
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 정보 처리 기사 실기 정리 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://chewathai27.com/to team, along with other related topics such as: 정보 처리 기사 실기 정리 정보처리기사 실기 요약 pdf, 2022 정보처리기사 실기 요약 pdf, 2021 정보처리기사 실기 요약, 정보처리기사 실기 요약 2021 pdf, 정보처리기사 실기 2021 pdf, 정보처리기사 실기 벼락치기, 정보처리기사 실기 2022 pdf, 시나공 정보처리기사 실기 pdf
정보처리기사 실기 정리 – 1. 요구사항 확인 정보처리기사 실기 정리 – 1. 요구사항 확인 Chapter01 소프트웨어 개발 방법론 (중요도: ★★★) ◆ 소프트웨어 생명주기 (SDLC): 시스템의 요구분석부터 유지보수까지 전 공정을 체계화한 절차 ◆ 소프트웨어 생명주기 모델 종류 …
정보처리기사 실기 요약 정리 (2022 ver.)
- Article author: dustink.tistory.com
- Reviews from users: 1595
 Ratings
Ratings - Top rated: 4.4
- Lowest rated: 1
- Summary of article content: Articles about 정보처리기사 실기 요약 정리 (2022 ver.) Updating …
- Most searched keywords: Whether you are looking for 정보처리기사 실기 요약 정리 (2022 ver.) Updating 2022 정보처리 기사 실기 요약 정리 ◈ 2022 정보처리기사 시험 일정 ◈ 정보처리기사 실기 요약 정리 (제목을 누르면 해당 페이지로 넘어갑니다.) < 1권 > 1. 요구사항 확인 2. 화면 설계 3. 데이터 입출력 구현..
- Table of Contents:
2022 정보처리 기사 실기 요약 정리
태그
관련글
댓글17
최근글
인기글
티스토리툴바

별의 블로그 :: [정보처리기사 실기] 단원별 정리 & 예상 문제
- Article author: starrykss.tistory.com
- Reviews from users: 44502 Ratings
- Top rated: 3.0
- Lowest rated: 1
- Summary of article content: Articles about 별의 블로그 :: [정보처리기사 실기] 단원별 정리 & 예상 문제 정보처리기사 실기 시험을 준비하며서 블로그에 올렸었던 글들을 한 페이지에 정리해본다. 개념 정리. 2020년 NCS 개편 후의 내용들; 수험서, 인터넷 … …
- Most searched keywords: Whether you are looking for 별의 블로그 :: [정보처리기사 실기] 단원별 정리 & 예상 문제 정보처리기사 실기 시험을 준비하며서 블로그에 올렸었던 글들을 한 페이지에 정리해본다. 개념 정리. 2020년 NCS 개편 후의 내용들; 수험서, 인터넷 … 정보처리기사 단원별 정리 & 예상 문제 정보처리기사 실기 시험을 준비하며서 블로그에 올렸었던 글들을 한 페이지에 정리해본다. 개념 정리 2020년 NCS 개편 후의 내용들 수험서, 인터넷 블로그 등의 자료를..
- Table of Contents:
개념 정리
기출 문제
예상 문제 문제 정리
시험에 도움이 될 만한 것들
시험 준비 팁
티스토리툴바
![별의 블로그 :: [정보처리기사 실기] 단원별 정리 & 예상 문제](https://t1.daumcdn.net/tistory_admin/static/images/openGraph/opengraph.png)
정보처리기사 실기 목차 – 정리, 예상문제, 문제 복원 수록
- Article author: ss-o.tistory.com
- Reviews from users: 2105 Ratings
- Top rated: 3.8
- Lowest rated: 1
- Summary of article content: Articles about 정보처리기사 실기 목차 – 정리, 예상문제, 문제 복원 수록 1. 정리 ( 수제비 교재 기준 ) · 2. 모의고사 ( 예상문제 ) · 3. 정보처리기사 실기 기출문제 복원 … …
- Most searched keywords: Whether you are looking for 정보처리기사 실기 목차 – 정리, 예상문제, 문제 복원 수록 1. 정리 ( 수제비 교재 기준 ) · 2. 모의고사 ( 예상문제 ) · 3. 정보처리기사 실기 기출문제 복원 … 1. 정리 ( 수제비 교재 기준 ) 과목 내용 1과목 1과목 요구사항 확인 2과목 2과목 데이터 입출력 구현 3과목 3과목 통합구현 4과목 4과목 서버 프로그램 구현 5과목 5과목 인터페이스 구현 6과목 6과목 화면 설계..
- Table of Contents:
태그
관련글
댓글24
공지사항
최근글
인기글
최근댓글
전체 방문자
티스토리툴바
2021 정보처리기사 실기 정리 – ToDev
- Article author: powerdev.tistory.com
- Reviews from users: 42097 Ratings
- Top rated: 5.0
- Lowest rated: 1
- Summary of article content: Articles about 2021 정보처리기사 실기 정리 – ToDev 정보처리기사 실기를 준비하면서 요약정리 했던 내용을 올립니다. 정말 외워야 한다고 생각하는 부분들만 정리했습니다. …
- Most searched keywords: Whether you are looking for 2021 정보처리기사 실기 정리 – ToDev 정보처리기사 실기를 준비하면서 요약정리 했던 내용을 올립니다. 정말 외워야 한다고 생각하는 부분들만 정리했습니다. ※ 본 정리 글은 수제비 정보처리기사 실기책을 참고하여 작성했습니다 → 책정보 확인하기 2021 수제비 정보처리기사 실기 (1권+2권 합본세트) 2020년 기출 문제 수록 T 비전공자를 위해 만들어진 수험서다. NCS..
- Table of Contents:
정보처리기사 실기 요약 정리 모음집
- Article author: die-romantische-schule.tistory.com
- Reviews from users: 3570 Ratings
- Top rated: 4.3
- Lowest rated: 1
- Summary of article content: Articles about 정보처리기사 실기 요약 정리 모음집 2021 정보처리기사 실기 요약 정리 모음집 목차 1. 단원별 요약 정리 모음 2. 참고 교재 단원별 요약 정리 모음 단원 클릭시 해당 단원의 요약글로 … …
- Most searched keywords: Whether you are looking for 정보처리기사 실기 요약 정리 모음집 2021 정보처리기사 실기 요약 정리 모음집 목차 1. 단원별 요약 정리 모음 2. 참고 교재 단원별 요약 정리 모음 단원 클릭시 해당 단원의 요약글로 … 2021 정보처리기사 실기 요약 정리 모음집 목차 1. 단원별 요약 정리 모음 2. 참고 교재 단원별 요약 정리 모음 단원 클릭시 해당 단원의 요약글로 이동합니다 요구사항 확인 화면 설계 데이터 입출력 구현 통합..
- Table of Contents:
목차
단원별 요약 정리 모음
참고 교재
태그
관련글
댓글0
인기글
최근글
전체 방문자
티스토리툴바

2021 정보처리기사 실기 요약(전체)(20210709 수정) — 시간이 멈추는 장소
- Article author: narup.tistory.com
- Reviews from users: 25406 Ratings
- Top rated: 4.9
- Lowest rated: 1
- Summary of article content: Articles about 2021 정보처리기사 실기 요약(전체)(20210709 수정) — 시간이 멈추는 장소 2021 시나공 정보처리기사 책을 참고로 작성하고 있습니다. 요약 내용이 추가될 때마다 수정하고 있습니다. 필자는 이번에 3번 째 정보처리기사 실기 … …
- Most searched keywords: Whether you are looking for 2021 정보처리기사 실기 요약(전체)(20210709 수정) — 시간이 멈추는 장소 2021 시나공 정보처리기사 책을 참고로 작성하고 있습니다. 요약 내용이 추가될 때마다 수정하고 있습니다. 필자는 이번에 3번 째 정보처리기사 실기 … 2021 시나공 정보처리기사 책을 참고로 작성하고 있습니다. 요약 내용이 추가될 때마다 수정하고 있습니다. 필자는 이번에 3번 째 정보처리기사 실기를 보는데…(지난 번에는 58점으로 떨어짐 ㅠㅠ) 매번 나왔었..
- Table of Contents:
공지사항
최근 댓글
최근 글
티스토리
요구사항 설계 및 개발 프로세스
소프트웨어 개발
데이터베이스 요약
인터페이스 구현
화면 설계
애플리케이션 테스트 관리
암호화 및 소프트웨어 보안 요약
포인터 파이썬 정리 ★★★★★
프로토콜 네트워크 요약
운영체제
제품 소프트웨어 패키징
티스토리툴바
2021 정보처리기사 실기 정리(完) :: 1D1C
- Article author: 1d1cblog.tistory.com
- Reviews from users: 11879 Ratings
- Top rated: 3.9
- Lowest rated: 1
- Summary of article content: Articles about 2021 정보처리기사 실기 정리(完) :: 1D1C 2021년 정보처리기사 실기 정리 글입니다. 계속해서 글을 업데이트할 예정이지만 시험 일정에 맞추지 못할 수 있습니다. 정리 글에는 책의 내용을 … …
- Most searched keywords: Whether you are looking for 2021 정보처리기사 실기 정리(完) :: 1D1C 2021년 정보처리기사 실기 정리 글입니다. 계속해서 글을 업데이트할 예정이지만 시험 일정에 맞추지 못할 수 있습니다. 정리 글에는 책의 내용을 … 본 정리 글은 시나공 정보처리기사 실기책과 2020년 기출문제 등을 참고하여 작성하였습니다. -> 책 정보 확인하기 시나공 정보처리기사 실기 수험생들의 궁금증을 100% 반영시험에 나올만한 내용만 구성시나공 정..개인공부 정리 블로그
- Table of Contents:
2021 정보처리기사 실기 정리(完)
티스토리툴바

2021 정보처리기사 실기 총정리 요약 PDF(Updated)
- Article author: joft.kr
- Reviews from users: 29738 Ratings
- Top rated: 4.5
- Lowest rated: 1
- Summary of article content: Articles about 2021 정보처리기사 실기 총정리 요약 PDF(Updated) 기출+시나공+수제비+각종 자료들 단권화 & 압축 정리해서 만든 PDF 요약 자료 (총 11페이지). 미리보기. 정보처리기사_실기_총정리_joftware_UPDATED. …
- Most searched keywords: Whether you are looking for 2021 정보처리기사 실기 총정리 요약 PDF(Updated) 기출+시나공+수제비+각종 자료들 단권화 & 압축 정리해서 만든 PDF 요약 자료 (총 11페이지). 미리보기. 정보처리기사_실기_총정리_joftware_UPDATED. Undergraduate @ SungKyunKwan Univ. Software
- Table of Contents:

See more articles in the same category here: 316+ tips for you.
[정보처리기사 실기] 단원별 정리 & 예상 문제
Categories (1458) Programming (291) C (10) C++ (116) C# (0) Java (6) Python (20) Android (35) LISP (CL) (3) HTML5 (39) CSS3 (18) JavaScript (14) jQuery (24) Ajax (2) JSP (1) R (0) Kotlin (3) Source Code (117) C (18) C++ (10) C# (0) Java (0) Android (7) Python (11) LISP (CL) (6) HTML5 (1) CSS3 (8) JavaScript (35) jQuery (2) Ajax (1) JSP (0) R (1) Kotlin (17) Problem Solving (129) BaekJoon Online Judge (110) Project Euler (17) Etc. (2) Database (5) SQL (4) Computer Science (55) Data Structure (34) Algorithm (21) Computer Structure (0) Digital Logic Circuit (0) Computer Architecture (0) System Software (134) System Software (0) UNIX (6) Linux (128) Operating System (0) Computer Graphics (19) Computer Vision (0) Artificial Intelligence (0) Machine Learning (0) Data Science (0) In-depth Study (41) Git (13) Gradle (5) Refactoring (1) Signal Processing (2) TeX (4) NumPy (5) Pandas (8) matplotlib (3) Math & Science (7) Calculus (1) Linear Algebra (0) Discrete Mathematics (0) Probability and Statistics (6) Physics (0) Design (1) Adobe Photoshop (1) Adobe Premiere Pro (0) English (1) TOEIC (1) TOEFL (0) German (0) Certificate (590) Word Processor (31) CSSD (263) Network Manager (106) DPE (30) Linux Master (89) SQLD (19) ADsP (12) BDAE (1) OCAJP (38) ISE (0) LPIC (0) COS PRO (0) Cloud (1) Information (58) Tip (17) Article (1) Windows (11) MacOS (4) Etc. (25) Photography (0) Daily Life (8) Movie Review (0) Book Review (0) Diary (0) Study (3) Activity (5) Scribbling Board (0) Event (1)
2021 정보처리기사 실기 요약(전체)(20210709 수정)
반응형
2021 시나공 정보처리기사 책을 참고로 작성하고 있습니다. 요약 내용이 추가될 때마다 수정하고 있습니다.
필자는 이번에 3번 째 정보처리기사 실기를 보는데…(지난 번에는 58점으로 떨어짐 ㅠㅠ)
매번 나왔었던 부분이나, 애매하게 알았던 부분 등 꼭 필요한 요소들만 요약해서 정리하고 있습니다.
내용이 상당히 깁니다.
제 기준 대로 별표를 붙혔고, 5점은 꼭 숙지하시고, 4점 이상인 부분은 서술형으로도 쓸 수 있게 잘 외우셔야 합니다.
* 필자는 2021 2회차 실기에 85점으로 합격했습니다. 감사합니다!
요구사항 설계 및 개발 프로세스
모듈 ★ ★
공통 모듈 : 기능을 분할하고 추상화 하여 성능 향상 및 유지보수를 효과적으로 하기 위한 공통 컴포넌트 구현 기법
모듈 : 하나의 소프트웨어 또는 하드웨어 단위, 소프트웨어 설계에서 기능 단위로 분해해 추상화되어 재사용 및 공유가 가능한 단위
모듈화 : 모듈을 통해 소프트웨어의 성능을 향상 시키고 디버깅, 수정, 통합 을 용이하게 하는 설계 기법
공통 모듈 명세 기법[정명완일추] ★ ★ ★ ★ ★
정확성 : 시스템 구현 시 해당 기능이 필요 하다는 것을 알 수 있도록 정확히 작성
명확성 : 해당 기능을 이해할 때 중의적으로 해석되지 않도록 명확히 작성
완전성 : 시스템 구현을 위해 필요한 모든 것을 기술
일관성 : 공통 기능들 간 상호 충돌이 발생하지 않도록 작성
추적성 : 기능에 대한 요구사항의 출처 , 관련 시스템 등의 관계를 파악 할 수 있도록 작성
결함관리 측정지표 ★ ★
결함 분포 : 모듈 또는 컴포넌트의 특정 속성에 해당하는 결함 수 측정
결함 추세 : 테스트 진행 시간에 따른 결함 수의 추이 분석
결함 에이징 : 특정 결함 상태로 지속되는 시간 측정
XP(eXtreme Programming) 기법 ★ ★ ★
핵심 가치 : 의사소통(Communication), 단순성(Simplicity), 용기(Courage), 존중(Respect), 피드백(Feedback)[의단용존피]
Pair Programming(짝 프로그래밍) : 다른 사람과 함께 프로그래밍 을 수행함으로 개발에 대한 책임을 공동으로 나눠 갖는 환경 조성
Test-Driven Development(테스트 주도 개발) : 테스트 케이스를 먼저 작성 해 자신 이 무엇을 해야할지 정확히 파악. 테스트가 지속적으로 진행될 수 있도록 자동화된 테스팅 도구 사용
Whole Team(전체 팀) : 개발에 참여하는 모든 구성원은 각자의 역할에 따른 책임 을 가져야함
Continuous Integration(계속적인 통합) : 모듈 단위로 나눠서 개발된 코드 는 작업이 마무리 될 때마다 지속적으로 통합 됨
Design Improvement(디자인 개선 또는 리팩토링) : 프로그램 기능의 변경 없이 단순화, 유연성 강화 등을 통해 시스템 재구성
Small Releases(소규모 릴리즈) : 릴리즈 기간을 짧게 반복 해 고객의 요구 변화에 신속히 대응
XP 개발 프로세스 ★ ★
사용자 스토리 : 요구사항 간단한 시나리오로 표현. 기능 단위 구성.
