
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 딥 러닝 하이퍼 파라미터 튜닝 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://chewathai27.com/to team, along with other related topics such as: 딥 러닝 하이퍼 파라미터 튜닝 하이퍼파라미터 튜닝 자동화, 신경망 하이퍼파라미터, 머신러닝 하이퍼 파라미터 튜닝, 파이썬 하이퍼파라미터 튜닝, 하이퍼 파라미터 튜닝이란, 파이토치 하이퍼 파라미터 튜닝, 하이퍼파라미터 최적화, 하이퍼파라미터 튜닝 교차검증
[Deep Learning] 5. 딥러닝 하이퍼파라미터 튜닝
- Article author: daje0601.tistory.com
- Reviews from users: 12418
 Ratings
Ratings - Top rated: 4.0
- Lowest rated: 1
- Summary of article content: Articles about [Deep Learning] 5. 딥러닝 하이퍼파라미터 튜닝 오늘은 딥러닝에서 하이퍼파라미터 튜닝에 대해서 알아보고자 합니다. 본 글을 작성하기 앞에 해당 글은 아래 블로그를 참고하여 작성되었음을 사전에 … …
- Most searched keywords: Whether you are looking for [Deep Learning] 5. 딥러닝 하이퍼파라미터 튜닝 오늘은 딥러닝에서 하이퍼파라미터 튜닝에 대해서 알아보고자 합니다. 본 글을 작성하기 앞에 해당 글은 아래 블로그를 참고하여 작성되었음을 사전에 … 안녕하십니까 다제입니다. 오늘은 딥러닝에서 하이퍼파라미터 튜닝에 대해서 알아보고자 합니다. 본 글을 작성하기 앞에 해당 글은 아래 블로그를 참고하여 작성되었음을 사전에 안내드립니다. ( 참조블로그 ) 1…
- Table of Contents:
코딩일기
[Deep Learning] 5 딥러닝 하이퍼파라미터 튜닝 본문티스토리툴바
![[Deep Learning] 5. 딥러닝 하이퍼파라미터 튜닝](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FeesTaM%2Fbtq39ly7aaI%2Fip2WRhBsK7KTtawvRQ1DQK%2Fimg.jpg)
신경망 : [하이퍼 파라미터 튜닝,ETF, Keras Tuner]
- Article author: velog.io
- Reviews from users: 10483 Ratings
- Top rated: 3.5
- Lowest rated: 1
- Summary of article content: Articles about 신경망 : [하이퍼 파라미터 튜닝,ETF, Keras Tuner] 나는 현재 ai 부트캠프를 하고 있고, 현재 딥러닝 부분을 하고 있다 … 하이퍼 파라미터 튜닝은 간단하게 모델에 존재하는 많은 파라미터(사용자 … …
- Most searched keywords: Whether you are looking for 신경망 : [하이퍼 파라미터 튜닝,ETF, Keras Tuner] 나는 현재 ai 부트캠프를 하고 있고, 현재 딥러닝 부분을 하고 있다 … 하이퍼 파라미터 튜닝은 간단하게 모델에 존재하는 많은 파라미터(사용자 … 첫 게시글 🎉
비공개로 노션에다가 기록을 남기다가 이렇게 공유를 하는 블로그는 처음인 것 같다노션에서 벨로그로 오게된 이유는..
노션은 블로그의 내용이 길어지면 렉이 너무 심했다 ㅠㅠ색깔도 넣고 이쁘게 블록도 마음대로 옮길 수 있어서
꾸미기에 참 좋은 노트이자 - Table of Contents:
AI 딥러닝
👩🏻 신경망과 하이퍼파라미터 튜닝
👩🏻 실험 추적 프레임워크 (ETF)
👩🏻 Keras Tuner
![신경망 : [하이퍼 파라미터 튜닝,ETF, Keras Tuner]](https://velog.velcdn.com/images/qksekf/post/10b0dff8-bfa8-402d-bddd-4ad27cf44310/ai1.jpg)
하이퍼 파라미터 튜닝 (1)
- Article author: analysisbugs.tistory.com
- Reviews from users: 15532 Ratings
- Top rated: 3.1
- Lowest rated: 1
- Summary of article content: Articles about 하이퍼 파라미터 튜닝 (1) Deep learning 모델에서는 최적의 LR을 유동적으로 찾기 위해서, 여러가지 technique을 사용한다. 가장 대표적인 방법으로, 모델의 학습 Process 도중에 … …
- Most searched keywords: Whether you are looking for 하이퍼 파라미터 튜닝 (1) Deep learning 모델에서는 최적의 LR을 유동적으로 찾기 위해서, 여러가지 technique을 사용한다. 가장 대표적인 방법으로, 모델의 학습 Process 도중에 … 논문 : Yu, T., & Zhu, H. (2020). Hyper-parameter optimization: A review of algorithms and applications. arXiv preprint arXiv:2003.05689. 1. Contribution – Hyper-parameters are systematicall..
