤 변수 (Gaussian Random Variable)
13 연속 랜덤 변수의 종류 (Families of Continuous Random Variables)
11 랜덤 변수의 분산과 표준편차 (Variance and Standard Deviation of Random Variable)
10 유도된 랜덤 변수 (Derived Random Variable)
티스토리툴바

[기초통계] 확률변수(random variable)의 개념, 의미 – 로스카츠의 AI 머신러닝
- Article author: losskatsu.github.io
- Reviews from users: 15200 Ratings
- Top rated: 4.3
- Lowest rated: 1
- Summary of article content: Articles about [기초통계] 확률변수(random variable)의 개념, 의미 – 로스카츠의 AI 머신러닝 확률변수의 정의. 확률변수(random variable)란, 확률현상에 기인해 결과값이 확률적으로 정해지는 변수를 의미한다. 확률 … …
- Most searched keywords: Whether you are looking for [기초통계] 확률변수(random variable)의 개념, 의미 – 로스카츠의 AI 머신러닝 확률변수의 정의. 확률변수(random variable)란, 확률현상에 기인해 결과값이 확률적으로 정해지는 변수를 의미한다. 확률 … 확률변수(random variable)의 개념, 의미
- Table of Contents:
확률변수의 정의
확률현상이란
확률변수의 개념
확률변수의 간단한 예제
정리
[리눅스] 우분투 하드 디스크 추가 마운트 하기 [이미지처리] 파이썬 opencv 설치 및 hello world [Infra] 쿠버네티스(kubernetes)(6) The connection to the server localhost8080 was refused [리액트react] 로그인 페이지 만들기See more articles in the same category here: https://chewathai27.com/to/blog.
위키백과, 우리 모두의 백과사전
확률론에서 확률 변수(確率變數, 영어: random variable)는 확률 공간에서 다른 가측 공간으로 가는 가측 함수이다.[1] 시행의 결과에 따라 값이 결정되는 변수를 나타낸다.[2] 가측 함수 조건은 확률 변수가 공역이 되는 가측 공간 위에 새로운 확률 측도를 유도할 수 있도록 하기 위해 필요하다. 이 확률 측도는 흔히 확률 분포라고 부른다.
확률 변수는 아직 실제로 나타나지는 않았지만 나타날 가능성이 있는 모든 경우의 수에 해당하는 값을 가질 수 있다. 주사위를 굴리는 등 실제로 무작위적인 시행에 대해서도 쓸 수 있고, 양자역학처럼 예측 불가능한 물리적 변수의 시행 결과에 대해서도 확률 변수라는 단어를 사용한다. 이처럼 정확히 알지 못하는 어떤 양적 변수의 잠재적인 결과에 대해 확률이라는 단어를 쓸 수 있는가에 대한 논의도 오랜 시간동안 이루어져왔다.
정의 [ 편집 ]
확률 공간 ( Ω , F , Pr ) {\displaystyle (\Omega ,{\mathcal {F}},\Pr )} 위의, 가측 공간 ( E , E ) {\displaystyle (E,{\mathcal {E}})} 의 값을 가지는 확률 변수는 가측 함수 X : ( Ω , F ) → ( E , E ) {\displaystyle X\colon (\Omega ,{\mathcal {F}})\to (E,{\mathcal {E}})} 를 뜻한다. (즉, 임의의 가측 집합 S ∈ E {\displaystyle S\in {\mathcal {E}}} 에 대하여, 사건 X − 1 ( S ) ∈ F {\displaystyle X^{-1}(S)\in {\mathcal {F}}} 및 그 확률을 생각할 수 있다.) 확률론에서는 측도론의 용어를 다음과 같이 대체한다.
확률 변수의 정의역 ( Ω , F , Pr ) {\displaystyle (\Omega ,{\mathcal {F}},\Pr )} 확률 공간 이다.
이다. 확률 변수의 공역 ( E , E ) {\displaystyle (E,{\mathcal {E}})} 상태 공간(狀態空間, 영어: state space )이다.
확률 변수 X : Ω → E {\displaystyle X\colon \Omega \to E} 는 그 상태 공간 E {\displaystyle E} 위에 다음과 같은 확률 측도 Pr ( X ∈ ⋅ ) {\displaystyle \Pr(X\in \cdot )} 를 유도한다.