릴리즈 계획 수립 : 부분적으로 기능이 완료된 제품 제공
스파이크 : 요구사항 신뢰도를 높이고, 기술 문제의 위험 감소를 위해 별도로 만드는 프로그램
이터레이션 : 하나의 릴리즈를 더 세분화한 단위
승인 검사(인수 테스트) : 계획된 릴리즈 단위가 부분 완료가 구현되면 고객이 직접 수행해서 테스트함.
소규모 릴리즈
스크럼 개발 프로세스 ★ ★
제품 백로그 : 제품 개발에 필요한 요구사항을 우선순위에 따라 나열한 로그 리스트. 지속적으로 업데이트되며, 사용자 스토리 기반의 릴리즈 계획 수립
스프린트 계획 회의 : 수행할 작업에 대한 단기적 일정. 태스크(Task) 작업 단위로 분할. 개발자별로 수행할 작업 목록인 스프린트 백로그 작성
스프린트 : 실제 개발 작업 과정. 개발자가 원하는 태스크를 담당할 수 있도록 함. 할 일(Todo), 진행 중(In Progress), 완료(Done)의 상태로 태스크 관리
일일 스크럼 회의 : 15분 정도의 짧은 시간으로 진행상황을 점검하고 남은 작업 시간을 소멸 차트에 표시한다.
스프린트 검토 회의 : 제품 책임자(PO)는 개선할 사항에 대한 피드백을 정리 후 다음 스프린트에 반영할 수 있도록 제품 백로그를 업데이트함
스프린트 회고
소프트웨어 생명 주기 ★ ★
폭포수 모형 : 가장 오래되고 가장 폭넓게 사용된 전통적 모형으로 고전적 생명 주기 모형 이라 함. 두 개 이상의 과정 병행 수행 할 수 없음.
– 순서 : 타당성 검토 -> 계획 -> 요구분석 -> 설계 -> 구현 -> 시험 -> 유지보수.
프로토타입 모형 : 사용자와 시스템 사이의 인터페이스에 초점 . 시스템 모형의 골격 코드. 폭포수 모형의 단점 보안.
– 순서 : 요구 수집 -> 설계 -> 구축 -> 평가 -> 조정 -> 구현 -> 요구수집
나선형 모형 : 보헴(Boehm) 제안. 여러 번의 개발 과정과 검토 과정 을 거치는 점진적 모형. 별도의 유지보수 과정 필요 없음
애자일 모형 : 고객과의 소통 에 초점을 맞춘 방법론. 스프린트 또는 이터레이션 개발 주기 반복. 고객이 요구사항에 우선순위를 부여함.
– 종류 : 스크럼, XP, 칸반, Lean, 크리스탈, ASD, FDD, DSDM, DAD
스크럼 ★
제품 책임자(PO) : 이해관계자들의 의견을 종합해 제품에 대한 요구사항 작성. PO는 요구 사항이 담긴 백로그를 작성하고 백로그 우선 순위 를 지정
스크럼 마스터(SM) : 일일 스크럼 회의 주관하여 진행 사항을 점검 하고, 개발 과정에서 발생된 장애 요소를 공론화해서 처리
개발팀(DT) : 개발자, 디자이너, 테스터 등
UI 요구사항 작성 ★
요구사항 요소 확인 -> 정황 시나리오 작성 -> 요구사항 작성
요구사항 요소 확인 ★
데이터 요구 : 사용자가 요구하는 모델과 객체들의 주요 특성을 기반으로 하여 데이터 객체들을 정리(이메일의 메시지 속성 -> 제목, 발신인, 답변 등)
기능 요구 : 사용자의 목적 달성을 위해 무엇을 실행해야 하는지를 동사형으로 설명. 기능 요구 리스트는 최대한 철저하게 정리(읽거나 삭제, 다른 메시지와 함께 보관)
제품/서비스의 품질 : 데이터 및 기능 요구 외에 제품의 품질, 서비스, 여기에 감성적인 품질 등을 고려하여 작성.(얼마나 빠르게 처리할 수 있는지의 여부 등 정량화가 가능한 요구사항)
제약 사항 : 제품 완료 데드라인, 전체 개발 및 제작에 필요한 비용, 시스템 준수에 필요한 규제가 포함.(제약사항의 변경 가능 여부 확인)
요구사항 개발 프로세스[도분명확] ★ ★ ★ ★ ★
도출 : 시스템, 사용자, 개발자가 의견을 교환 하여 요구사항을 식별하고 이해하는 과정. 소프트웨어 개발 생명주기(SDLC) 반복
– 요구사항 도출 방법 : 인터뷰, 설문, 브레인스토밍, 워크샵, 프로토타이핑, 유스케이스(사용사례)
분석 : 요구사항 중 명확하지 않거나 모호한 부분을 걸러내는 과정. 타당성을 조사 . 비용과 일정에 대한 제약 설정
– 요구사항 분석 기법 : 요구사항 분류, 개념 모델링, 요구사항 할당, 요구사항 협상, 정형 분석[분개할협정]
명세 : 요구사항을 체계적으로 분석 한 후 승인될 수 있도록 문서화.
확인 : 개발 자원을 요구사항에 할당하기 전에 명세서가 정확하고 완전하게 작성되었는지를 검토 . 요구사항 관리 도구를 이용하여 요구사항 정의 문서를 형상 관리 해야 함.
– 요구사항 확인 기법 : 요구사항 검토, 프로토타이핑, 모델 검증(정적 분석), 인수 테스트[요프모인]
요구공학 : 무엇을 개발해야 하는지, 요구 사항을 정의하고 분석 및 관리 하는 프로세스를 연구 하는 학문 .
정황 시나리오 : 사용자의 요구사항을 도출하기 위해 작성 하는 것. 사용자가 목표를 달성하기 위해 수행하는 방법을 순차적으로 묘사
정형 명세기법 : 수학적 기호 , 정형화 된 표기법. 종류(VDM, Z, Petri-net, CSP)
비정형 명세기법 : 일반 명사, 동사 등의 자연어를 기반 으로 서술 또는 다이어그램 으로 작성. 종류(FSM, Decision Table, ER모델링, State Chart(SADT) 등.
연계 요구사항 ★
체크리스트 : 시스템 운영환경, 성능, 보안, 데이터발생주기 등의 기준에 대한 점검 을 통한 연계 요구사항 기법
브레인스토밍 : 소속된 인원들이 자발적으로 자연스럽게 제시된 아이디어 목록을 통한 연계 요구사항 기법
요구사항 검토 상세 항목 ★ ★ ★
동료 검토 : 작성자가 명세서 내용을 직접 설명하고 동료들이 이를 들으면서 결함을 발견하는 형태의 검토 방법
워크 스루 : 검토 회의 전에 사전 검토를 한 후에 짧은 검토 회의를 통해 결함을 발견하는 검토 방법
인스펙션 : 작성자를 제외한 다른 검토 전문가 들이 검토하는 방법
요구 사항 분석의 도구와 기법 ★ ★ ★
사용자 인터뷰, 핵심 사용자 그룹 면담(FGI: Focus Group Interview): 사용자 면담 또는 시스템 관리자 및 서비스 활용자와 같은 핵심 그룹 면담 연계 데이터 정의, 연계 데이터의 활용 목적, 필요성 등을 식별하기 위함으로 사용자 인터뷰 전 연계 대상 시스템의 응용 애플리케이션 기능, 서비스의 확인이 필요함
체크리스트(Checklist) : 연계 데이터와 연계 시스템 아키텍처 정의를 위해 시스템 운영 환경, 성능, 보안, 데이터 발생 등 다각도의 관점에서 고려 사항 점검 및 확인
설문지 및 설문 조사 : 서비스 활용 목적에 따라 연계가 필요한 데이터를 식별하고, 연계 주기 등을 분석하기 위해 설문 조사 항목을 통해 자료를 수집. 객관식 문항으로 예상 답변을 일정 범위 이내로 한정할 수도 있음
델파이 기법 : 통합 구현 및 연계 전문가, 시스템 아키텍처, 업무 전문가 등 각 분야 전문가로부터 연계 데이터 및 사용자 요구 사항 식별
연계 솔루션 비교 분석: EAI, ESB, Open API 등 다양한 연계 방식과 연계 솔루션 별 연계 시의 성능, 보안, 데이터 처리, 모니터링 등의 장단점을 비교함
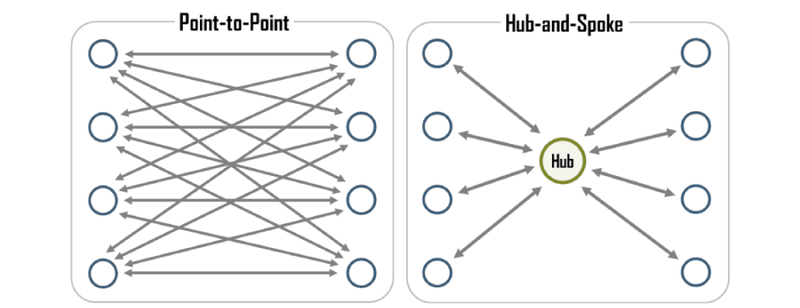
EAI(Enterprise Application Integration) ★ ★ ★ ★ ★
EAI는 기업 내 각종 애플리케이션 및 플롯폼 간의 정보 전달 , 연계 통합 등 상호 연동이 가능하게 해주는 솔루션 이다. EAI는 비즈니스 간 통합 및 연계성을 증대시켜 효율성 및 각 시스템 간의 확정성을 높여준다.
Point-to-Point : 가장 기본적인 애플리케이션 통합 방식으로, 1대1로 연결 한다. 변경 및 재사용이 어렵다는 단점.
Hub & Spoke : 단일 접점인 허브 시스템을 통해 데이터를 전송하는 중앙 집중형 방식 . 확장, 유지 보수가 유리하다. 허브 장애 발생시 시스템 전체에 영향 이 있다는 단점.
Message Bus : 애플리케이션 사이에 미들웨어 를 두어 처리하는 방식이다. 확장성 이 뛰어나며 대용량 처리 가 가능하다.
Hybrid : Hub & Spoke와 Message Bus의 혼합 방식이다. 데이터 병목 현상을 최소화 할 수 있다.
ESB(Enterprise Service Bus) ★ ★ ★ ★ ★
ESB는 애플리케이션 간 연계, 데이터 변환, 웹 서비스 지원 등 표준 기반의 인터페이스를 제공하는 솔루션 이다. ESB는 애플리케이션 통합 측면에서 EAI와 유사하지만 애플리케이션 보다는 서비스 중심의 통합을 지향 한다. ESB는 특정 서비스에 국한 되지 않고 범용적으로 사용하기 위해 애플리케이션과의 결합도(Coupling)를 약하게 유지 한다. 관리 및 보안 유지가 쉽고, 높은 수준의 품질 지원이 가능하다.
* 느슨한 결합 : 클래스 간의 의존성을 최소화 하는 것으로, 각 모듈간 통합시 특정 서비스를 변경하더라도 연결된 다른 서비스에는 영향을 주지 않는 유연한 구조
* SOA(서비스 지향 아키텍처) : 기업의 소프트웨어 인프라인 정보시스템을 공유 와 재사용 이 가능한 서비스 단위나 컴포넌트 중심으로 구축하는 정보기술 아키텍처
요구사항 분석 ★ ★ ★ ★
요구사항 분석 : 개발 대상에 대한 사용자의 요구사항을 이해하고 문서화 하는 활동.
구조적 분석 기법 : 자료의 흐름과 처리를 중심 으로 하는 요구사항 분석 방법. 하향식 방법을 사용해 시스템을 세분화. 자료흐름도, 자료 사전, 개체 관계도 등의 도구를 사용.
자료흐름도 : 요구사항 분석에서 자료의 흐름 및 변환 과정과 기능을 도형 중심으로 기술 하는 방법. 버블 차트라고도 함.[프흐저단]
– 프로세스(Process) : 자료를 변환 시키는 시스템의 한 부분을 나타내며 처리, 기능, 변환, 버블이라고도 함.
– 자료 흐름(Data Flow) : 자료의 이동(흐름)이나 연관 관계를 나타냄
– 자료 저장소(Data Store) : 시스템에서의 자료 저장소(파일, 데이터베이스)를 나타냄
– 단말(Terminator) : 시스템과 교신하는 외부 개체 로 입력 데이터가 만들어지고 출력 데이터를 받음.
자료 사전(Data Dictionary) : 자료 흐름도에 있는 자료를 더 자세히 정의하고 기록한 것.
– () 자료의 생략 / [] 자료의 선택 / {} 자료의 반복
요구사항 분석용 도구 ★ ★ ★
SADT : SoftTech 사에서 개발. 시스템 정의, 소프트웨어 요구사항 분석, 시스템/소프트웨어 설계를 위한 도구. 구조적 요구 분석을 하기 위해 블록 다이어그램을 채택한 자동화 도구 .
SREM = RSL/REVS : TRW 사 가 실시간 처리 소프트웨어 시스템 에서 요구사항을 명확히 기술하도록 할 목적으로 개발한 도구.
PSL/PSA : 미시간 대학 에서 개발, PSL/PSA를 사용하는 자동화 도구.
TAGS : 시스템 공학 방법 응용에 대한 자동 접근 방법 . 개발 주기의 전 과정에 이용할 수 있는 통합 자동화 도구 .
HIPO : 시스템의 분석 및 설계 , 또는 문서화 에 사용되는 기법으로 시스템의 실행 과정인 입력, 처리, 출력 의 기능을 표현한 것. 하향식 소프트웨어 개발을 위한 문서화 도구다. 종류( 가시적 도표, 총체적 도표, 세부적 도표 )[가총세]
UML ★ ★ ★
UML : 의사소통이 원활하게 이루어지도록 표준화한 대표적인 객체지향 모델링 언어.
구성요소 : 사물[구행그주], 관계, 다이어그램.
– 구조사물 : 시스템의 개념적 물리적 요소를 표현.
– 행동사물 : 시간과 공간에 따른 요소들의 행동을 표현. 상호작용
– 그룹사물 : 그룹, 패키지
– 주해사물 : 주석
연관 관계 : 2개이상의 사물이 서로 관련된 관계. 사물 사이를 실선으로 연결, 방향성은 화살표 로 표현.