- Table of Contents:
태그
‘데이터 다루기머신러닝 이론’ Related Articles
[5주차] 딥러닝 2단계 : 하이퍼파라미터 튜닝 :: 다 IT지~
- Article author: sy-programmingstudy.tistory.com
- Reviews from users: 43969 Ratings
- Top rated: 4.2
- Lowest rated: 1
- Summary of article content: Articles about [5주차] 딥러닝 2단계 : 하이퍼파라미터 튜닝 :: 다 IT지~ 이 글은 edwith 딥러닝 2단계 강의 목록 중 ‘하이퍼파라미터 튜닝’을 수강하고 정리하였습니다. 수식, 그래프 이미지의 출처는 강의 필기 캡처본 … …
- Most searched keywords: Whether you are looking for [5주차] 딥러닝 2단계 : 하이퍼파라미터 튜닝 :: 다 IT지~ 이 글은 edwith 딥러닝 2단계 강의 목록 중 ‘하이퍼파라미터 튜닝’을 수강하고 정리하였습니다. 수식, 그래프 이미지의 출처는 강의 필기 캡처본 … https://www.edwith.org/deeplearningai2/joinLectures/20015 딥러닝 2단계: 심층 신경망 성능 향상시키기 강좌소개 : edwith – 커넥트재단 www.edwith.org 이 글은 edwith 딥러닝 2단계 강의 목록 중 ‘하이..공부한 것들을 기록합니다.
- Table of Contents:
튜닝 프로세스
적절한 척도 선택하기
하이퍼파라미터 튜닝 실전
TAG
관련글 관련글 더보기
인기포스트
![[5주차] 딥러닝 2단계 : 하이퍼파라미터 튜닝 :: 다 IT지~](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FlrASx%2FbtqBOroge7T%2FwqGiYn4zyW40JtgW67bnk0%2Fimg.png)
Tensorflow-1.4. 기초(5)-하이퍼 파라미터 튜닝
- Article author: gooopy.tistory.com
- Reviews from users: 16975 Ratings
- Top rated: 3.2
- Lowest rated: 1
- Summary of article content: Articles about Tensorflow-1.4. 기초(5)-하이퍼 파라미터 튜닝 머신러닝에서 하이퍼 파라미터는 그 외 연구자가 수정할 수 있는 값으로, 학습률, Optimizer, 활성화 함수, 손실 함수 등 다양한 인자들을 가리킨다. 이 … …
- Most searched keywords: Whether you are looking for Tensorflow-1.4. 기초(5)-하이퍼 파라미터 튜닝 머신러닝에서 하이퍼 파라미터는 그 외 연구자가 수정할 수 있는 값으로, 학습률, Optimizer, 활성화 함수, 손실 함수 등 다양한 인자들을 가리킨다. 이 … 이전 포스트에서 데이터 셋을 표준 정규분포로 만들어 더 쉽게 데이터셋을 모델에 학습시켜보았다. 그러나, 패턴의 단순함에 비해 여전히 정확도(Accuracy)가 원하는 수준까지 나오질 않는다. 대체 왜 그럴까?..데이터 분석을 하기 위한 전반적인 지식들을 담아놓는 곳
- Table of Contents:
Tensorflow-14 기초(5)-하이퍼 파라미터 튜닝
하이퍼 파라미터 튜닝(HyperParameter Tuning)