Pr ( X ∈ S ) = Pr ( X − 1 ( S ) ) ∀ S ∈ E {\displaystyle \Pr(X\in S)=\Pr(X^{-1}(S))\qquad \forall S\in {\mathcal {E}}}
이는 확률 변수 X {\displaystyle X} 가 S {\displaystyle S} 속의 값을 가질 확률이라고 한다. 여기서
X − 1 ( S ) = { ω ∈ Ω : X ( ω ) ∈ S } {\displaystyle X^{-1}(S)=\{\omega \in \Omega \colon X(\omega )\in S\}}
이다.
만약 상태 공간이 위상 공간인 경우, 상태 공간은 통상적으로 보렐 시그마 대수를 사용한다. 예를 들어, 실수 값을 갖는 확률 변수는 실수의 보렐 시그마 대수에 대한 가측 함수이다. (반면, 보렐 시그마 대수 대신 르베그 가측 집합의 시그마 대수를 사용하면, 연속 함수이지만 가측 함수가 아닌 함수들이 존재하게 된다.) 만약 정의역이 이산 확률 공간(즉, 모든 부분 집합이 사건인 확률 공간)일 경우, 모든 함수 Ω → E {\displaystyle \Omega \to E} 는 가측 함수이며, 따라서 정의에서 가측성 조건을 생략할 수 있다.
예 [ 편집 ]
예1 [ 편집 ]
주사위를 던져 나오는 눈의 수를 추상화한 확률 공간
( Ω , F , Pr ) {\displaystyle (\Omega ,{\mathcal {F}},\operatorname {Pr} )} Ω = { 1 , 2 , … , 6 } {\displaystyle \Omega =\{1,2,\dots ,6\}} F = P ( { 1 , 2 , … , 6 } ) {\displaystyle {\mathcal {F}}={\mathcal {P}}(\{1,2,\dots ,6\})} Pr ( { 1 } ) = Pr ( { 2 } ) = Pr ( { 3 } ) = Pr ( { 4 } ) = Pr ( { 5 } ) = Pr ( { 6 } ) = 1 / 6 {\displaystyle \operatorname {Pr} (\{1\})=\operatorname {Pr} (\{2\})=\operatorname {Pr} (\{3\})=\operatorname {Pr} (\{4\})=\operatorname {Pr} (\{5\})=\operatorname {Pr} (\{6\})=1/6}
을 생각하자. 즉, 1부터 6까지의 수가 나올 수 있으며, 각각의 수가 나올 확률은 같다. 이 확률 공간 위에 다음과 같은 확률 변수를 정의하자.
X : 2 , 4 , 6 ↦ 0 {\displaystyle X\colon 2,4,6\mapsto 0} X : 1 , 3 , 5 ↦ 1 {\displaystyle X\colon 1,3,5\mapsto 1}
즉, X {\displaystyle X} 는 짝수가 나왔을 경우 0, 홀수가 나왔을 경우 1을 취한다. 그렇다면 주사위를 던져 짝수가 나올 확률은 다음과 같다.
Pr ( X = 0 ) = Pr ( { 2 , 4 , 6 } ) = 1 / 2 {\displaystyle \operatorname {Pr} (X=0)=\operatorname {Pr} (\{2,4,6\})=1/2}
마찬가지로, 홀수가 나올 확률은 다음과 같다.
Pr ( X = 1 ) = Pr ( { 1 , 3 , 5 } ) = 1 / 2 {\displaystyle \operatorname {Pr} (X=1)=\operatorname {Pr} (\{1,3,5\})=1/2}
예2 [ 편집 ]
두 개의 주사위를 던진 결과의 확률 공간
( Ω × Ω , F × F , Pr × Pr ) {\displaystyle (\Omega \times \Omega ,{\mathcal {F}}\times {\mathcal {F}},\operatorname {Pr} \times \operatorname {Pr} )}
을 생각하자. 즉, 두 주사위의 눈의 수는 서로 독립이다. 두 눈의 수의 합을 나타내는 확률 변수
Y : ( i , j ) ↦ i + j {\displaystyle Y\colon (i,j)\mapsto i+j}
의 확률 분포는 다음과 같다.