집합 관계 : 하나의 사물이 다른 사물에 포함되어 있는 관계. 포함되는 쪽에서 포함하는 쪽으로 속이 빈 마름모 를 연결해 표현.(포함하는 쪽이 마름모를 가짐)(컴퓨터가 프린터의 마름모를 가짐)
포함 관계 : 포함하는 사물의 변화가 포함되는 사물에게 영향을 미치는 관계. 포함되는 쪽에서 포함하는 쪽으로 속이 채워진 마름모 를 연결해 표현.
일반화 관계 : 하나의 사물이 다른 사물에 비해 더 일반적이거나 구체적인 관계다. 하위에서 상위인 사물 쪽으로 속이 빈 화살표 를 연결해 표현함.
의존 관계 : 서로 연관은 있으나 필요에 의해 서로에게 영향을 주는 짧은 시간 동안만 연관을 유지하는 관계. 연관과 비슷하게 점선 화살표 를 사용해 표현.
실체화 관계 : 사물이 할 수 있거나 해야하는 기능으로, 서로를 그룹화 할 수 있는 관계다. 사물에서 기능 쪽으로 속이 빈 점선 화살표 를 연결해 표현.
다이어그램 ★ ★ ★ ★ ★
구조적 다이어그램
– 클래스 다이어그램 : 클래스와 클래스가 가지는 속성, 클래스 사이의 관계 를 표현함.
– 객체 다이어그램 : 클래스에 속한 사물들, 즉 인스턴스를 특정 시점의 객체와 객체 사이의 관계로 표현함. 럼바우 객체지향 분석 기법 에서 객체 모델링에 활용됨.
– 컴포넌트 다이어그램 : 실제 구현 모듈인 컴포넌트 간의 관계나 컴포넌트 간의 인터페이스 를 표현함. 구현단계에서 사용됨.
– 배치 다이어그램 : 결과물, 프로세스, 컴포넌트 등 물리적 요소들의 위치 를 표현함. 구현단계에서 사용됨.
– 복합체 구조 다이어그램 : 클래스나 컴포넌트가 복합 구조를 갖는 경우 그 내부 구조를 표현함.
– 패키지 다이어그램 : 유스케이스나 클래스 등의 모델 요소들을 그룹화한 패키지들의 의존 관계 를 표현함. 실선으로 표현된 의존관계 를 사용.
행위 다이어그램
– 유스케이스 다이어그램 : 사용자의 요구를 분석하는 것으로, 기능 모델링 작업에 사용하며 개발될 시스템을 이용해 수행할 수 있는 기능을 사용자의 관점에서 표현한 것. 사용자(Actor) 와 사용 사례(Use Case) 로 구성됨.
– 시퀀스 다이어그램 : 상호 작용하는 시스템이나 객체들이 메시지 를 주고받으며 상호작용하는 과정을 그림으로 표현한 것. 생명선, 실행상자, 메시지 가 있음.
– 커뮤니케이션 다이어그램 : 동작에 참여하는 객체들이 주고받는 메시지와 객체들 간의 연관관계 를 표현한 것. 객체들 간의 관계를 Link 를 이용해 표현함.
– 상태 다이어그램 : 하나의 객체가 자신이 속한 클래스의 상태변화 혹은 다른 객체와의 상호작용에 따라 상태가 어떻게 변화하는지를 표현 함. 럼바우 객체 지향 분석기법에서 동적 모델링에 활용됨.
– 활동 다이어그램 : 시스템이 어떤 기능을 수행하는지 객체의 처리 로직이나 조건에 따른 처리의 흐름 을 순서에 따라 표현함. 자료 흐름도와 유사함. 액션과 액티비티가 있음.
– 상호작용 개요 다이어그램 : 상호작용 다이어그램 간의 제어 흐름을 표현함.
– 타이밍 다이어그램 : 객체 상태 변화와 시간 제약을 명시적으로 표현함.
스테레오 타입 : UML에서 표현하는 기본 기능외에 추가적인 기능을 표현하는 것.
– <
> : 연결된 다른 UML 요소에 대해 포함 관계에 있는 경우. – <
> : 연결된 다른 UML 요소에 대해 확장 관계에 있는 경우. – <
> : 인터페이스를 정의하는 경우. – <
> : 예외를 정의하는 경우. – <
> : 생성자 역할을 수행하는 경우. 소프트웨어 개발
객체지향 분석 방법론 ★ ★ ★
Rumbaugh(럼바우) 방법 : 가장 일반적으로 사용되는 방법으로 분석 활동을 객체모델, 동적모델, 기능모델 로 나누어 수행하는 방법
Booch(부치) 방법 : 미시적(Micro) 개발 프로세스와 거시적(Macro) 개발 프로세스를 모두 사용하는 분석방법
Jacobson 방법 : Use Case를 강조하여 사용하는 분석방법
Coad와 Yourdon 방법 : E-R다이어그램을 사용하여 개체의 활동들을 데이터 모델링하는데 초점을 둔 기법
Wirfs-Brock 방법 : 분석과 설계간의 구분이 없고 고객 명세서를 평가해서 설계 작업까지 연속적으로 수행하는 기법
브룩스의 법칙 : 소프트웨어 개발 일정이 지연된다고 해서 새로운 개발 인력 을 진행 중인 프로젝트에 투입할 경우 작업 적응 기간과 부작용으로 인해 일정이 더욱 지연 된다는 법칙
객체지향설계 원칙[SOLID] ★ ★ ★
단일 책임 원칙 : 단 하나의 책임 만 가짐
개방-폐쇄 원칙 : 기존의 코드를 변경하지 않고 기능을 추가 할 수 있도록 설계
리스코프 치환 원칙 : 자식 클래스는 최소한 부모 클래스의 기능을 수행
인터페이스 분리 원칙 : 사용하지 않는 인터페이스 와 의존 관계를 맺거나 영향을 받지 않아야 함.
의존 역전 원칙 : 의존 관계 성립 시 추상성이 높은 클래스와 의존 관계 를 맺어야 함.
소프트웨어 아키텍처
소프트웨어 아키텍처 : 소프트웨어를 구성하는 요소들 간의 관계를 표현하는 시스템의 구조 또는 구조체다.
– 모듈화 : 시스템의 기능들을 모듈 단위로 나누는 것.
– 추상화 : 전체적이고 포괄적인 개념을 설계한 후 차례로 세분화하여 구체화 시켜 나가는 것.
– 단계적 분해 : 상위의 중요 개념으로부터 하위의 개념으로 구체화시키는 분할 기법.
객체 지향 ★ ★
객체 지향 : 각 요소들을 객체로 만든후 객체를 조립해서 소프트웨어를 개발하는 기법.
– 객체 : 데이터 와 이를 처리하기 위한 함수 를 묶어놓은 소프트웨어 모듈이다. 데이터를 가지며 상호작용의 수단으로 메시지를 사용 한다.
– 클래스 : 공통된 속성과 연산을 갖는 객체의 집합 . 클래스의 속한 각각의 객체를 인스턴스 라고 함.
– 메시지 : 객체들 간의 상호작용에 사용되는 수단으로, 객체의 동작 이나 연산 을 일으키는 외부의 요구사항 .
– 캡슐화 : 외부에서 접근을 제한하기 위해 인터페이스를 제외한 세부내용을 은닉 하는 것. 인터페이스가 단순해지고, 객체 간의 결합도가 낮아짐.
– 상속 : 상위 클래스의 모든 속성과 연산을 하위 클래스가 물려받는 것.
– 다형성 : 하나의 메시지에 대해 각각의 개체가 가지고 있는 고유한 방법으로 응답할 수 있는 능력.
LOC 기법 ★ ★ ★
– 노력(인월) = 개발 기간 x 투입 인원
= LOC / 1인당 월평균 생산 코드 라인수
– 개발 비용 = 노력(인월) X 단위 비용(1인당 월 평균 인건비)
– 개발 기간 = 노력(인월) / 투입 인원
– 생산성 = LOC / 노력(인월)
cocomo 소프트웨어 개발 모형 ★ ★
조직형 : 5만 라인(50KDSI)이하 의 소프트웨어를 개발하는 유형. 사무 처리용, 업무용, 과학용 응용 소프트웨어 개발에 적합
반분리형 : 조직형과 내장형의 중간형으로 30만(300KDSI) 라인 이하 의 소프트웨어를 개발하는 유형. 컴파일러, 인터프리터와 같은 유틸리티 개발에 적합
내장형 : 30만(300KDSI) 라인 이상 의 소프트웨어를 개발하는 유형. 신호기 제어 시스템, 미사일 유도 시스템, 실시간 처리 시스템 등의 시스템 프로그램 개발에 적합
수학적 산정 기법 ★ ★
COCOMO : 보헴이 제안한 것으로 LOC(원시 코드 라인 수)에 의한 비용 산정 기법
Putnam : 소프트웨어 생명주기의 전 과정 동안에 사용될 노력의 분포를 가정해주는 모형. 생명 주기 예측 모형이며, Rayleigh-Norden 곡선 의 노력 분포도를 기초로 함
기능 점수 : 알브레히트(Albrecht) 가 제안한 것으로, 소프트웨어의 기능을 증대시키는 요인 별로 가중치를 부여하고, 요인별 가중치를 합산 해 총 기능 점수를 산출해 기능 점수를 구한다.
비용 산정 자동화 추정 도구 ★ ★
SLIM : Rayleigh-Norden 곡선 과 Putnam 예측 모델 을 기초로 한 자동화 추정 도구
ESTIMACS : 다양한 프로젝트와 개인별 요소를 수용하도록 FP 모형을 기초로해 개발된 자동화 추정 도구
소프트웨어 개발 표준 ★ ★
CMMI(능력성숙도통합모델) : ISO15504(SPICE)를 준수하는 소프트웨어 개발 능력/성숙도 평가 및 프로세스 개선 활동의 지속적인 품질 개선 모델
SPICE(Software Process Improvement and Capability dEtermination) : 소프트웨어 개발 표준 중 소프트웨어의 품질 및 생산성 향상을 위해 소프트웨어 프로세스를 평가 및 개선하는 국제 표준 으로, 공식 명칭은 ISO/IEC 15504
소프트웨어 재사용 : 이미 개발되어 인정받은 소프트웨어를 다른 소프트웨어 개발이나 유지에 사용하는 것.
합성 중심 : 전자칩과 같은 소프트웨어 부품, 즉 블록을 만들어서 끼어 맞춰 소프트웨어를 완성시키는 방법. 블록 구성 방법이라고도 함.
생성 중심 : 추상화 형태로 써진 명세를 구체화해 프로그램을 만드는 방법으로, 패턴 구성 방법이라고도 함.
소프트웨어 재공학 : 기존시스템을 이용해 보다 나은 시스템을 구축하고, 새로운 기능을 추가하여 소프트웨어 성능을 향상시키는 것.
CASE(Computer Aided Software Engineering) : 소프트웨어 개발 과정에서 사용되는 요구 분석, 설계, 구현, 검사 및 디버깅 과정 전체 또는 일부를 컴퓨터와 전용 소프트웨어 도구를 사용해 자동화 하는것.
소프트웨어 개발 프레임워크 특성[모재확제] ★ ★ ★ ★
모듈화 : 프레임워크는 캡슐화 를 통해 모듈화를 강화 하고 설계 및 구현의 변경에 따른 영향을 최소화함으로서 소프트웨어의 품질을 향상시킴. 프레임 워크는 개발 표준에 의한 모듈화로 인해 유지보수가 용이함.
재사용성 : 프레임워크는 재사용 가능한 모듈들을 제공 함으로 예산 절감, 생산성 향상 , 품질 보증이 가능함.
확장성 : 프레임워크는 다형성을 통한 인터페이스 확장 이 가능해 다양한 형태와 기능을 가진 애플리케이션 개발이 가능함.
제어의 역전 : 개발자가 관리하고 통제해야하는 객체들의 제어를 프레임워크에 넘김 으로서 생산성을 향상 시킴.
* 전체적으로 생산성+ 품질+
소프트웨어 개발 방법론 ★ ★
소프트웨어 개발 방법론 : 소프트웨어 개발, 유지보수 등에 필요한 여러 가지 일들의 수행 방법과 이러한 일들을 효율적으로 수행하려는 과정에서 필요한 각종 기법 및 도구를 체계적으로 정리해 표준화 한것.[구정객컴제]
– 구조적 방법론 : 사용자 요구사항을 파악해 문서화하는 처리 중심의 방법론
– 정보공학 방법론 : 계획, 분석, 설계, 구축에 정형화된 기법들을 통합 및 적용하는 자료 중심의 방법론
– 객체지향 방법론 : 객체들을 조립해서 필요한 소프트웨어를 구현하는 방법론
– 컴포넌트 기반 방법론 : 기존의 시스템이나 소프트웨어를 구성하는 컴포넌트를 조합해 하나의 새로운 애플리케이션을 만드는 방법론
– 제품 계열 방법론 : 제품에 적용하고 싶은 공통된 기능을 정의해 개발하는 방법론
테일러링(Tailoring) : 프로젝트의 특성과 필요 에 따라 소프트웨어 개발 프로세스, 기법, 산출물 등을 비즈니스 적으로 또는 기술적인 요구에 맞도록 최적화 하는 과정 및 방법론
프로젝트 일정 계획 ★ ★ ★
– PERT(프로그램 평가 및 검토 기술) : 프로젝트에 필요한 전체작업의 상호 관계를 표시 하는 네트워크
– CPM(임계 경로 기법) : 프로젝트 완성에 필요한 작업을 나열하고 작업에 필요한 소요 기간을 예측하는데 사용하는 기법
– 간트 차트 : 프로젝트의 각 작업들이 언제 시작하고, 언제 종료되는지에 대한 작업 일정을 막대 도표를 이용해 표시하는 프로젝트 일정표.
데이터베이스 요약
데이터베이스 ★ ★ ★ ★
공동으로 사용될 데이터를 중복을 배제 하여 통합 하고, 저장장치에 저장해 항상 사용할 수 있도록 운영하는 운영 데이터[통저운공]
– 통합된 데이터 : 자료의 중복을 배제 한 데이터의 모임
– 저장된 데이터 : 컴퓨터가 접근할 수 있는 저장 매체에 저장 된 자료
– 운영 데이터 : 조직의 고유한 업무를 수행 하는데 반드시 필요한 자료
– 공용 데이터 : 여러 응용시스템들이 공동으로 소유 하고 유지하는 자료
DBMS : 사용자의 요구에 따라 정보를 생성해주고, 데이터를 관리해주는 소프트웨어[정조제]
– 정의 기능 : 모든 응용 프로그램들이 요구하는 데이터 구조를 지원하기 위해 데이터베이스에 저장될 데이터의 형과 구조에 대한 정의, 이용방식, 제약 조건 등을 명시 하는 기능
– 조작 기능 : 데이터 검색, 갱신, 삽입, 삭제 등을 체계적으로 처리하기 위해 사용자와 데이터베이스 사이의 인터페이스 수단을 제공 하는 기능
– 제어 기능 : 데이터베이스를 접근하는 갱신, 삽입, 삭제 작업이 정확하게 수행 되어 데이터의 무결성이 유지 되도록 제어하는 기능
스키마 : 데이터베이스의 구조 와 제약 조건 에 관한 전반적인 기술을 명세 한 것.[외개내]
– 외부 스키마 : 사용자나 응용 프로그래머가 각 개인의 입장에서 필요로하는 데이터베이스의 논리적 구조 를 정의한 것
– 개념 스키마 : 데이터베이스의 전체적인 논리적 구조. 하나만 존재 함.