티스토리툴바

하이퍼파라미터 (Hyperparameter) > 도리의 디지털라이프
- Article author: blog.skby.net
- Reviews from users: 39730 Ratings
- Top rated: 4.6
- Lowest rated: 1
- Summary of article content: Articles about 하이퍼파라미터 (Hyperparameter) > 도리의 디지털라이프 이 외에도 다양한 하이퍼파라미터가 존재하고 최적의 딥러닝 모델 생성을 위해 하이퍼파라미터 튜닝 … 하이퍼파라미터 튜닝 기법 적용 시 주요 활동 … …
- Most searched keywords: Whether you are looking for 하이퍼파라미터 (Hyperparameter) > 도리의 디지털라이프 이 외에도 다양한 하이퍼파라미터가 존재하고 최적의 딥러닝 모델 생성을 위해 하이퍼파라미터 튜닝 … 하이퍼파라미터 튜닝 기법 적용 시 주요 활동 …
- Table of Contents:
도리의 디지털라이프
I 하이퍼파라미터의 개념
II 하이퍼파라미터의 종류
III 하이퍼파라미터 튜닝 기법과 활동
IV 하이퍼파라미터와 딥러닝 모델의 파라미터 비교
 Read More
Read More
2.7 모델 세부 튜닝 | 텐서 플로우 블로그 (Tensor ≈ Blog)
- Article author: tensorflow.blog
- Reviews from users: 45943 Ratings
- Top rated: 4.8
- Lowest rated: 1
- Summary of article content: Articles about 2.7 모델 세부 튜닝 | 텐서 플로우 블로그 (Tensor ≈ Blog) 이제 이 모델들을 세부 튜닝해야 합니다. 그 방법을 몇 개 살펴봅시다. 2.7.1 그리드 탐색 가장 단순한 방법은 만족할 만한 하이퍼파라미터 조합을 찾을 때까지 수동 … …
- Most searched keywords: Whether you are looking for 2.7 모델 세부 튜닝 | 텐서 플로우 블로그 (Tensor ≈ Blog) 이제 이 모델들을 세부 튜닝해야 합니다. 그 방법을 몇 개 살펴봅시다. 2.7.1 그리드 탐색 가장 단순한 방법은 만족할 만한 하이퍼파라미터 조합을 찾을 때까지 수동 … 2.6 모델 선택과 훈련 | 목차 | 2.8 론칭, 모니터링, 그리고 시스템 유지 보수 가능성 있는 모델들을 추렸다고 가정하겠습니다. 이제 이 모델들을 세부 튜닝해야 합니다. 그 방법을 몇 개 살펴봅시다. 2.7.1 그리드 탐색 가장 단순한 방법은 만족할 만한 하이퍼파라미터 조합을 찾을 때까지 수동으로 하이퍼파라미터를 조정하는 것입니다. 이는 매우 지루한 작업이고 많은 경우의 수를…
- Table of Contents:
머신러닝(Machine Learning) 딥러닝(Deep Learning) 그리고 텐서(Tensor) 또 파이썬(Python)
271 그리드 탐색
272 랜덤 탐색
273 앙상블 방법
274 최상의 모델과 오차 분석
275 테스트 세트로 시스템 평가하기

See more articles in the same category here: Chewathai27.com/to/blog.
[Deep Learning] 5. 딥러닝 하이퍼파라미터 튜닝
안녕하십니까 다제입니다.
오늘은 딥러닝에서 하이퍼파라미터 튜닝에 대해서 알아보고자 합니다.