Pr ( Y = 2 ) = Pr ( { ( 1 , 1 ) } ) = 1 / 36 {\displaystyle \operatorname {Pr} (Y=2)=\operatorname {Pr} (\{(1,1)\})=1/36} Pr ( Y = 3 ) = Pr ( { ( 1 , 2 ) , ( 2 , 1 ) } ) = 1 / 18 {\displaystyle \operatorname {Pr} (Y=3)=\operatorname {Pr} (\{(1,2),(2,1)\})=1/18} Pr ( Y = 4 ) = Pr ( { ( 1 , 3 ) , ( 2 , 2 ) , ( 3 , 1 ) } ) = 1 / 12 {\displaystyle \operatorname {Pr} (Y=4)=\operatorname {Pr} (\{(1,3),(2,2),(3,1)\})=1/12} Pr ( Y = 5 ) = Pr ( { ( 1 , 4 ) , ( 2 , 3 ) , ( 3 , 2 ) , ( 4 , 1 ) } ) = 1 / 9 {\displaystyle \operatorname {Pr} (Y=5)=\operatorname {Pr} (\{(1,4),(2,3),(3,2),(4,1)\})=1/9} Pr ( Y = 6 ) = Pr ( { ( 1 , 5 ) , ( 2 , 4 ) , ( 3 , 3 ) , ( 4 , 2 ) , ( 5 , 1 ) } ) = 5 / 36 {\displaystyle \operatorname {Pr} (Y=6)=\operatorname {Pr} (\{(1,5),(2,4),(3,3),(4,2),(5,1)\})=5/36} Pr ( Y = 7 ) = Pr ( { ( 1 , 6 ) , ( 2 , 5 ) , ( 3 , 4 ) , ( 4 , 3 ) , ( 5 , 2 ) , ( 6 , 1 ) } ) = 1 / 6 {\displaystyle \operatorname {Pr} (Y=7)=\operatorname {Pr} (\{(1,6),(2,5),(3,4),(4,3),(5,2),(6,1)\})=1/6} Pr ( Y = 8 ) = Pr ( { ( 2 , 6 ) , ( 3 , 5 ) , ( 4 , 4 ) , ( 5 , 3 ) , ( 6 , 2 ) } ) = 5 / 36 {\displaystyle \operatorname {Pr} (Y=8)=\operatorname {Pr} (\{(2,6),(3,5),(4,4),(5,3),(6,2)\})=5/36} Pr ( Y = 9 ) = Pr ( { ( 3 , 6 ) , ( 4 , 5 ) , ( 5 , 4 ) , ( 6 , 3 ) } ) = 1 / 9 {\displaystyle \operatorname {Pr} (Y=9)=\operatorname {Pr} (\{(3,6),(4,5),(5,4),(6,3)\})=1/9} Pr ( Y = 10 ) = Pr ( { ( 4 , 6 ) , ( 5 , 5 ) , ( 6 , 4 ) } ) = 1 / 12 {\displaystyle \operatorname {Pr} (Y=10)=\operatorname {Pr} (\{(4,6),(5,5),(6,4)\})=1/12} Pr ( Y = 11 ) = Pr ( { ( 5 , 6 ) , ( 6 , 5 ) } ) = 1 / 18 {\displaystyle \operatorname {Pr} (Y=11)=\operatorname {Pr} (\{(5,6),(6,5)\})=1/18} Pr ( Y = 12 ) = Pr ( { ( 6 , 6 ) } ) = 1 / 36 {\displaystyle \operatorname {Pr} (Y=12)=\operatorname {Pr} (\{(6,6)\})=1/36}
각주 [ 편집 ]
참고 문헌 [ 편집 ]
Doob, Joseph L. (1996년 8월). “The development of rigor in mathematical probability (1900–1950)”. 《The American Mathematical Monthly》 (영어) 103 (7). doi:10.2307/2974673. ISSN 0002-9890. JSTOR 2974673. MR 1404084. Zbl 0865.01011.
Kersting, Götz; Wakolbinger, Anton (2014). 《Zufallsvariable und Stochastische Prozesse》 (독일어). Birkhäuser. ISBN 978-3-7643-8432-6 .
Fahrmeir, Ludwig; Künstler, Rita; Pigeot, Iris; Tutz, Gerhard (2012). 《Statistik: Der Weg zur Datenanalyse》 (독일어) Auflage 7판. Springer. ISBN 978-3-6420-1938-8 .
Papula, Lothar (2011). 《Mathematik für Ingenieure und Naturwissenschaftler Band 3》 (독일어) Auflage 6판. Vieweg+Teubner Verlag. ISBN 978-3-8348-1227-8 .