– 내부 스키마 : 물리적 저장장치의 입장에서 본 데이터베이스 구조. 실제로 저장될 레코드 형식, 물리적 순 서를 나타냄.
데이터베이스 설계시 고려사항[무일회보효데] ★ ★ ★
– 무결성 : 삽입, 삭제, 갱신 연산 후에도 정해진 제약조건을 항상 만족 해야 함.
– 일관성 : 특정 질의에 대한 응답이 항상 일정 해야 함.
– 회복 : 장애가 발생했을 때 장애 발생 직전의 상태로 복구 되어야 함.
– 보안 : 불법적인 데이터 노출 또는 변경이나 손실로부터 보호
– 효율성 : 응단 시간의 단축, 시스템의 생산성 , 저장공간의 최적화 가 가능해야함.
– 데이터베이스 확장 : 운영에 영향을 주지 않으면서 지속적으로 데이터를 추가 할 수 있어야 함.
데이터베이스 설계 순서[요개논물구] ★ ★ ★
요구 조건 분석 > 개념적 설계 > 논리적 설계 > 물리적 설계 > 구현
– 개념적 설계 : 현실 세계를 추상적 개념 으로 표현, 개념 스키마 모델링 , 트랜잭션 모델링
– 논리적 설계 : 개념 스키마를 평가 및 정제 , 트랜잭션 인터페이스 설계
– 물리적 설계 : 데이터베이스 파일의 저장 구조 및 액세스 경로 결정 , 저장 레코드의 형식, 순서, 접근 경로
데이터 모델 ★ ★ ★
데이터 모델 : 현실 세계의 정보들을 컴퓨터에 표현하기 위해 단순화, 추상화 하여 체계적으로 표현한 개념적 모형 .[구연제]
– 구조 : 논리적으로 표현된 개체 타입들 간의 관계로서 데이터 구조 및 정적 성질 표현
– 연산 : 데이터베이스에 저장된 실제 데이터를 처리 하는 작업에 대한 명세 이며 조작 하는 기본 도구
– 제약 조건 : 실제 저장되는 데이터의 논리적인 제약 조건.
개념적 데이터 모델 : 현실 세계에 대한 인간의 이해를 돕기 위해 현실 세계에 대한 인식을 추상적 개념 으로 표현 하는 과정. 대표적으로 E-R모델 이 있음.
논리적 데이터 모델 : 개념적 모델링 과정에서 얻은 개념적 구조를 컴퓨터가 이해하고 처리 할 수 있는 컴퓨터 세계의 환경 에 맞도록 변화하는 과정. 관계 모델, 계층 모델, 네트워크 모델 로 구분.
E-R 모델 : 개체와 개체 간의 관계를 기본 요소로 이용해 현실 세계의 무질서한 데이터를 개념적인 논리 데이터로 표현 하기 위한 방법. 피터 첸 에 의해 제안.
– 사각형 : 개체(엔티티) 타입
– 마름모 : 관계 타입
– 타원 : 속성 타입
관계형 데이터베이스 ★
관계형 데이터베이스 : 2차원적인 표 를 이용해 데이터 상호 관계를 정의 하는 데이터베이스. E.F Codd 에 의해 제안.
– 도메인 : 하나의 애트리뷰트가 취할 수 있는 같은 타입의 원자 값들의 집합 .
– 관계형 데이터 모델 : 2차원적인 표를 이용해 데이터 상호 관계 를 정의하는 DB 구조.
DBMS 필수 기능 ★ ★
DCL(데이터 제어 언어)의 기능 : 보안, 무결성, 장애회복, 병행 수행 제어등을 정의하는데 사용하는 언어.
– COMMIT : 실제 물리 디스크에 저장. DB조작 작업이 정상적으로 완료되었음을 관리자에게 알려줌.
– ROLLBACK : 작업이 비정상적으로 종료되었을 때 원래의 상태로 복구
– GRANT : 사용자의 사용 권한을 부여
– REVOKE : 사용자의 사용 권한을 취소.
– SAVEPOINT : 트랜잭션 내에 ROLLBACK 할 위치인 저장점 을 지점.
EX) GRANT 권한리스트 ON 개체 TO 사용자 / REVOKE GRANT OPTION FOR 권한 리스트 ON 개체 FROM 사용자
정규화 관련 ★ ★ ★ ★
이상 현상 : 릴레이션 조작시 데이터들이 불필요하게 중복되어 예기치 않게 발생하는 곤란한 현상이며, 데이터의 중복성으로 인해 릴레이션을 조작할때 발생하는 비합리적인 현상[삽입,삭제,갱신]
비정규화 : 정규화된 엔티티 , 속성, 관계에 대해 성능 향상 과 개발 운영의 단순화를 위해 중복, 분리, 통합 (그룹핑)을 수행하는 데이터 모델링 기법
정규화 : 관계형 데이터베이스의 설계 에서 중복을 최소화 할 수 있도록 데이터를 구조화 하여 각 릴레이션에서 이상현상이 생기지 않도록 하는 데이터 모델링 기법
정규화 과정[도부이결다조] ★ ★ ★ ★
1NF : 릴레이션에 속한 모든 도메인이 원자값만으로 되어 있는 정규형. 릴레이션의 모든 속성값이 원자값으로만 되어 있는 정규형
2NF : 릴레이션 R이 1NF고, 기본키가 아닌 모든 속성이 기본키에 대해 완전 함수적 종속을 만족하는 정규형(부분적 함수 종속 제거)
3NF : 릴레이션 R이 2NF이고, 기본키가 아닌 모든 속성이 기본키에 대해 이행적 종속을 만족하지 않는 정규형(A-B이고, B->C일 때 A->C를 만족하지 않음)(이행적 함수 종속 제거)
BCNF : 릴레이션 R에서 결정자가 모두 후보키인 정규형. 모든 BCNF가 종속성을 보존하는 것은 아님(결정자이면서 후보키가 아닌 것 제거)
4NF : 릴레이션 R에 다치 종속 A->>B가 성립하는 경우, R의 모든 속성이 A에 함수적 종속 관계를 만족하는 정규형
5NF : 릴레이션 R의 모든 조인 종속이 R의 후보키를 통해서만 성립되는 정규형
함수적 종속 : X->Y 관계에서 X가 결정자이고, Y가 종속자다.
데이터 관련 ★ ★ ★
관계 대수 : 관계형 데이터베이스에서 원하는 정보와 그 정보를 어떻게 유도하는 가를 기술하고, 관계로 표현된 데이터를 취급하는 대수적인 연산 체계 이자 절차적 정형언어 이다.
– Select б : 릴레이션의 주어진 조건을 만족하는 튜플을 선택하는 연산. 수평 연산.
– Project π : 단항 연산으로 릴레이션에서 참조하고자 하는 어트리뷰트를 선택하여 분리해 내는 연산. 수직 연산
– Join >< : 두 릴레이션 간의 에트리뷰트 값이 동일한 튜플을 연결하는 연산 - Division ÷ : 두 개의 릴레이션 A와 B가 있을 때 B의 릴레이션의 모든 조건을 만족하는 경우의 튜플들을 릴레이션 A에서 분리해 내어 프로젝션하는 연산 일반 집합 연산자 ★ ★ ★ - 합집합 U : 이항 연산으로 관계성이 있는 두 개의 릴레이션을 합집합하여 하나의 릴레이션을 만들어 내는 연산 - 교집합 ∩ : 이항 연산으로 관계성이 있는 두개의 릴레이션에서 중복되어 있는 내용을 선택하여 새로운 릴레이션을 만들어 내는 연산 - 차집합 - : 이항 연산으로 관계성이 있는 두개의 릴레이션이 있을 때 그 중 하나의 릴레이션에서 또 다른 릴레이션의 내용과 겹치는 내용을 제거해서 새로운 릴레이션을 생성하는 연산 - 카티션 프로덕트 X : 이항 연산으로 두 릴레이션의 현재 투플로 구성 가능한 모든 조합 만드는 연산 관계 해석 : 관계 데이터의 연산을 표현하는 방법. 술어 해석 에 기반을 둠. 키 ★ ★ 후보키 : 속성들 중에서 튜플을 유일하게 식별하기 위해 사용 되는 속성들의 부분 집합. 유일성과 최소성을 모두 만족. - 유일성 : 하나의 키 값으로 하나의 튜플만을 유일하게 식별 할 수 있어야 함. - 최소성 : 키를 구성하는 속성 하나를 제거하면 유일하게 식별할 수 없도록 최소의 속성으로 구성 되어야 함. 기본키 : 후보키 중에서 특별하게 선정된 메인 키. 대체키 : 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키 슈퍼키 : 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키. 릴레이션을 구성하는 모든 튜플에 대해 유일성은 만족 하지만, 최소성은 만족 하지 못함. 외래키 : 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합. 시스템 카탈로그 ★ ★ 데이터베이스에 저장되어 있는 모든 데이터 개체들의 관한 정보나 명세에 대한 정보가 수록 되어 있는, DBMS가 생성하고 유지하는 데이터베이스 내의 테이블들의 집합체 - 메타 데이터 : 시스템 카탈로그에 저장된 정보 - 데이터 디렉터리 : 데이터 사전에 수록된 데이터에 접근하는데 필요한 정보를 관리, 유지하는 시스템 트랜잭션의 특성[원일독영] ★ ★ ★ ★ Atomicity(원자성) : 트랜잭션의 연산은 데이터베이스에 모두 반영 되도록 완료(Commit) 되든지, 아니면 전혀 반영 되지 않도록 복구(Rollback) 되어야 한다 Consistency(일관성) : 트랜잭션은 언제나 일관성 있는 결과 를 가져와야 한다. 시스템이 가지고 있는 고정 요소는 트랜잭션 수행 전 과 트랜잭션 수행 완료의 상태가 같아야 한다. Isolation(독립성) : 둘 이상의 트랜잭션이 동시에 병행 실행 되는 경우 어느 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없다 . 수행중인 트랜잭션은 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없다. Durability(영속성) : 성공적으로 완료된 트랜잭션 결과는 시스템에 고장나더라도 영구적으로 반영 되어야 한다. 트랜잭션 관련 ★ ★ ★ 병행 제어 : 다중 프로그램의 이점을 활용해 동시에 여러 개의 트랜잭션을 병행수행할 때 동시에 실행되는 트랜잭션들이 데이터베이스의 일관성을 파괴하지 않도록 트랜잭션 간의 상호작용을 제어 하는 것. - 로킹 : 트랜잭션들이 어떤 로킹 단위를 액세스 하기 전에 LOCK을 요청해서 LOCK이 허락되어야만 그 로킹 단위를 액세스 할 수 있도록 하는 기법. 액세스를 상호 배타적으로 함. - 타임스탬프 순서 : 시간표를 부여 해 부여된 시간에 따라 트랜잭션 작업을 수행 하는 기법. 트랜잭션 간의 처리 순서를 미리 선택하는 기법들 중에 가장 보편적인 방법. - 최적 병행수행 : 병행 수행 하고자 하는 트랜잭션이 판독 전용 트랜잭션 일 경우, 트랜잭션 간의 충돌률이 매우 낮아 이 트랜잭션은 시스템의 상태를 일관성 있게 유지 함. - 다중 버전 기법 : 타임 스탬프 의 개념을 이용하는 기법. 갱신될 때 마다 버전을 부여해 관리 함. * 로킹 단위 : 병행 제어에서 한꺼번에 로킹할 수 있는 개체의 크기 를 의미. 로킹 단위가 크면 로크 수가 작아 로킹 오버헤드와 데이터베이스 공유도가 감소함. 로킹 단위가 작아지면 병행성 수준이 높아짐. 고급 데이터베이스 ★ ★ 데이터 웨어하우스 : 급장하는 대량의 데이터를 효과적으로 분석해 정보화 하고 이를 여러 계층의 사용자들이 효율적으로 사용할 수 있도록 한 데이터베이스 데이터 마트 : 전사적으로 구축된 데이터 웨어하우스로부터 특정 주제나 부서 중심으로 구축 된 소규모 단일 주제의 데이터 웨어하우스 데이터 마이닝 : 데이터 웨어하우스에 저장된 데이터 집합에서 사용자의 요구에 따라 유용하고 가능성 있는 정보를 발견하기 위한 기법 OLAP(Online Analytical Processing) : 다차원으로 이루어진 데이터로부터 통계적인 요약정보를 분석해 의사 결정에 활용 하는 방식 OLTP(Online Transaction Processing) : 온라인 업무 처리 형태의 하나로 네트워크 상의 여러 이용자가 실시간으로 데이터베이스의 데이터를 갱신하거나 검색하는 등의 단위 작업을 처리 하는 방식 tpmC : DB기반 OLTP 미들웨어 시스템 서비스를 위한 H/W 성능을 측정 하기 위한 대표적 방법으로, 1분간의 최대 처리 건수 를 나타냄 옵티마이저 : SQL 을 가장 빠르고 효율적으로 수행할 최적(최저비용)의 처리경로를 생성 해주는 DBMS 내부의 핵심 엔진 무결성 ★ ★ 개체 무결성 : 기본 테이블의 기본키를 구성하는 어떤 속성도 Null 값이나 중복값을 가질 수 없다 는 규정 도메인 무결성 : 주어진 속성 값이 정의된 도메인에 속한 값이어야 한다는 규정. 참조 무결성 : 외래키 값은 Null이거나 참조 릴레이션의 기본키 값과 동일 해야 함. 즉 릴레이션은 참조할 수 없는 외래키를 가질 수 없다 는 규정 사용자 정의 무결성 : 속성 값들이 사용자가 정의한 제약조건에 만족해야 한다는 규정 NULL 무결성 : 릴레이션의 특정 속성 값이 NULL이 될 수 없도록 하는 규정 고유 무결성 : 릴레이션의 특정 속성에 대해 각 튜플이 갖는 속성 값들이 서로 달라야 한다는 규정 키 무결성 : 하나의 릴레이션에는 적어도 하나의 키가 존재해야 한다는 규정 관계 무결성 : 릴레이션에 어느 한 튜플의 삽입 가능 여부 또는 한 릴레이션과 다른 릴레이션의 튜플들 사이의 관계에 대한 적절성 여부를 지정한 규정 SQL 응용 ★ ★ ★ 프로시저 구성 : DECLARE/ BEGIN/ END/ CONTROL/ SQL/ EXCEPTION/ TRANSACTION [디비엔컨SET] -> 절차형 SQL문을 활용해 사전에 정의해놓은 SQL문을 호출할 경우 특정 기능을 수행하는 트랜잭션 언어
사용자 정의함수 구성 : DECLARE / BEGIN / END / CONTROL / SQL / EXCEPTION/ RETURN [디비엔컨SER]
-> 사용자가 정의해 SQL문 처리 수행 후 단일 값으로 반환하는 절차형 SQL
트리거 구성 : DECLARE / EVENT / BEGIN /END / CONTROL / SQL / EXCEPTION [디이비엔컨SE]
-> 특정 테이블에 수정, 삭제, 삽입 등의 데이터 이벤트 발생시 자동으로 DBMS에서 실행되도록 구현된 프로그램
그룹 함수 ★ ★
그룹 함수 : 소 그룹 간의 중간 합계, 소계를 계산하여 산출하는 함수. GROUP BY 뒤에 쓰고, SUM, AVG, COUNT 와 같은 그룹함수와 함께 쓰임
– ROLLUP : 소계, 중간 집계 값 산출
– CUBE : 다차원 집계 생성
– GROUPING SET : 컬럼에 대한 개별 집계
– HAVING 조건 : ‘ GROUP BY 컬럼 HAVING 조건 ‘으로 쓰고, 그룹에 조건을 추가할 때 사용
윈도우 함수 ★ ★
윈도우 함수 : 데이터베이스를 사용한 온라인 분석 처리 용도로 사용 하기 위해 SQL에 추가한 함수. OVER 명령어 . GROUP BY 절을 이용하지 않고, 함수의 인수로 지정한 속성의 값을 집계함수의 인수로 지정한 속성이 집계할 범위가 되는데, 이를 윈도우라고 함.
ex) SELECT WINDOW_FUNCTION (ARGUMENTS) OVER ( [PARTITION BY 칼럼]] [ORDER BY 절] [WINDOWING 절] ) FROM 테이블 명;
– ROW_NUMBER() : 윈도우 별로 각 레코드에 대한 일련번호를 반환.