본 글을 작성하기 앞에 해당 글은 아래 블로그를 참고하여 작성되었음을 사전에 안내드립니다. ( 참조블로그 )
1. 하이퍼파라미터 튜닝기법
종류 설명 적용 시 고려사항 학습률
(Learning Rate) gradient의 방향으로 얼마나 빠르게 이동할 것인지 결정하는 변수 – 너무 작으면 학습의 속도가 늦고, 너무 크면 학습 불가 손실 함수
(Cost Function) 입력에 따른 기대 값과 실제 값의 차이를 계산하는 함수 – 평균 제곱 오차
– 교차 엔트로피 오차 정규화 파라미터
(Regularization parameter) L1 또는 L2 정규화 방법 사용 – 사용하는 일반화 변수도 하이퍼 파라미터로 분류 미니 배치 크기
(Mini-batch Size) 배치셋 수행을 위해 전체 학습 데이터를 등분하는(나누는) 크기 – 가용 메모리 크기와 epoch 수행 성능을 고려
– 최소 사이즈 : 32 /
* 참조논문( arxiv.org/abs/1804.07612)
– 배치 크기는 GPU의 물리적인 구조로 인해 항상 2의 제곱으로 설정 훈련 조기 종료
(Early Stopping) 학습의 조기 종료를 결정하는 변수 – 학습 효율이 떨어지는 시점을 적절히 판단 은닉층의 뉴런 개수
(Hidden Unit) 훈련 데이터에 대한 학습 최적화 결정 변수 – 첫 Hidden Layer의 뉴런 수가 Input Layer 보다 큰 것이 효과적 가중치 초기화
(Weight Initialization) 학습 성능에 대한 결정 변수 – 모든 초기값이 0일 경우 모든 뉴런이 동일한 결과
이 외에도 momentum, activation functions, dropout regularization 등이 있음
그러나, 중요한 것은 각각의 특성을 알지못한다면 튜닝을 할 수 없으니 꼭 개별 개념에 대한 학습 필요
2. 하이퍼파라미터 튜닝 기법 적용 시 주요 활동
튜닝 기법주요 활동적용 방안 Manual
Search 휴리스틱 조합 – 사용자의 직관과 경험 기반 탐색 탐색의 단순성 적용 – 사용자 도출 조합 중 최적 조합 적용 Grid
Search 모든 조합 탐색 – 하이퍼파라미터 적용값 전체 탐색 시행 횟수 한계 파악 – 하이퍼파라미터 증가로 인해 전수 탐색 한계 Random
Search 랜덤 샘플링 – 범위 내 무작위 값 반복 추출 탐색 범위 부여 – 하이퍼파라미터 최소/최대값부여 Bayesian
Optimization 관측 데이터 기반 F(x) 추정 – 베이즈 정리 확용, 가우시안 프로세스 함수 생성 – 확률 추정 결과 기반 입력값 후보 추천 함수
3. 실습코드
def model_builder(hp): model = keras.Sequential() model.add(Flatten(input_shape=(28, 28))) # 첫 번째 Dense layer에서 노드 수를 조정(32-512)합니다. hp_units = hp.Int(‘units’, min_value = 32, max_value = 512, step = 32) model.add(Dense(units = hp_units, activation = ‘relu’)) model.add(Dense(10)) # Optimizer의 학습률(learning rate)을 조정[0.01, 0.001, 0.0001]합니다. hp_learning_rate = hp.Choice(‘learning_rate’, values = [1e-2, 1e-3, 1e-4]) model.compile(optimizer = keras.optimizers.Adam(learning_rate = hp_learning_rate), loss = keras.losses.SparseCategoricalCrossentropy(from_logits = True), metrics = [‘accuracy’]) return model
tuner = kt.Hyperband(model_builder, objective = ‘val_accuracy’, max_epochs = 10, factor = 3, directory = ‘my_dir’, project_name = ‘intro_to_kt’)
지금까지 하이퍼파라미터 튜닝에 대해서 학습해 보았습니다.
정말 하나하나 코드를 실행해보지 않으며, 와닿지 않더라구요
꼭 여러분께서도 하나하나 실행해보면서 어떤 역할을 하는지 언제 사용해야할지 생각해보시면 성능을 올리실 때 훨씬 도움이 되실거라 생각합니다.
도움이 되셨다면 좋아요! 버튼 부탁드립니다.
오늘도 글을 읽어주셔서 너무나도 감사드립니다.
728×90
신경망 : [하이퍼 파라미터 튜닝,ETF, Keras Tuner]
첫 게시글 🎉
비공개로 노션에다가 기록을 남기다가 이렇게 공유를 하는 블로그는 처음인 것 같다
노션에서 벨로그로 오게된 이유는..
노션은 블로그의 내용이 길어지면 렉이 너무 심했다 ㅠㅠ
색깔도 넣고 이쁘게 블록도 마음대로 옮길 수 있어서
꾸미기에 참 좋은 노트이자 블로그였으나
포트폴리오 만드는 용도로 써야할 것 같다 😂
나는 현재 ai 부트캠프를 하고 있고, 현재 딥러닝 부분을 하고 있다
그래서 강의 내용에 대해 기록을 해볼 것이고,
여태껏 notion에 적은 기록들도 앞으로 천천히 복습차 옮겨올 생각이다.