랜덤변수의 함수와 샘플링 – 1
\(Y\)가 랜덤변수(random variable) \(X\)의 함수 \(Y=g(X)\)로 주어진다면 \(Y\)도 랜덤변수가 된다. \(X\)의 누적분포함수 \(F_X (x) \)와 확률밀도함수 \(p_X (x) \)로부터 \(F_Y (y) \)와 \(p_Y (y) \)를 구해보자.
사건 \( \{ Y \le y \} \)의 확률은 랜덤변수 \(X\)가 \( g(X) \le y \)를 만족하는 실수 구간 \( \{ X \in I_x \} \)에 속할 확률과 같으므로 \(Y\)의 누적분포함수는 다음 식으로 계산할 수 있다.
\[ \begin{align} F_Y (y) & = P \{ Y \le y \} \\ \\ &= P \{ g(X) \le y \} \\ \\ &= P \{ X \le g^{-1} (y) \} \\ \\ &= P \{ X \in I_x \} \end{align} \]
예를 들어서 다음과 같은 랜덤변수 \(X\)와 \(Y\)의 함수 관계가 있다고 가정하자.
\[ Y=2X+3 \]
그러면 \(Y\)의 누적분포함수는 다음과 같이 계산할 수 있다.
\[ \begin{align} F_Y (y) & = P \{ Y \le y \} \\ \\ &= P \{ 2X+3 \le y \} \\ \\ &= P \{ X \le \frac{1}{2}(y-3) \} \\ \\ &= F_X \left( \frac{y-3}{2} \right) \end{align} \]
만약 \(X\)가 \( [0,1] \) 구간에서 균등분포(uniform distribution)을 갖는다면, 즉 \( X \sim U[0,1] \)이라면
\[ p_X (x) = \begin{cases} 1, & 0 \le x \le 1 \\ 0, & others \end{cases} \]
\(Y\)의 확률밀도함수는 다음과 같이 계산할 수 있다.
\[ \begin{align} p_Y (y) & = \frac{dF_Y (y)}{dy} \\ \\ &= \frac{d}{dy} \left[ F_X \left( \frac{y-3}{2} \right) \right] \\ \\ &= \frac{1}{2} p_X \left( \frac{y-3}{2} \right) \\ \\ &= \begin{cases} \frac{1}{2}, & 3 \le y \le 5 \\ 0, & others \end{cases} \end{align} \]
다른 예를 들어보자. 이번에는 다음과 같은 함수 관계가 있다고 가정하자.
\[ Y=g(X) = \begin{cases} \sqrt{2X}, & 0 \le X \lt \frac{1}{2} \\ 2-\sqrt{2(1-X)}, & \frac{1}{2} \le X \le 1 \\ 0, & others \end{cases} \]
그러면 \(Y\)의 누적분포함수는 다음과 같다.
\[ \begin{align} F_Y (y) & = P\{ Y \le y \} \\ \\ &= P \{ g(X) \le y \} \\ \\ &= P \{ X \le g^{-1} (y) \} \\ \\ &= P \begin{cases} X \le \frac{y^2}{2}, & 0 \le y \lt 1 \\ X \le 1- \frac{1}{2} (2-y)^2, & 1 \le y \le 2 \\ X \le 0, & others \end{cases} \\ \\ &= \begin{cases} F_X \left( \frac{y^2}{2} \right) , & 0 \le y \lt 1 \\ F_X \left( 1-\frac{1}{2} (2-y)^2 \right), & 1 \le y \le 2 \\ 0, & others \end{cases} \end{align} \]
따라서 \(Y\)의 확률밀도함수는 다음과 같이 계산할 수 있다.
\[ \begin{align} p_Y (y) & = \frac{dF_Y (y)}{dy} \\ \\ &= \begin{cases} \frac{d}{dy} \left[ F_X \left(\frac{y^2}{2} \right) \right], & 0 \le y \lt 1 \\ \frac{d}{dy} \left[ F_X \left( 1- \frac{1}{2} (2-y)^2 \right) \right], & 1 \le y \le 2 \\ 0, & others \end{cases} \\ \\ &= \begin{cases} y \ p_X \left( \frac{y^2}{2} \right) , & 0 \le y \lt 1 \\ (2-y) \ p_X \left( 1-\frac{1}{2} (2-y)^2 \right), & 1 \le y \le 2 \\ 0, & others \end{cases} \end{align} \]
만약 \(X\)가 \( [0,1] \) 구간에서 균등분포(uniform distribution)을 갖는다면,
\[ p_Y (y) = \begin{cases} y , & 0 \le y \lt 1 \\ (2-y), & 1 \le y \le 2 \\ 0, & others \end{cases} \]
이 된다.