– RANK(): 윈도우별로 순위를 반환. 공동 순위를 반영.
– DENSE_RANK(): 윈도우별로 순위를 반환, 공동 순위를 무시하고 순위를 부여.
인덱스 ★ ★
데이터 레코드를 빠르게 접근하기 위해 키 값, 포인터 쌍으로 구성되는 데이터 구조 . 인덱스는 데이터가 저장된 물리적 구조와 밀접한 관계. 레코드가 저장된 물리적 구조에 접근하는 방법 제공. 인덱스를 통해 파일 레코드에 대한 액세스를 빠르게 수행. 인덱스가 없으면 TABLE SCAN (특정한 값을 찾기위해 모든 데이터 페이지를 확인)이 발생.
– 트리 기반 인덱스 : 인덱스를 저장하는 블록들이 트리 구조 를 이루는 것으로, 상용 DBMS에서는 트리 구조 기반의 B+트리 인덱스를 주로 활용
– 비트맵 인덱스 : 인덱스 컬럼의 데이터를 Bit 값인 0또는 1로 변환 해 인덱스 키로 사용하는 방법. 비트맵 인덱스의 목적은 키 값을 포함하는 로우의 주소를 제공하는 것. 분포도가 좋은 컬럼에 적합하며 성능 향상 효과를 기대할 수 있음.
– 함수 기반 인덱스 : 컬럼의 값 대신 컬럼에 특정 함수나 수식을 적용해 산출된 값을 사용 하는 것으로, B+ 트리 인덱스나 비트맵 인덱스를 생성해 사용. 데이터를 입력하거나 수정할 때 함수를 적용해야 하므로 부하가 발생할 수 있음.
– 도메인 인덱스 : 개발자가 필요한 인덱스를 직접 만들어 사용 하는 것. 확장형 인덱스(Extensible Index)라고도 함.
클러스터드 인덱스 : 인덱스 키의 순서에 따라 데이터가 정렬 되어 저장되는 방식
넌클러스터드 인덱스 : 인덱스의 키 값만 정렬되어 있고, 실제 데이터는 정렬되지 않은 방식 .
뷰(View) ★ ★ ★
사용자에게 접근이 허용된 자료만을 제한적 으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된 이름을 가지는 가상 테이블 . 뷰는 데이터 보정 작업, 처리 과정 시험 등 임시적인 작업을 위한 용도로 활용된다. 뷰는 가상 테이블이기 때문에 물리적 구현이 없고, 데이터의 논리적 독립성을 제공한다. CREATE와 DROP문 을 사용.
클러스터 ★ ★ ★
데이터 저장 시 데이터 액세스 효율을 향상 시키기 위해 동일한 성격의 데이터를 동일한 데이터 블록에 저장 하는 물리적 저장 방법. 클러스터링된 테이블은 데이터 조회 속도 향상시키지만 데이터 입력, 수정, 삭제에 대한 성능은 저하 시킨다. 클러스터는 데이터의 분포도가 넓을수록 유리.
처리 범위가 넓은 경우엔 단일 테이블 클러스터링, 조인이 많이 발생하는 경우엔 다중 테이블 클러스터링.
파티션 설계 ★ ★ ★
대용량 테이블이나 인덱스를 작은 논리적 단위인 파티션으로 나누는 것 . 대용량 DB의 경우 중요한 몇 개의 테이블에만 집중되어 데이터가 증가되므로, 이런 테이블들을 작은 단위로 나눠 분산시키면 성능 저하를 방지할 뿐만 아니라 데이터 관리도 쉬워진다. 테이블이나 인덱스를 파티셔닝 하면 파티션키나 인덱스키에 따라 물리적으로 별도의 공간에 데이터가 저장된다. 데이터 처리는 테이블 단위로 이뤄지고, 데이터 저장은 파티션 별로 수행된다. 범위(Range) , 해시(Hash), 합성(Composite)
분산 데이터베이스 ★ ★ ★
논리적으로는 하나의 시스템에 속하지만 물리적(여러 지역으로)으로는 네트워크 를 통해 연결된 여러 개의 컴퓨터 사이트에 분산되어 있는 데이터베이스 [위중병장]
– 위치 투명성 : 액세스 하려는 데이터베이스의 실제 위치를 알 필요 없이 단지 데이터베이스의 논리적 명칭만으로 액세스 할 수 있음
– 중복 투명성 : 동일 데이터가 여러 곳에 중복 되어 있더라도 사용자는 마치 하나의 데이터만 존재하는 것처럼 사용 하고, 시스템은 자동으로 여러 자료에 대한 작업을 수행한다.
– 병행 투명성 : 분산 데이터베이스와 관련된 다수의 트랜잭션들이 동시에 실현되더라도 그 트랜잭션의 결과는 영향을 받지 않는다 .
– 장애 투명성 : 트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 불구하고 트랜잭션을 정확하게 처리 한다.
분산 설계 방법 ★
– 테이블 위치 분산 : 데이터베이스의 테이블을 각기 다른 서버에 분산시켜 배치
– 분할 : 테이블의 데이터를 분할 해 분산. 완전성, 재구성, 상호 중첩 배제.
– 할당 : 동일한 분할을 여러 개의 서버에 생성하는 분산 방법.
NoSQL(Not Only SQL) ★ ★ ★
전통적인 RDBMS와 다른 DBMS를 지칭하기 위한 용어로, 데이터 저장에 고정된 테이블 스키마가 필요하지 않고 조인 연산을 사용할 수 없으며, 수평적으로 확장이 가능한 DBMS으로, Basically Availale, Soft-state, Eventually Consistency의 특성이 있음
– 테이블 스키마 필요 X, 조인 연산 사용 X, 수평적 확장 O
CRUD Matrix : 프로세스와 데이터 사이에 관계 의존성 을 Create, Read, Update, Delete로 표현한 매트릭스
쿼리 요약 ★ ★ ★ ★ ★
INSERT INTO 테이블(컬럼1,컬럼2,…) VALUES(A,B,C)
UPDATE 테이블 SET A = B WHERE ~
DELETE FROM 테이블 WHERE ~
SELECT DISTINCT NVL(컬럼, 바꿀텍스트) WHERE 컬럼 BETWEEN a AND b(a와 b사이의 결과)
WHERE 컬럼 IN(a,b)(괄호 안에 값 중 일치하는 데이터를 출력)
DESCRIBE : 테이블 또는 뷰의 구조를 조회할때 사용되는 명령어
CREATE VIEW 뷰이름 (속성명) AS SELECT 컬럼 FROM 테이블 WHERE 조건
CREATE SCHEMA 스키마명 AUTHORIZATION 사용자_ID
CREATE DOMAIN 데이터 타입 DEFAULT 기본값 CONSTRAINT 제약조건명 CHECK (VALUE IN 범위값);
CREATE UNIQUE INDEX 고객번호_IDX ON 고객(고객번호 DESC);
CREATE TABLE 테이블명 (이름 VARCHAR(15) NOT NULL, 학번 CHAR(8), PRIMARY KEY(학번), FOREIGN KEY (전공) REFERENCES 학과(학과코드)
ON DELETE SET NULL(테이블에서 튜플이 삭제되면 NULL로 변경) ON UPDATE CASCADE(관련된 모든 속성도 같은 값으로 변경) ,
CONSTRAINT 생년월일제약 CHECK (생년월일>=’1980-01-01’));
ALTER TABLE 테이블명 ADD 속성명 / ALTER 속성명 / DROP COLUMN 속성명
테이블 수정 ★ ★ ★ ★ ★
컬럼 추가 : ALTER TABLE 테이블 ADD (컬럼, 속성)
컬럼 삭제 : ALTER TABLE 테이블 DROP COLUMN (컬럼명)
컬럼명 수정 : ALTER TABLE 테이블 RENAME COLUMN 기존 컬럼명 TO 새로운 컬럼명
제약 조건 : CONSTRAINT 제약조건이름 PRIMARY KEY (제약 컬럼)
회복 ★ ★ ★ ★
트랜잭션들을 수행하는 도중 장애 발생해 데이터베이스가 손상되었을 때 손상되기 이전의 정상 상태로 복구 하는 작업
– 연기 갱신 기법 : 트랜잭션이 성공적으로 완료될때까지 데이터베이스에 대한 실질적인 갱신을 연기 하는 방법. 트랜잭션의 부분 완료 시점에 LOG에 보관한 갱신 내용을 실제 데이터베이스에 기록함. REDO 작업만 가능 .
– 즉각 갱신 기법 : 트랜잭션이 데이터를 갱신하면 트랜잭션이 부분 완료되기 전이라도 즉시 실제 데이터베이스에 반영 하는 방법. 장애가 발생해 회복 작업을 할 경우를 대비해 갱신된 내용들을 LOG에 보관 시킴. REDO와 UNDO 모두 사용 가능 함.
– 그림자 페이지 대체 기법 : 갱신 이전의 데이터베이스를 일정 크기의 페이지 단위로 구성 해, 각 페이지마다 복사본인 그림자 페이지를 별도 보관 해 놓고, 실제 페이지를 대상으로 갱신 작업을 수행하다가 장애가 발생해 트랜잭션 작업을 ROLLBACK 시킬 때는 갱신 이후에 실제 페이지 부분을 그림자 페이지로 대체해 회복 시키는 방법.
– 검사점 기법 : 트랜잭션 실행 중 특정 단계에서 재실행 할 수 있도록 갱신 내용이나 시스템에 대한 상황 등에 관한 정보와 함께 검사점을 로그에 보관 해 두고, 장애 발생시 트랜잭션 전체를 철회하지 않고 검사점부터 회복 작업을 수행해 회복시간을 절약하는 방법.
데이터베이스 이중화 ★ ★
데이터베이스 이중화 : 서비스 중단이나 물리적 손상 발생시 이를 복구하기 위해 동일한 데이터베이스를 복제하여 관리하는 것.
– Eager 기법 : 트랜잭션 수행 중 데이터변경이 발생하면 이중화된 모든 데이터베이스에 즉시 전달 해 변경내용이 즉시 적용되도록 하는 기법.
– Lazy 기법 : 트랜잭션 수행이 종료되면 변경 사실을 새로운 트랜잭션에 작성 해 각 데이터베이스에 전달 되는 기법.
클러스터링 : 두대 이상의 서버를 하나의 서버처럼 운영하는 기술
– 고가용성 클러스터링 : 하나의 서버에 장애가 발생하면 다른 노드가 받아 처리해 서비스 중단을 방지.
– 병렬 처리 클러스터링 : 전체 처리율을 높이기 위해 하나의 작업을 여러개의 서버에서 분산해 처리하는 방식.
접근통제 ★ ★ ★
접근통제 : 데이터가 저장된 객체와 이를 사용하려는 주체 사이의 정보 흐름을 제한 하는 것.
– 임의 접근통제(DAC) : 데이터에 접근하는 사용자의 신원 에 따라 접근 권한을 부여하는 방식. 데이터 소유자 .
– 강제 접근통제(MAC) : 주체와 객체의 등급 을 비교해 접근 권한을 부여하는 방식. 시스템 .
– 역할기반 접근통제(RBAC) : 사용자의 역할 에 따라 접근 권한을 부여하는 방식. 중앙관리자 .
* 주체가 데이터 소유자=DAC, 시스템=MAC, 중앙관리자=RBAC입니다.
접근 통제 정책 ★
– 신분 기반 정책 : 주체나 그룹의 신분에 근거해 객체의 접근을 제한. IBP와 GBP가 있음.
– 규칙 기반 정책 : 주체가 갖는 권한에 근거해 객체의 접근을 제한하는 방법으로, MLP와 CBP가 있음.
– 역할 기반 정책 : GBP의 변형된 정책으로, 주체의 신분이 아니라 주체가 맡은 역할에 근거해 객체의 접근을 제한.
접근 통제 조건 ★
– 값 종속 통제 : 일반적으로 객체에 저장된 값에 상관없이 접근 통제를 동일하게 허용하지만, 객체에 저장된 값에 따라 다르게 접근 통제를 허용하는 경우에 사용
– 다중 사용자 통제 : 지정된 객체에 다수의 사용자가 동시에 접근을 요구하는 경우 사용.
– 컨텍스트 기반 통제 : 특정 시간, 네트워크 주소, 접근 경로, 인증 수준 등에 근거해 접근을 제어하는 방법.
– 감사 추적 : 사용자나 애플리케이션이 데이터베이스에 접근해 수행한 모든 활동을 기록 하는 기능.
인터페이스 구현
아키텍처 패턴 ★ ★ ★
아키텍처를 설계할 때 참조할 수 있는 전형적인 해결 방식 또는 예제
레이어 패턴 : 시스템을 계층으로 구분하여 구성하는 패턴
클라이언트-서버 패턴 : 하나의 서버 컴포넌트와 다수의 클라이언트 컴포넌트로 구성되는 패턴
파이프-필터 패턴 : 데이터 스트림 절차의 단계를 필터로 캡슐화해 파이프를 통해 전송하는 패턴
모델-뷰-컨트롤러 패턴 : MVC
기타 패턴
마스터-슬레이브 패턴 : 슬레이브 컴포넌트에서 처리된 결과물을 돌려받는 방식의 패턴
브로커 패턴 : 브로커가 요청에 맞는 컴포넌트와 사용자를 연결
피어-투-피어 패턴 : 하나의 컴포넌트가 클라이언트가 될수도, 서버가 될수도 있는 패턴
이벤트-버스 패턴 : 채널에 발행과 구독. Subscribe, Publish.
블랙보드 패턴 : 모든 컴포넌트들이 데이터 저장소와 블랙보드 컴포넌트에 접근이 가능한 패턴.