교육을 받는 입장이므로 틀린 내용이 있을 수 있으니 검색해서 들어왔다면, 이 글 이 외에도 여러 글을 서치해보길 ..
(혹시 보다가 틀린게 있다면, 댓글로 부탁해요 😎)
👩🏻 신경망과 하이퍼파라미터 튜닝
하이퍼 파라미터 튜닝은 간단하게 모델에 존재하는 많은 파라미터(사용자 지정 변수)에 대해 최적의 값을 찾아 모델의 성능을 높이는 과정이다
더 자세한 뜻을 알고 싶으면 검색이 답!(개념 설명 목적이 아니므로 총총.. )
하이퍼파라미터가 신경망에서 중요한 이유? 다른 모델의 경우 몇몇 파라미터만 손보면 되지만, 신경망에는 다른 모델에 비해 매우 많은 파라미터가 있다.(은닉층의 수, 노드의 수, optimizer, loss 등)
하이퍼 파라미터 튜닝이 모델의 정확도에 엄청난 영향을 주므로 시간이 많이 소요되더라도 최적의 파라미터 값을 찾아야 한다.
하이퍼파라미터를 튜닝한 모델의 실제 예측정확도(성능)를 아는 방법은?
답변) cv(교차검증)을 통해 정확도를 구해 최종 정확도가 실제 정확도와 비슷하도록 만들 수 있음
교차검증에 대해 잠시 알고 넘어가보자 !
🔥 교차검증(cross validation = CV)
: 데이터가 제한적일 때, 데이터 세트를 train, validation 세트로 바꿔가며 학습과 검증을 하는 방법
교차검증의 장점? 하는이유?
-> 데이터가 제한적일 때 검증할데이터 데이터를 train, validation 데이터로 교차로 써가면서 데이터를 효율적으로 쓸 수 있기 때문이다.
1. K-Fold 교차검증
: k개로 데이터를 나눈 후 k번 만큼 학습과 검증을 세트를 수행하는 것
(위 사진은 그럼 5-fold 교차검증이 된다)
<한계>
레이블이 0,1,2로 존재한다고 가정해보면, 우연히 훈련데이터 레이블에 0,1의 값만 들어가게 될 수 있다. 그럴 때 2라는 답을 도출할 수 없다는 문제가 있다.
<코드 예시>
import numpy as np import pandas as pd import os from sklearn . model_selection import KFold , StratifiedKFold import tensorflow as tf from tensorflow . keras . preprocessing . image import ImageDataGenerator ( x_train , y_train ) , ( x_test , y_test ) = boston_housing . load_data ( ) kf = KFold ( n_splits = 5 ) skf = StratifiedKFold ( n_splits = 5 , random_state = 42 , shuffle = True ) from tensorflow . keras . models import Sequential from tensorflow . keras . layers import Dense x_train = pd . DataFrame ( x_train ) y_train = pd . DataFrame ( y_train ) for train_index , val_index in kf . split ( np . zeros ( x_train . shape [ 0 ] ) , y_train ) : train_data = x_train . iloc [ train_index , : ] val_data = x_train . iloc [ val_index , : ] train_target = y_train . iloc [ train_index ] val_target = y_train . iloc [ val_index ] model = Sequential ( ) model . add ( Dense ( 64 , activation = ‘relu’ ) ) model . add ( Dense ( 64 , activation = ‘relu’ ) ) model . add ( Dense ( 1 ) ) model . compile ( loss = ‘mean_squared_error’ , optimizer = ‘adam’ ) model . fit ( train_data , train_target , epochs = 10 , batch_size = 30 , validation_data = ( val_data , val_target ) ) result = model . evaluate ( x_test , y_test , batch_size = 128 ) print ( “mse or loss:” , result )
from sklearn . model_selection import KFold , StratifiedKFold for train_index , val_index in kf . split ( np . zeros ( x_train . shape [ 0 ] ) , y_train ) : train_data = x_train . iloc [ train_index , : ] val_data = x_train . iloc [ val_index , : ] train_target = y_train . iloc [ train_index ] val_target = y_train . iloc [ val_index ]
🔥 하이퍼파라미터 튜닝 방식
1) Grad Student Descent
: 100 % 수동으로 직접 하나하나 하이퍼파라미터를 구하는 방식
2) Grid Search
: 하이퍼 파라미터 값을 직접 지정해 리스트 형태로 param_grid에 설정해 두면 그 값들의 조합을 적용해 모델의 성능을 평가해주는 방식
여러 조합보다는 하나의 조합을 찾는데 활용하는게 한다
모델을 위한 하이퍼파라미터만 제대로 튜닝한다면 원하는 성능의 90-95%는 채울 수 있다.