어떤 확률분포를 가진 랜덤변수에서 데이터를 생성하는 과정을 샘플링(sampling)이라고 한다. 파이썬(Python)이나 매트랩(Matlab)에는 가우시안 확률분포나 균등 확률분포를 갖는 랜덤변수에서 샘플을 추출할 수 있는 함수를 제공한다. 그렇다면 임의의 확률분포에서는 어떻게 샘플링 할 수 있을까.
랜덤변수 \(Y\)의 확률분포를 알고 있지만 샘플을 직접 추출하기 어려운 경우에는 균등 확률분포를 갖는 랜덤변수 \(X\)로부터 추출한 샘플 \( X=x^{(i)} \)을 함수 관계식 \(y^{(i)}=g(x^{(i)}) \)로 변환해서 \(Y\)로부터 추출한 샘플 \(Y=y^{(i)} \)로 간주하면 된다.
예를 들어서, 균등 확률분포를 갖는 \(X\)로부터 추출한 \(N\)개의 샘플 \(x^{(i)} \)로부터 다음과 같이 함수 \(y=g(x) \)를 통해 \(Y\)의 샘플 \(y^{(i)} \)를 구할 수 있다.
\[ y = g(x)= \begin{cases} \sqrt{2x} , & 0 \le x \lt \frac{1}{2} \\ 2-\sqrt{2(1-x)}, & \frac{1}{2} \le x \le 1 \\ 0, & others \end{cases} \]
다음 그림은 \(100,000 \)개의 샘플 \(x^{(i)} \)와 \(y^{(i)} \)를 이용해 근사적인 확률밀도함수를 그린 것(히스토그램)이다. 해석적으로 구한 확률밀도함수와 거의 일치함을 알 수 있다.
12. 연속 랜덤 변수 (Continuous Random Variables)
연속 랜덤 변수는 적절한 구간 내의 모든 값을 취하는 랜덤 변수이다.
예를들어, 이 블로그에 5월 20일에 방문한 사람의 수는 이산 랜덤 변수이지만, 이 블로그에서 사람들이 머무른 평균 시간은 연속 랜덤 변수이다.
사람 수는 셀 수 있지만, 시간은 정확히 잴 수 없는 연속된 값이기 때문이다.
누적 분포 함수 (Cumulative Distribution Function: CDF)
임의의 값 $x$까지 랜덤 변수 $X$가 갖는 값.
$$ F_X(x) = P[X \leq x] $$
연속 랜덤 변수의 CDF는 PDF를 적분하여 구할 수 있다.
$$ F_X(x) = \int_{-\infty }^{x} f_X(u)du $$
확률 밀도 함수 (Probability Density Function: PDF)
이산 랜덤 변수의 PMF와 같은 함수.
$$ f_X(x) = \frac{dF_X(x)}{dx} $$
연속 랜덤 변수의 확률
연속 랜덤 변수에서 한 값의 확률은 한 값을 정확히 측정하기 어렵기 때문에 별 의미가 없고, 특정 구간의 확률을 구하여 사용한다.
(컵에 담긴 물이 정확히 100ml일 확률은 0에 수렴하고, 99ml ~ 101ml 사이일 확률을 구한다.)
$$ P[x_1 < X \leq x_2] = \int_{x_1}^{x_2} f_X(x)dx $$ 연속 랜덤 변수의 기댓값, 분산 (Expected Value, Variance) 연속 랜덤 변수의 기댓값은 아래와 같다. $$ E[X] = \int_{-\infty}^{\infty} xf_X(x)dx $$ 연속 랜덤 변수의 분산은 이산 랜덤 변수와 다르지 않다. $$ E[(x-\mu x)^2] = E[x^2] - (E[x])^2 $$ 연속 랜덤 변수의 성질 $$ E[X - \mu x] = 0 \\ E[aX+b] = aE[X] + b\\ Var[X] = E[X^2] - \mu ^2x \\ Var[aX+b] = a^2Var[X] $$
So you have finished reading the 랜덤 변수 topic article, if you find this article useful, please share it. Thank you very much. See more: 랜덤변수 정의, 확률과 랜덤변수, 확률변수, 랜덤 변수 실험, 랜덤변수의 함수, 랜덤 변수 파이썬, 랜덤변수 종류, 랜덤변수 의학