공통모듈 ★ ★ ★ ★ ★
공통모듈 : 여러 프로그램에서 공통으로 사용하는 모듈
공통모듈 명세기법 종류
정확성 : 시스템 구현시 해당 기능이 필요하다 는 것을 알수 있도록 정확히 작성
명확성 : 해당 기능을 이해할 때 중의적으로 해석하지 않도록 함
완전성 : 시스템 구현을 위해 필요한 모든 것 을 기술
일관성 : 공통 기능들 간 상호 충돌 이 발생하지 않도록 함
추적성 : 기능에 대한 요구사항 출처 , 관련 시스템 간의 관계를 파악.
재사용 : 이미 개발된 기능 들을 새로운 시스템 이나 기능 개발에 사용하기 적합하도록 최적화 함.
디자인 패턴 ★ ★ ★ ★ ★
생성 패턴
추상 팩토리 : 인터페이스 를 통해 서로 의존하는 객체들의 그룹으로 생성, 추상적 으로 표현.
빌더 : 분리된 인스턴스를 건축 하듯이 조합 해 객체를 생성
팩토리 메소드 : 상위 클래스에서 인터페이스만 정의하고 실제 생성은 서브클래스가 담당 함.
프로토타입 패턴 : 원본을 만들어놓고 원본 객체를 복사 해서 사용하는 패턴
싱글톤 : 전역 변수 를 사용하지 않고 객체를 하나만 생성하도록 해서 생성된 객체를 어디에서든지 참조할 수 있도록 만든 패턴
구조 패턴
어댑터 : 호환성이 없는 클래스 들을 다른 클래스가 이용 할 수 있도록 변환
브리지 : 구현부 에서 추상층 을 분리 해 서로가 독립적으로 확장
컴포지트 : 복합 객체 와 단일 객체 를 구분없이
데코레이터 : 객체 간의 결합 을 통해 기능을 확장
퍼싸드 : 복 잡한 기능의 서브클래스 의 상위에 인터페이스를 생성 해 간편하게 기능을 사용
플라이웨이트 : 인스턴스를 공유해 메모리 를 절약
프록시 : 접근이 어려운 객체 들 사이에서 인터페이스 역할
행위 패턴
책임 연쇄 : 객체가 둘 이상 존재해 한 객체가 처리하지 못하면 다음 객체 로 넘어가는 패턴
커맨드 : 요청에 사용되는 명령어 를 추상 클래스와 구체 클래스로 분리해 단순화
인터프리터 : 언어에 문법 표현 을 정의하는 패턴
반복자 : 접근이 잦은 객체 에 동일한 인터페이스를 사용하도록 하는 패턴
중재자 : 수많은 객체 간의 복잡한 상호작용을 캡슐화 해 객체로 정의하는 패턴
메멘토 : 특정 시점의 객체의 상태를 Crtl+z 와 같은 되돌리기 기능으로 해당 시점으로 돌리는 기능을 제공
옵저버 : 한 객체의 상태가 변화하면 변화한 상태를 다른 객체 에게 전달. 일대 다의 의존성을 정의. Publish, Subscribe
상태 : 객체의 상태에 따라 동일한 동작을 다르게 처리
전략 : 동일한 계열의 알고리즘 을 개별적으로 캡슐화해, 상호교환 할 수 있게 정의. 알고리즘.
템플릿 메소드 : 상위 클래스에서 골격 을 정의, 하위 클래스에서 세부처리를 구체화 함.
방문자 : 각 클래스 들의 데이터 구조에서 처리 기능을 분리 해 별도의 클래스로 구성.
미들웨어 ★ ★ ★
운영체제와 응용 프로그램, 서버와 클라이언트 사이에 다양한 서비스를 제공하는 소프트웨어
RPC : 원격 프로시저 를 로컬 프로시저 처럼 호출하는 미들웨어
MOM : 메시지 기반의 비동기형 메시지 를 전달하는 미들웨어
TP-Monitor : 온라인 트랜잭션 업무에서 트랜잭션을 처리, 감시 하는 미들웨어
ORB : 코바(CORBA) 표준 스펙을 구현한 객체 지향 미들 웨어
WAS : 사용자의 동적인 콘텐츠 를 처리하기 위한 미들웨어
웹 서비스 ★ ★ ★
UDDI : WSDL을 등록해 서비스와 서비스 제공자를 검색 하고 접근하는데 사용됨
WSDL : 웹 서비스명, 서비스 제공위치, 프로토콜 등 웹서비스에 대한 상세정보를 XML형식으로 명세 (구현)
인터페이스 보안 ★ ★ ★
IPSec : 네트워크 계층에서 IP 패킷 단위의 데이터 변조 방지, 은닉 기능 을 제공하는 보안 통신 규약
SSL(Secure Sockets Layer) : 애플리케이션 계층과 TCP/IP 계층 사이에서 인증, 암호화, 무결성 을 보장하는 공개키 기반의 보안 프로토콜. Certificate Authority(CA)라 불리는 서드 파티로부터 서버와 클라이언트를 인증하는데 사용됨.
S-HTTP : 클라이언트와 서버 간에 전송되는 모든 메시지를 암호화 하는 프로토콜
인터페이스 구현 검증 도구 ★ ★ ★
xUnit : Java(Junit), C++(Cppunit), .Net(Nunit) 등 다양한 언어를 지원하는 단위 테스트 프레임워크
STAF : 서비스 호출, 컴포넌트 재사용 등 다양한 환경을 지원하는 테스트 프레임워크로 각 테스트 대상 분산 환경에 데몬 을 사용해 테스트 대상 프로그램을 통해 테스트를 수행하고 통합해 자동화 하는 검증 도구
FitNess : 웹 기반 테스트케이스 설계, 실행, 결과 확인 등을 지원하는 테스트 프레임워크
NTAF : FitNess의 장점인 협업 기능 + STAF의 장점인 재사용 및 확장성을 통합한 NHN(Naver)의 테스트 자동화 프레임워크
Selenium : 다양한 브라우저 및 개발언어를 지원하는 웹 애플리케이션 테스트 프레임워크
Watir : Ruby 를 사용하는 애플리케이션 테스트 프레임워크
APM : 애플리케이션의 성능 관리를 위해 접속자, 자원 현황, 트랜잭션 수행 내역 등 다양한 모니터링 기능을 제공하는 도구
– 스카우터 : 애플리케이션 및 OS 자원에 대한 모니터링 기능 제공
– 제니퍼 : 개발부터 테스트, 오픈, 운영, 안정화 까지 전 단계에 걸쳐 모니터링 및 분석
화면 설계
UI 설계원칙 ★ ★ ★ ★ ★
직관성 : 누구나 쉽게 이해 하고 사용할 수 있어야 함
유효성 : 사용자의 목적 을 정확하고 완벽하게 달성 해야 함
학습성 : 누구나 쉽게 배우고 익힐 수 있어야 함
유연성 : 사용자의 요구사항을 최대한 수용 하고 실수를 최소화 해야 함
UI 설계 도구[와목스프유] ★ ★ ★ ★
와이어프레임 : 기획 단계에 초기에 제작하는 것. 페이지에 대한 개략적인 레이아웃이나 UI 요소등에 뼈대 를 설계. 각 페이지의 영역 구분, 콘텐츠, 텍스트 배치 등을 화면 단위로 설계.
– 종류 : 손 그림, 파워포인트, 키노트, 스케치, 일러스트, 포토샵 등
목업 : 디자인, 사용방법 설명, 평가 등을 위해 와이어 프레임보다 좀 더 실제 화면과 유사 하게 제작한 정적 인 형태의 모형. 시각적으로만 구성 요소를 배치
– 종류 : 파워 목업, 발사믹 목업
스토리보드 : 와이어프레임에 콘텐츠에 대한 설명, 페이지 간 이동 흐름(인터랙션) 을 추가한 문서. 디자이너와 개발자가 최종적으로 참고하는 구체적인 작업 지침서로, 정책, 프로세스 콘텐츠 구성, 와이어 프레임, 기능 정의 등 서비스 구축을 위한 모든 정보가 들어 있음. 상단이나 우측에는 제목, 작성자를 입력. 좌측에는 UI 화면, 우측에는 디스크립션(설명)을 기입
– 종류 : 파워포인트, 키노트 스케치, Axure
프로토타입 : 와이어프레임이나 스토리보드 등에 인터랙션을 적용함으로 실제 구현된것처럼 테스트가 가능 한 동적 인 형태의 모형.
– 종류 : HTML/css, Axure, Flinto, 네이버 프로토나우, 카카오 오븐 등
유스케이스 : 사용자 측면에서의 요구사항으로, 목표를 달성하기 위해 수행할 내용을 기술 . 사용자의 요구사항을 빠르게 파악함으로 프로젝트 초기에 시스템의 기능적인 요구를 결정하고 그 결과를 문서화함. 자연어로 작성된 사용자의 요구사항을 구조적으로 표현한 것 -> 다이어그램 으로 묘사.
소프트웨어 품질 요구사항[기신사효유이] ★ ★ ★
기능성 : 소프트웨어가 사용자의 요구사항을 정확하게 만족 하는 기능을 제공하는 여부 (정합성, 정확성, 상호운용성, 보안성, 호환성)
신뢰성 : 소프트웨어가 요구된 기능을 정확하고 일관되게 오류 없이 수행할 수 있는 정도(성숙성, 고장허용성, 회복성)
사용성 : 사용자와 컴퓨터 사이에 발생하는 어떠한 행위에 대하여 사용자가 정확하게 이해하고 사용하며, 향후 다시 사용하고 싶은 정도 (이해성, 학습성, 운용성, 친밀성)
효율성 : 사용자가 요구하는 기능을 할당된 시간 동안 한정된 자원 으로 얼마나 빨리 처리할 수 있는 정도(시간효율성, 자원효율성)
유지보수성 : 환경의 변화 또는 새로운 요구사항이 발생했을 때 소프트 웨어를 개선하거나 확장 할 수 있는 정도(분석성, 변경성, 안정성, 시험성)
이식성 : 소프트웨어가 다른 환경에서도 얼마나 쉽게 적용 (적응)할 수 있는 정도(적용성, 설치성, 대체성, 공존성)
애플리케이션 테스트 관리
애플리케이션 테스트 기본 원리 ★ ★ ★ ★ ★
파레토 법칙 : 애플리케이션의 20% 에 해당하는 코드의 전체 결함의 80% 가 발견되는 법칙
살충제 패러독스 : 동일한 테스트 케이스로 동일한 테스트를 반복 하면 더 이상 결함 이 발견되지 않음
오류 부재의 궤변 : 결함을 모두 제거 해도 사용자의 요구사항 을 만족하지 못하면 품질 이 높다고 말할 수 없음
프로그램 실행 여부에 따른 애플리케이션 테스트 ★
정적 테스트 : 프로그램을 실행하지 않고 명세서 나 소스 코드 대상으로 분석하는 테스트
동적 테스트 : 프로그램을 실행해 오류 를 찾는 테스트로, 소프트웨어 개발 모든 단계에서 테스트를 수행할 수 있음
테스트 기반 테스트 ★ ★
명세 기반 테스트 : 사용자 요구사항의 명세 를 빠짐 없이 테스트 케이스로
구조 기반 테스트 : 소프트웨어 내부의 논리 흐름 에 따라 테스트 케이스를 작성
경험 기반 테스트 : 유사 소프트웨어나 기술 등에 대한 테스터의 경험 을 기반
목적에 따른 테스트[회안강성구회병] ★ ★ ★ ★
회복 테스트 : 시스템에 여러가지 결함 을 주어 실패하도록 한 후 올바르게 복구 되는지 테스트
안전 테스트 : 시스템에 설치된 시스템 보호 도구가 불법적인 침입으로부터 시스템을 보호 할 수 있는지 테스트
강도 테스트 : 과도한 정보량이나 빈도 등을 부과 하여 과부하 시에도 소프트웨어가 정상적으로 실행되는지를 확인하는 테스트
성능 테스트 : 소프트웨어 실시간 성능 이나 전체적인 효율성을 진단하는 테스트로 소프트웨어의 응답시간, 처리량 등을 테스트한다.
구조 테스트 : 소프트웨어 내부의 논리적인 경로 , 소스 코드의 복잡도 등을 평가하는 테스트다.
회귀 테스트 : 소프트웨어 변경 또는 수정된 코드에 새로운 결함이 없음을 확인 하는 테스트다.
병행 테스트 : 동일한 데이터를 입력하여 수정 전과 수정 후 의 결과를 비교하는 테스트다.
화이트박스 테스트의 제어 구조 검사 ★
조건 검사 : 프로그램 모듈 내에 있는 논리적 조건 을 테스트하는 테스트 케이스 설계 기법
루프 검사 : 프로그램의 반복 구조 에 초점을 맞춰 실시하는 테스트 케이스 설계 기법
데이터 흐름 검사 : 프로그램에서 변수의 정의와 변수 사용의 위치에 초점 을 맞춰 실시하는 테스트 케이스 설계 기법
화이트 박스 테스트 검증 기준 ★ ★ ★ ★
구문 커버리지(Statement Coverage) : 테스트 스위트에 의해 실행된 구문이 몇 퍼센트인지 측정 하는 것. 다른 커버리지에 비해 가장 약함
결정 커버리지(Decision Coverage, Branch Coverage) : 테스트 스위트에 의해 실행된 결정 포인트 내의 전체 조건식이 최소한 참(True)이 한번, 그리고 거짓(False)이 한번의 값을 갖는지 측정하여 퍼센트로 표현하는 것. 개별 조건식의 개수와 상관없이 테스트 케이스의 최소 개수는 2 개. 조건, 조건/결정 커버리지에 비해 약함
조건 커버리지(Condition Coverage) : 전체 조건식의 결과와 관계없이 각 개별 조건식이 참 한번, 거짓 한번을 모두 갖도록 개별 조건식을 조합하는 것. 결정 커버리지 보다 강력한 형태의 커버리지.
조건/결정 커버리지(Condition/Decision Coverage) : 전체 조건식의 결과가 참 한번, 거짓 한번을 갖도록 각 개별 조건식을 조합하는데, 이때 각 개별 조건식도 참 한번, 거짓 한번을 모두 갖도록 개별 조건식을 조합하는 것으로 결정 커버리지와 조건 커버리지를 포함하는 커버리지.
변경조건/결정 커버리지(Modify Condition/Decision Coverage) : Mc/DC는 각 개별 조건식이 다른 개별 조건식에 무관하게 전체 조건식의 결과에 독립적으로 영향을 주도록 함으로써 조건/결정 커버리지를 향상시킨 것. 결정 커버리지, 조건/결정 커버리지 보다 강력
다중조건 커버리지(Multiple Condition Coverage) : 결정 포인트 내에 있는 모든 개별 조건식의 모든 가능한 논리적 조합을 고려한 가장 강력한 논리적 수준의 100% 커버리지를 보장.