3) Random Search
: 탐색하는 수들을 크게크게 건너 띄어 최적의 파라미터를 탐색는 방식
grid search 보다 효율적
상대적으로 중요한 파라미터에 대한 탐색을 더한다
크게 건너띄므로 완벽한 파라미터는 찾을 수 없다
4) bayesian method
: 이전 탐색에서 얻을 결과를 추후 탐색에 반영하는 방식
케라스 튜너로 사용가능
🔥 하이퍼파라미터 튜닝 가능한 옵션
1) batch_size
: 데이터 학습 시 한번 에 몇 개의 데이터를 다루는지 결정하는 파라미터
너무 클 경우 , 가중치업데이트 시 모든 데이터의 loss를 계산해야 하는 문제점과 메모리 문제
, 가중치업데이트 시 모든 데이터의 loss를 계산해야 하는 문제점과 메모리 문제 너무 작은 경우, 데이터가 잘게 쪼개져 학습하는데 오랜시간이 걸리며 노이즈도 많이 생김
데이터가 잘게 쪼개져 학습하는데 오랜시간이 걸리며 노이즈도 많이 생김 보통 batch size는 32-512까지 2의 제곱수로 많이 정함(gpu 관련)
batchnorm(배치정규화)
: re-centering 및 re-scailing 등의 방법으로 레이어 입력의 정규화를 통해 인공신경망을 더 빠르고 안정적으로 만드는데 사용되는 방법
keras.layers.BatchNormalization()
2) optimizer(최적화도구)
loss함수의 최소값을 찾기 위한 옵션
adam이 보통 제일 좋은 결과를 냄(요즘은 adamW도 많이 사용)
옵티마이저에 따라 learning rate와 momentum도 조절
참고하기 : https://keras.io/ko/optimizers/
3) learnig rate(학습률)
: gradient의 방향으로 얼마나 빠르게 이동할 것인지 결정하는 변수
: 가중치 업데이트 시 한 스텝을 가는 보폭
기본값 .01
너무 높은 경우 , 발산
, 발산 너무 낮은 경우 , 학습속도 느리며 최저점 찾는데 실패할 수 있음
, 학습속도 느리며 최저점 찾는데 실패할 수 있음 optimizer 내부 옵션으로 사용
<코드 예시>
def model_bulider ( hp ) : model = keras . Sequential ( ) model . add ( Flatten ( input_shape = ( 28 , 28 ) ) ) hp_unit = hp . Int ( ‘units’ , min_value = 32 , max_value = 512 , step = 32 ) model . add ( Dense ( units = hp_unit , activation = ‘relu’ ) ) model . add ( Dense ( 10 , activation = ‘softmax’ ) ) hp_learning_rate = hp . Choice ( ‘learning_rate’ , values = [ 1e – 2 , 1e – 3 , 1e – 4 ] ) model . compile ( optimizer = keras . optimizers . Adam ( learning_rate = hp_learning_rate ) , loss = keras . losses . SparseCategoricalCrossentropy ( from_logits = True ) , metrics = [ ‘accuracy’ ] ) return model
4) momentum(모멘텀)
optimizer에서 sgd와 함께 사용하는 옵션 — 밑에 코드 예시 보기
sgd만으로는 최적의 값을 도출하기 어려움(대부분 adam 보다 낮은 성능)
모멘텀의 역할은 경사 하강법에서 옵티마이저가 지역최소값에 빠졌을 때 탈출하도록 도와줌 지역 최소값 : 한 범위 내의 최소값, 손실함수 전체 범위에서 최소값을 찾아야 하므로 한 구역의 최소값이 최소값으로 인식되면 안됨
오목한 밥그릇에서 공을 굴릴 경우 관성으로 최저점을 지나쳐가는 원리
<코드 예시>
sgd = optimizers . SGD ( lr = 0.01 , decay = 1e – 6 , momentum = 0.9 , nesterov = True ) model . compile ( loss = ‘mean_squared_error’ , optimizer = sgd )
또는
model . compile ( loss = ‘categorical_crossentropy’ , optimizer = SGD ( lr = 0.01 , momentum = 0.9 ) , metrics = [ ‘accuracy’ ] )
5) Network weight initailize(네트워크 가중치 초기화)
: 가중치 초기화(시작점 찾기)에 따라 성능에 큰 영향을 줌