블랙박스 테스트 기법[동경결상 유분페] ★ ★ ★ ★ ★
동등 분할 테스트 : 입력 데이터(입력 값) 의 영역을 유사한 도메인별로 유효 값 / 무효 값을 그룹핑하여 대푯값 테스트 케이스를 도출하여 테스트하는 기법
경계 값 분석 테스트 : 동기분할 후 경계 값 부분에서 오류 발생 확률이 높기에 경계 값을 포함하여 테스트 케이스를 설계하여 테스트하는 기법(범위)
결정 테이블 테스트 : 요구사항의 논리와 발생조건을 테이블 형태로 나열 하여, 조건과 행위를 모두 조합하여 테스트하는 기법
결정 테이블 테스트
상태전이 테스트 : 테스트 대상/시스템이나 객체의 상태 를 구분하고, 이벤트에 의해 어느 한 상태에서 다른 상태로 전이되는 경우의 수를 수행하는 테스트 기법
상태전이 테스트
유스케이스 테스트 : 시스템이 실제 사용되는 유스케이스로 모델링 되어 있을 때 프로세스 흐름을 기반으로 테스트 케이스를 명세화하여 수행하는 테스트 기법
분류트리 테스트 : SW의 일부 또는 전체를 트리 구조 로 분석 및 표현하여 테스트케이스를 설계하여 테스트하는 기법
분류 트리 테스트
페어와이즈 테스트 : Test Data 값들 간에 최소한 한 번 씩을 조합 하는 방식이며, 이는 커버해야 할 기능적 범위를 모든 조합에 비해 상대적으로 적은 양의 테스트 세트를 구성하기 위한 테스트 기법
페어와이즈 테스트
테스트 오라클 ★ ★ ★ ★ ★
참 오라클 : 모든 테스트 케이스의 입력 값 에 대해 기대하는 결과를 제공하는 오라클로, 발생된 모든 오류를 검출 할 수 있음
샘플링 오라클 : 특정한 몇몇 테스트 케이스의 입력 값 들에 대해서만 기대하는 결과를 제공하는 오라클
추정 오라클 : 샘플링 오라클을 개선한 오라클로, 특정 테스트 케이스의 입력값에 대해 기대하는 결과를 제공하고, 나머지 입력 값들에 대해서는 추정으로 처리 하는 오라클
일관성 검사 오라클 : 애플리케이션의 변경이 있을 때, 테스트 케이스의 수행 전과 후의 결과 값이 동일 한지를 확인하는 오라클
테스트 하네스 구성요소 ★ ★ ★ ★ ★
* 테스트 하네스 : 애플리케이션의 컴포넌트 및 모듈을 테스트 하는 환경의 일부분으로 테스트를 지원하기 위해 생성된 코드와 데이터를 의미 하며, 테스트가 실행될 환경을 시뮬레이션하며 컴포넌트 및 모듈이 정상적으로 테스트 되도록 하는 도구. 코드 개발자 가 작성하는 요소임.
테스트 드라이버 : 테스트 대상의 하위 모듈을 호출 하고, 파라미터를 전달 하고, 모듈 테스트 후 결과를 도출하는 도구
테스트 스텁 : 제어 모듈이 호출하는 타 모듈의 기능을 단순히 수행하는 도구 로, 일시적으로 필요한 조건 만을 가지고 있는 테스트용 모듈
테스트 슈트 : 테스트 대상 컴포넌트나 모듈, 시스템에 사용되는 테스트 케이스의 집합
테스트 케이스 : 사용자의 요구사항을 정확하게 준수했는지 확인하기 위한 입력 값, 실행 조건, 기대 결과 등으로 만들어진 테스트 항목의 명세서
테스트 스크립트 : 자동화된 테스트 실행 절차 에 대한 명세서
목 오브젝트 : 사전에 사용자의 행위를 조건부로 입력 해두면, 그 상황에 맞는 예정된 행위를 수행하는 객체
연계 테스트 ★ ★
구축된 연계시스템과 연계 시스템의 구성요소가 정상적으로 동작하는지 확인하는 활동
연계 테스트 케이스 작성 : 연계 시스템 간의 데이터 및 프로세스의 흐름을 분석해 필요한 테스트 항목을 도출하는 과정
연계 테스트 환경 구축 : 테스트의 일정, 방법, 절차, 소요 시간 등을 송수신 기관과의 협의를 통해 결정하는 것
연계 테스트 수행 : 연계 응용 프로그램을 실행해 연계 테스트 케이스의 시험 항목 및 처리 절차 등을 실제로 진행하는 것
연계 테스트 수행 결과 검증 : 예상 결과와 동일한지를 확인 하는 것
애플리케이션 테스트 ★ ★ ★
소프트웨어 개발 단계 : 요구사항 -> 분석 -> 설계 -> 구현
테스트 단계 : 단위 테스트 -> 통합 테스트 -> 시스템 테스트 -> 인수 테스트[단통시인]
개발 단계에 따른 애플리케이션 테스트 ★ ★ ★
단위 테스트 : 코딩 직후 소프트웨어 설계의 최소 단위인 모듈 이나 컴포넌트 에 초점을 맞춰 테스트 하는 것. 인터페이스, 외부적 입출력, 자료 구조, 독립적 기초 경로, 오류 처리 경로, 경계 조건 등을 검사. 사용자의 요구사항을 기반으로 한 기능성 테스트를 최우선으로 수행. 구조 기반 테스트와 명세 기반 테스트로 나뉘고, 주로 구조 기반 테스트 를 수행
통합 테스트 : 단위 테스트가 완료된 모듈들을 결합해 하나의 시스템으로 완성 시키는 과정에서의 테스트며, 과정에서 발생하는 오류 및 결함을 찾는 테스트
– 빅뱅 통합 테스트 : 모듈 간의 상호 인터페이스를 고려하지 않고, 모듈을 한꺼번에 결합시켜 테스트 하는 방법.
– 하향식 통합 테스트 : 상위에서 하위 모듈로. 스텁(제어 모듈의 종속 모듈). 깊이 우선 통합, 넓이 우선 통합 사용
– 상향식 통합 테스트 : 하위에서 상위 모듈로. 클러스터(주요 제어 모듈과 관련된 종속 모듈의 그룹)
– 회귀 테스팅 : 통합 테스트로 인해 변경된 모듈이나 컴포넌트에 새로운 오류가 있는지 확인하는 테스트
시스템 테스트 : 개발된 소프트웨어가 해당 컴퓨터 시스템에서 완벽하게 수행 되는가 를 점검하는 테스트
인수 테스트 : 개발한 소프트웨어가 사용자의 요구사항을 충족하는지에 중점을 두고 테스트 – 알파 테스트 : 개발자의 장소에서 개발자 앞에서, 통제된 환경에서 사용자와 함께 테스트 – 베타 테스트 : 최종적으로 선정된 여러 명의 사용자가 직접 테스트
암호화 및 소프트웨어 보안 요약
SECURE SDLC ★ ★ ★
SECURE SDLC : 보안상 안전한 소프트웨어를 개발하기 위해 SDLC에 보안 강화를 위한 프로세스를 포함 한 것.
– CLASP 방법론 : 개념 관점, 역할기반 관점, 활동평가 관점, 활동구현 관점, 취약성 관점 등의 활동중심, 역할 기반의 프로세스로 구성된 집합체로서 이미 운영중인 시스템에 적용하기 적당한 소프트웨어 개발 보안 방법론
– SDL 방법론 : 마이크로소프트 사 에서 안전한 소프트웨어 개발을 위해 기존의 SDLC를 개선한 방법론.
– SEVEN TOUCHPOINTS : 실무적으로 검증 된 개발 보안 방법론 중 하나로 SW 보안의 모범 사례 를 SDLC에 통합한 소프트웨어 개발 보안 주기 방법론
소프트웨어 개발 보안 3대 요소[기무가인부] ★ ★ ★ ★ ★
기밀성 : 인가되지 않은 사용자 와 애플리케이션의 접근에 따른 정보 노출 차단
무결성 : 완전성, 일관성 . 데이터 훼손 및 파손이 되지 않아야 함.
가용성 : 지속적인 서비스를 유지하며, 인가받은 사용자는 언제나 시스템 정보와 자원을 사용 할 수 있음.
인증 : 자원을 사용하려는 사용자를 확인하는 모든 행위.
부인 방지 : 데이터를 송수신한 자가 송수신 사실을 부인할 수 없도록 송수신 증거 를 제공.
시큐어 코딩 : 구현 단계에서 발생할 수 있는 보안 취약점들을 최소화 하기 위해 보안 요소들을 고려해 코딩 하는 것
입력 데이터 검증 및 표현 ★ ★ ★
SQL 삽입 : 웹 응용 프로그램에 SQL을 삽입 해 내부 데이터베이스 서버의 데이터를 유출 및 변조 , 관리자 인증을 우회하는 보안 약점
크로스사이트 스크립팅(XSS) : 웹 페이지에 악의적인 스크립트를 삽입 해 방문자들의 정보를 탈취하거나, 비정상적인 기능 수행을 유발하는 보안 약점
메모리 버퍼 오버플로우 : 연속된 메모리 공간을 사용하는 프로그램에서 할당된 메모리의 범위를 넘어선 위치에 자료를 읽거나 쓰려고할때 발생하는 보안 약점. 적절한 버퍼의 크기를 설정하고, 설정된 범위의 메모리 내에서 올바르게 읽고 쓰도록 함으로 예방.
암호 알고리즘 ★ ★ ★ ★
개인키 암호화 기법
동일한 키로 데이터를 암호화하고 복호화하는 암호화 기법
Stream 암호화 방식 : 평문과 동일한 길이의 스트림을 생성하여 비트 단위로 암호화 ex) LFSR, RC4
Block 암호화 방식 : 한 번에 하나의 데이터 블록을 암호화 ex) DES, SEED, AES, ARIA
Hash 단방향 암호화 방식 : 임의의 길이의 입력 데이터나 메시지를 고정된 길이의 값이나 키로 변한하는 것 : SHA, MD5, N-NASH, SNEFRU
[Stream]LFSR(Linear Feedback Shift Register) : 현재 상태의 선형 연산을 통해 다음 상태를 생성하는 레지스터, XOR함수를 사용함
RC4(Rivest Cipher 4) : 평문 1바이트와 암호키 1바이트가 XOR 처리 되어 암호문 1바이트를 생성. 옥텟 단위 기반. 로널드 라이베스트가 제작. 전송 보안 계층(TLS/SSL)이나 WEB 등의 여러 프로토콜에 사용
[Block]DES : 미국 NBS 에서 발표한 개인키 암호화 알고리즘. 블록크기는 64비트 이며 키길이는 56비트 . 비공개키 알고리즘.
SEED : 한국인터넷진흥원(KISA) 에서 개발한 블록 암호화 알고리즘. 블록 크기 128비트 이며, 키 길이에 따라 128, 256 으로 분류
AES : 미국 표준 기술 연구소(NIST) 에서 발표한 개인키 암호화 알고리즘. 블록크기는 128비트 이며, 키 길이에 따라 128, 192, 256 으로 분류
ARIA : 국가 정보원 과 산학연협회 가 개발한 블록 암호화 알고리즘. 학계, 연구기관, 정부의 영문 앞글자로 구성되었으며 블록 크기는 128비트, 키 길이에 따라 128, 192, 256 으로 분류
RSA : MIT의 라이베스트, 샤미르, 애들먼에 의해 제안된 공개키 암호화 알고리즘. 큰 숫자를 소인수 분해 하기 어렵다는 것에 기반해 만들어짐.
[Hash]SHA(Secure Hash Algorithm) : 미국 국가 안보국(NSA) 이 1993년 처음으로 설계 했으며, 미국 국가 표준 으로 지정된 해시 암호화 알고리즘
MD5(Message-Digest algorithm 5) : 128비트 암호화 해시 함수 로, RFC 1321로 지정되어 있으며, 주로 프로그램이나 파일이 원본 그대로인지를 확인하는 무결성 검사 등에 사용된다. 1991년에 로널드 라이베스트가 예전에 쓰이던 MD4를 대체하기 위해 고안함.
HAS-160 : 국내 표준 전자서명 알고리즘인 KCDSA에 사용되는 160비트 암호학적 해시 함수로 SHA-1과 비슷한 구조를 가지고 있음.
N-NASH : 1989년 일본의 전신전화주식회사(NTT)에서 발표한 암호화 해시 함수. 블록 크기, 키 길이가 모두 128비트임.
SNEFRU : 1990년 R.C.Merkle가 발표한 해시 함수. 32비트 프로세서 에서 구현을 용이하게 할 목적으로 개발됨.
서비스 거부 공격 유형 ★ ★ ★ ★ ★
Ping of Death : Ping 명령을 전송 할 때 패킷의 크기를 인터넷 프로토콜 허용 범위(65,536 바이트) 이상 으로 전송해 공격 대상의 네트워크를 마비 시킴
Smurfing(스머핑) : IP 나 ICMP의 특성을 악용 해 엄청난 양의 데이터를 한 사이트에 집중적으로 보냄으로 네트워크 상태를 불능으로 만듬. ICMP Echo 패킷 을 직접 브로드 캐스팅, 바운스 사이트 라는 제 3의 사이트를 이용함.
SYN Flooding : TCP는 신뢰성 있는 전송을 위해 3-way-handshake를 거친 후에 데이터를 전송하는데, SYN Flooding은 공격자가 가상의 클라이언트로 위장해 3-way-handshake 과정을 의도적으로 중단시킴 으로 공격 대상지인 서버가 대기 상태에 놓여 정상적인 서비스를 수행하지 못하게 만듬
TearDrop : 데이터의 송수신 과정에서 패킷의 크기가 커 여러 개로 분할되어 전송될 때, 분할 순서를 알 수 있도록 Fragment Offset 값을 함께 전송하는데, TearDrop은 이 Offset값을 변경 시켜 수신 측에서 패킷을 재조합할 때 오류로 인한 과부하를 초래 함
Land Attack : 패킷을 전송할 때 송신 IP 주소 와 수신 IP 주소를 모두 공격 대상의 IP 주소 로 하여 공격대상에게 전송하는 것. 공격 대상은 송신 측이 자신이기 때문에 자신에게 무한히 응답 하게 된다.