초기화 모두는 다양(정규분포, X-vier, He 등.. )
초기 정확도가 적은 epoch를 최적의 값을 찾기도 함
🔑가중치 초기화 별 활성화 값
1) 정규분포 초기화 : 표준편차를 1로 가중치를 초기화했을 때 활성화 값 분포
2) Xavier 초기화 : 가중치들의 편차를 1/sqrt(n)(=제곱근 n) 으로 초기화했을 때 활성화 값의 분포
3) He 초기화 : 가중치 표준편차를 sqrt(2/n)으로 초기화했을 때 활성화 값의 분포 — 고르게 분포
<활성화 함수에 따라 가중치 초기값 추천>
sigmoid 함수 일 때 , Xavier 초기화 — 표준편차 : 1/sqrt(n)
, Xavier 초기화 — 표준편차 : 1/sqrt(n) Relu 함수일 때, He 초기화 — 표준편차 : 1/sqrt(2/n)
6) Activation Fuction(활성화 함수)
보통 은닉층에서 Relu사용, 출력층에는 sigmoid나 softmax를 사용
하지만, 모델에 따라 tahn등 의 다른 활성함수들도 시도해보는 것 추천
6) 드롭아웃, Weight Constraint, weight decay
드롭 아웃 : 학습 중 무작위로 비활성화 하고 싶은 뉴런 비율
: 학습 중 무작위로 비활성화 하고 싶은 뉴런 비율 가중치 규제(wieght constraint) : 물리적으로 Weight의 크기를 제한해서 값이 커지면 다른 값으로 변경해버리는 기술
: 물리적으로 Weight의 크기를 제한해서 값이 커지면 다른 값으로 변경해버리는 기술 가중치 감소(wieght decay) : 과적합 방지를 위해 학습 규제 전략의 하나로 말 그대로 가중치를 감소시키는 기술
: 과적합 방지를 위해 학습 규제 전략의 하나로 말 그대로 가중치를 감소시키는 기술 과적합이나 일반화 문제가 없다면 굳이 쓸 필요 없음
from keras import regularizers model2 = models . Sequential ( ) model2 . add ( layers . Dense ( 16 , kernel_regularizer = regularizers . l2 ( 0.001 ) , activation = ‘relu’ , input_shape = ( 10000 , ) ) ) model_dropout . add ( layers . Dropout ( 0.5 ) ) model2 . add ( layers . Dense ( 16 , kernel_regularizer = regularizers . l2 ( 0.001 ) , activation = ‘relu’ ) ) model2 . add ( layers . Dense ( 1 , activation = ‘sigmoid’ ) )
from tensorflow . keras . constraints import max_norm model . add ( Dense ( 64 , kernel_constraint = max_norm ( 2 . ) ) )
7) 은닉층의 수, 뉴런(노드)의 수
하나의 은닉층으로 이루어진 퍼셉트론일 경우 선형적 분리가 가능한 데이터셋만
학습이 가능
학습이 가능 layer를 추가하여 비선형 데이터도 학습 가능해짐
layer가 너무 많아질 경우 과적합이나, 학습시간의 문제가 있음
신경망이 커질수록 드롭아웃 규제나 다른 규제방법으로 과적합을 해결해아 함
보통 layer의 수가 노드의 수 보다 중요
👩🏻 실험 추적 프레임워크 (ETF)
🔥 Wandb 이용
!pip install wandb from wandb . keras import WandbCallback wandb_project = “review” wandb_group = “” wandb . login !git clone http : // github . com / wandb / tutorial !cd tutorial ; pip install – – upgrade – r requirements . txt ; !wandb login [ key ] !python – c “import keras; print(keras.__version__)” url = “https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv” data = pd . read_csv ( url , header = None ) . values X = data [ : , 0 : 8 ] y = data [ : , 8 ] from tensorflow . keras . models import Sequential wandb . init ( project = wandb_project ) inputs = X . shape [ 1 ] wandb . config . epochs = 50 wandb . config . batch_Size = 20 model = Sequential ( ) model . add ( Dense ( 100 , input_dim = 8 , activation = ‘relu’ ) ) model . add ( Dense ( 1 , activation = ‘sigmoid’ ) ) model . compile ( loss = ‘binary_crossentropy’ , optimizer = ‘adam’ , metrics = [ ‘accuracy’ ] ) model . fit ( X , y , validation_split = 0.3 , epochs = wandb . config . epochs , batch_size = wandb . config . batch_Size , callbacks = [ WandbCallback ( ) ] )
< 출력화면 >
출력된 링크로 들어가보면 세부사항들을 기록들을 볼 수 있다
👩🏻 Keras Tuner
Keras Tuner
: TensorFlow 프로그램의 최적 파라미터 선택에 도움을 주는 라이브러리
🔥 이미지 분류 코드 예시
하이퍼 파라미터 튜닝 (1)
논문 : Yu, T., & Zhu, H. (2020). Hyper-parameter optimization: A review of algorithms and applications. arXiv preprint arXiv:2003.05689.
1. Contribution
– Hyper-parameters are systematically categorized into structure-related and training-related. The discussion of their importance and empirical strategies are helpful to determine which hyper-parameters are involved in HPO.
– HPO algorithms are analyzed and compared in detail, according to their accuracy, efficiency and scope of application. The analysis on previous studies is not only committed to include state-of-the-art algorithms, but also to clarify limitations on certain scenarios.
– By comparing HPO toolkits, this study gives insights of the design of close-sourced libraries and open-sourced services, and clarifies the targeted users for each of them.
– The potential research direction regarding to existing problems are suggested on algorithms, applications and techniques.
2. Major Hyper-Parameters and Search Space
위 논문에서 얘기하는 바로, 하이퍼 파라미터는 크게 두 종류로 정의될 수 있다.
하나는 Training-related parameter로 모델 학습 과정에 관련된 하이퍼파라미터이다.
본 섹션에서 소개될 대표적인 예로, LR (learning rate)와 Optimizer 가 존재한다.
두 번째는 structure-related parameter로 모델의 구조에 관련된 하이퍼파라미터이다.
본 섹션에서 소개될 대표적인 예로, 히든 레이어의 개수, 각 레이어에 사용되는 뉴런의 개수 등이 존재한다.
(1) Training-related parameter
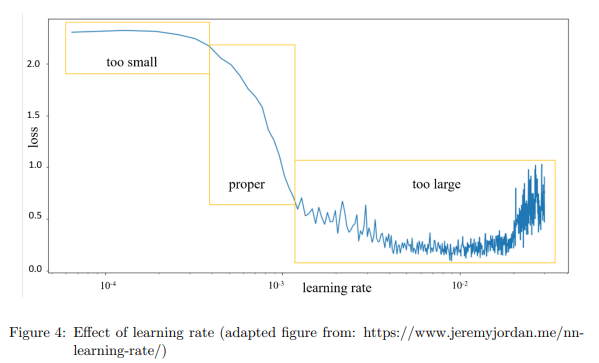
(A) LR
So you have finished reading the 딥 러닝 하이퍼 파라미터 튜닝 topic article, if you find this article useful, please share it. Thank you very much. See more: 하이퍼파라미터 튜닝 자동화, 신경망 하이퍼파라미터, 머신러닝 하이퍼 파라미터 튜닝, 파이썬 하이퍼파라미터 튜닝, 하이퍼 파라미터 튜닝이란, 파이토치 하이퍼 파라미터 튜닝, 하이퍼파라미터 최적화, 하이퍼파라미터 튜닝 교차검증