DDos : 여러 곳에 분산된 공격 지점에서 한 곳의 서버에 대해 분산 서비스 공격을 수행하는 것으로, 네트워크에서 취약점이 있는 호스트들을 탐색한 후 이들 호스트에 분산 서비스 공격용 툴을 설치해 에이전트로 만든 후 DDoS 공격에 이용함
– Trin00 : 가장 초기 형태의 데몬으로 UDP Flooding 공격을 수행
– TFN : UDP Flooding + TCP SYN Flood 공격 + ICMP 응답 요청 + 스머핑 공격 수행
(니누푸) (훔쳐보기+획득+권한및탈취)
* 스니핑 : 네트워크 상에서 자신이 아닌 다른 상대방들의 패킷 교환을 훔쳐보는 행위(중요정보 훔쳐보기)
* 스누핑 : 네트워크 상에서 떠도는 중요 정보를 몰래 획득하는 행위.(중요정보 염탐 + 획득)
* 스푸핑 : 외부의 악의적인 네트워크 침입자가 웹사이트를 구성해 사용자들의 방문을 유도, 인터넷 프로토콜인 TCP/IP의 구조적 결함을 이용해 사용자의 시스템 권한을 획득한 뒤, 정보를 빼앗아 가는 해킹 수법(시스템 권한을 획득해 정보를 탈취)
네트워크 침해 공격 관련 용어 ★ ★ ★
스미싱 : 각종 행사 안내 등 문자 메시지 를 이용해 사용자의 개인 신용 정보를 빼내는 수법
스피어 피싱 : 특정 대상을 선정한 후 그 대상에게 일반적인 이메일로 위장한 메일 을 지속적으로 발송해 발송 메일의 본문 링크나 첨부된 파일을 클릭하도록 유도해 개인정보 탈취
APT(지능형 지속 위협) : 다양한 IT 기술과 방식들을 이용해 조직적으로 특정 기업 이나 조직 네트워크에 침투 해 활동 거점을 마련한 뒤 때를 기다리면서 보안을 무력화하고 정보를 수집한 다음 외부로 빼돌리는 공격
무작위 대입 공격(Brute Force Attack) : 암호화된 문서의 암호키를 찾아내기 위해 적용가능한 모든 값을 대입 해 공격하는 방식
SQL 삽입 공격 : 전문 스캐너 프로그램 혹 봇넷 등을 이용해 웹사이트를 무차별적으로 공격하는 과정에서 취약한 사이트가 발견되면 데이터베이스 등의 데이터를 조작 하는 공격 방식
크로스사이트 스크립팅(XSS) : 웹페이지에 악의적인 스크립트를 삽입 해 방문자들의 정보를 탈취하거나 비정상적인 기능 수행을 유발하는 공격
메모리 버퍼 오버플로우 : 연속된 메모리 공간을 사용하는 프로그램에서 할당된 메모리의 범위를 넘어선 위치 에서 자료를 읽거나 쓰려고 할 때 발생하는 보안 약점.
정보 보안 침해 공격 관련 요소 ★ ★ ★
좀비 PC : 악성 코드에 감염되 다른 프로그램이나 컴퓨터를 조종하도록 만들어진 컴퓨터. C&C(Command & Control) 서버의 제어를 받아 DDoS공격에 이용됨
C&C 서버 : 해커가 원격지에서 감염된 좀비 PC에 명령을 내리고 악성코드를 제어하기 위한 용도로 사용하는 서버
봇넷 : 악성 프로그램에 감염되어 악의적인 의도로 사용될 수 있는 다수의 컴퓨터들이 네트워크로 연결된 형태
웜 : 네트워크를 연속적으로 자신을 복제해 시스템의 부하를 높임으로 결국 시스템을 다운 시키는 바이러스의 일종.
제로 데이 공격 : 보안 취약점이 발견되었을 때 발견된 취약점의 존재 자체가 널리 공표되기도 전에 해당 취약점을 통해 이루어지는 보안 공격 으로 공격의 신속성을 의미
키로거 공격 : 컴퓨터 사용자의 키보드 움직임을 탐지해 ID, 패스워드 같은 개인정보를 빼가는 해킹 공격
백도어 : 시스템 설계자가 서비스 기술자나 유지보수 프로그램 작성자의 액세스 편의를 위해 시스템 보안을 제거해 만들어 놓은 비밀 통로
– 백도어 탐지 방법 : 무결성 검사, 로그 분석, SetUID 파일 검사[무로S]
트로이 목마 : 정상적인 기능을 하는 프로그램으로 위장해 프로그램 내에 숨어 있다가 해당프로그램이 동작할때 활성화 되어 부작용을 일으키는 것. 자기 복제 능력은 없음.
그외 보안 관련 ★ ★
침입 탐지 시스템(IDS) : 컴퓨터 시스템의 비정상적인 사용, 오용, 남용 등을 실시간으로 탐지 하는 시스템. 오용 탐지, 이상 탐지가 있음.
침입 방지 시스템(IPS) : 방화벽과 침입 탐지 시스템을 결합한 것으로, 비정상적인 트래픽을 능동적으로 차단 하고 격리하는 등의 방어 조치를 취하는 보안 솔루션.
데이터 유출 방지(DLP) : 내부 정보의 외부 유출을 방지하는 보안 솔루션 으로 사내 직원이 이용하는 PC와 네트워크 상의 모든 정보를 검색하고 사용자의 행위를 탐지 , 통제해 사전 유출 방지함.
VPN : 공중 네트워크 와 암호화 기술을 이용 해 사용자가 마치 자신의 전용 회선을 사용 하는 것처럼 해주는 보안 솔루션.
NAC(Network Access Control) : 네트워크에 접속하는 내부 PC의 MAC주소 를 IP 관리 시스템에 등록한 후 일관된 보안 관리 기능을 제공 하는 보안 솔루션.
ESM(Enterprise Security Management) : 다양한 장비에서 발생하는 로그 및 보안 이벤트를 통합해 관리 하는 보안 솔루션.
일방향 암호화 : 암호화 수행을 하지만 절대로 복호화가 불가능한 알고리즘
솔트(Salt) : 일방향 해시함수 에서 다이제스트 를 생성할 경우 추가되는 임의의 문자열
세션 하이재킹 : 세션을 가로채서 정상적인 인증 절차를 무시하고 불법적으로 시스템을 접속 하는 것.
tripwire : 크래커 가 침입해 백도어 를 만들어 놓거나 설정 파일을 변경했을때 분석하는 도구
Secure DB : 커널 암호화 방식으로 데이터베이스 파일을 직접 암호화 하고, 접근 제어와 감사 기록이 추가된 데이터베이스 보안 강화 기술
코드 난독화 : 역공학을 통한 공격을 막기 위해 프로그램 소스를 알아보기 힘든 코드로 바꾸는 기술
CWE(Common Weakness Enumeration) : 소프트웨어 취약점 및 취약점에 대한 범주 시스템 으로, 소프트웨어의 결함을 이해하고 이러한 결함을 식별·수정 및 방지하는데 사용할 수 있는 자동화된 도구를 작성하는 시스템
각종 재해 관련 ★ ★ ★
BCP(Business Continuity Planning) : BCP는 각종 재해, 장애, 재난으로부터 위기관리를 기반 으로 재해복구, 업무복구 및 재개, 비상계획 등을 통해 비즈니스 연속성을 보장 하는 체계이다.
RTO(Recovery Time Objective) : RTO는 업무중단 시점부터 업무가 복구되어 다시 가동 될 때까지의 시간 이다. 재해 시 복구 목표 시간의 선정
RPO(Recovery Point Objective) : RPO는 업무중단 시점부터 데이터가 복구되어 다시 정상가동 될 때 데이터의 손실 허용 시점 이다. 재해 시 복구 목표 지점의 선정
BIA(Business Impact Analysis) : BIA는 장애나 재해로 인해 운영상의 주요 손실을 입을 것을 가정하여 시간흐름에 따른 영향도 및 손실평가를 조사 하는 BCP를 구축하기 위한 비즈니스 영향 분석 이다.
DRS(Disaster Recovery System) : DRS는 재해복구계획의 원활한 수행을 지원하기 위하여 평상시에 확보하여 두는 인적,물적 자원 및 이들에 대한 지속적인 관리체계가 통합된 재해 복구 센터 이다.
포인터 파이썬 정리 ★ ★ ★ ★ ★
포인터 정리
int a = 50; // 임의의 메모리를 a라는 이름의 변수로 지정, 50을 저장 int *b = &a; // *b는 50이 저장된 a의 주소를 기억하는 포인터다. // &연산자는 해당 변수의 주소를 가져오는 연산자다. // *b = &a는 즉 *b 포인터를 초기화 하는 과정으로, *b 포인터에 a의 주소를 저장한다. int *b = *b + 20; // b가 가리키는 곳의 값(*b, 즉 a)에 20을 더한다. b에 저장된 주소가 a의 주소이고, // *연산자는 해당 포인터가 가리키는 값을 가져오는 것이기 때문에 실제로 a에 저장된 50을 뜻한다. // 50 + 20의 결과를 *b에 저장, 즉 a변수에 저장해 a변수의 값은 50에서 70으로 변경된다. printf(“%d, %d
“, a, *b); // a값과 *b값을 출력. 같은 곳을 가리키고 있기 때문에 70, 70으로 출력된다. char *s; // 문자형 변수가 저장된 곳의 주소를 기억할 포인터를 선언 s = “gilbut”; // s는 주소를 기억하는 포인트 변수이기 때문에 gilbut라는 문자열이 메모리 어딘가에 저장이 되고, // 그 메모리의 주소를 s가 기억한다. for (int i = 0; i<6; i+= 2){ printf("%c, ", s[i]); // s[0]의 문자를 출력 => g printf(“%c, “, *(s + i)); // s의 주소가 임의로 1000이라고 가정하면, s + i(0,1,2,…)로 // 즉 s의 주소가 1000, 1001, 1002씩 증가하게 된다. // char의 메모리는 1 byte이기 때문에 1000~1006까지 메모리에 문자열이 저장이 되어 // 1000 g / 1001 i / 1002 l / 1003 b / 1004 u / 1005 t // 해당 메모리값의 * 연산자가 들어가기 때문에 그 메모리 주소의 값을 가져오게 된다. printf(“%s
“, s + i); // 출력 연산자가 %s이기 때문에 s+i인 위치(1000, 1001, 1002, …)에서 // 문자열을 끝까지 출력한다. i가 2씩 증가하기 때문에 gilbut, lbut, ut // 이런식으로 출력 된다. }
파이썬 정리
x = input(‘입력 : ‘) // x에 xyz321를 입력했다고 가정 a = [ ‘abc123’, ‘def456’, ‘ghi789’] # a는 리스트로 저장되며 순차적으로 a[0], a[1], a[2]에 저장된다. a.append(x) # append 함수는 리스트 마지막에 x의 값을 추가하는 의미이며, # a[3] 위치에 xyz321이 저장된다. a.remove(‘def456’) # remove 함수는 리스트에 저장되어 있는 def456을 제거하는 의미이며, # 리스트에는 [‘abc123’, ‘ghi789’, ‘xyz321’]이 남게 된다. print(a[1][-3:], a[2][:-3], sep = ‘,’) # a[1][-3:]과 a[2][:-3]의 요소를 , 문자로 슬라이스해서 출력하라는 의미다. # a[1]에 저장된 문자열인 ghi789의 -3위치부터 마지막 요소까지 출력한다. # g h i 7 8 9 # -6 -5 -4 -3 -2 -1 # 즉, 789가 출력. # a[2]에 저장된 문자열인 xyz321의 맨 처음요소부터 -4위치까지 출력한다. # x y z 3 2 1 # -6 -5 -4 -3 -2 -1 # 즉, xyz가 출력. # 결과적으로 789,xyz가 출력된다. for i in range(3, 6) print(i, end = ‘ ‘) # 출력이 끝나고 끝 문자에 공백 문자를 추가한다는 의미이다. # 3에서부터 6-1(5)까지 이므로 3 4 5가 출력된다.
프로토콜 네트워크 요약
인터넷 ★ ★
서브네팅 : 네트워크 주소를 다시 여러 개의 작은 네트워크로 나눠 사용 하는 것. 4바이트의 구분하기 위해 나는 비트를 서브넷 마스크 라고 함.
IPv6 : 16비트씩 8부분, 총 128비트 로 구성됨. 각 부분을 16진수로 표현하고 콜론으로 구분. 인증성, 기밀성, 데이터 무결성 으로 보안문제 해결. 유 니캐스트, 멀 티캐스트, 애 니캐스트.
도메인 네임(DNS) : 숫자로 된 IP주소 를 사람이 이해하기 쉬운 문자 형태(이름) 로 표현한 것.
OSI 참조 모델[물데네전세표응] ★ ★
물리 계층 : 전송에 필요한 두 장치간의 실제 접속 과 절단 등 기계적 , 전기적, 기능적, 절차적 특성에 대한 규칙을 정의함. RS-232C, Bit
데이터 링크 계층 : 두 개의 인접한 개방 시스템 들 간에 신뢰성 있고 효율적인 정보 전송을 할 수 있도록 함. 흐름제어, 프레임 동기화, 오류 제어, 순서 제어. 이더넷, Frame
네트워크 계층 : 경로 설정(Routing) , 트래픽 제어, 패킷 정보 전송. IP/ICMP, 패킷
전송 계층 : 종단 시스템(End-to-End) 간의 전송 연결 설정, 데이터 전송, 연결 해제, 주소 설정, 다중화(데이터의 분활과 재조립), 오류 제어, 흐름 제어. TCP/UDP, 세그먼트
세션 계층 : 송수신 측 간의 관련성을 유지, 대화 제어 , 대화(회화) 구성 및 동기 제어, 데이터 교환 관리 기능. SSH/TLS
표현 계층 : 코드 변환 , 데이터 암호화 , 데이터 압축 , 구문 검색, 정보 형식 변환, 문맥 관리 기능. JPEG/MPEG
응용 계층 : 사용자가 OSI 환경에 접근할 수 있도록 응용 프로세스 간의 정보 교환 , 전자 사서함 , 파일 전송 , 가상 터미널 등의 서비스를 제공. HTTP/FTP
프로토콜 ★ ★ ★ ★ ★
서로 다른 기기 간의 데이터 교환을 원활하게 수행할 수 있도록 표준화 시켜 놓은 통신 규약.
프로토콜의 기본 요소
– 구문 : 전송하고자 하는 데이터의 형식, 부호화, 신호레벨 등을 규정 함
– 의미 : 두 기기 간의 효율적이고 정확한 정보 전송을 위한 협조 사항 과 유로 관리를 위한 제어 정보를 규정 함
– 시간 : 두 기기 간의 통신 속도, 메시지의 순서 제어 등을 규정함
응용 계층의 주요 프로토콜 ★ ★
SMTP : 전자 우편 을 교환하는 서비스
SMNP : TCP/IP의 네트워크 관리 프로토콜로, 라우터나 허브 등 네트워크 기기의 네트워크 정보를 네트워크 관리 시스템에 보내는데 사용 되는 표준 통신 규약
DNS : 도메인 네임 을 IP 주소로 매핑 하는 시스템
전송 계층의 주요 프로토콜 ★ ★ ★ ★
TCP : 양방향 연결형 서비스 제공. 스트림 위주의 전달. 신뢰성 있는 경로 확립. 순서 제어, 오류 제어, 흐름 제어 .
UDP : 연결을 설정하지 않는 비연결형 서비스 제공. 단순한 헤더 구조.
RTCP : RTP 패킷의 전송 품질을 제어 하기 위한 프로토콜. 세션에 참여한 각 참여자들에게 주기적으로 제어 정보 전송 . 하위 프로토콜은 데이터 패킷과 제어 패킷의 다중화를 제공. 최소한의 제어와 인증 기능 제공.
* LDAP(Lightweight Directory Access Protocol) : TCP/IP 위에서 조직화 되고 비슷한 특성을 가진 객체들의 모인인 디렉터리 서비스 를 조회하고 수정하는 응용 프로토콜
* DHCP(Dynamic Host Configuration Protocol) : 네트워크상에서 동적 으로 IP 주소 및 기타 구성정보 등을 부여/관리하는 프로토콜로서, PC의 수가 많거나 PC 자체 변동사항이 많은 경우 IP 설정이 자동으로 되기 때문에 효율적으로 사용 가능하고, IP를 자동으로 할당 해주기 때문에 IP 충돌을 막는데 사용 하는 프로토콜
인터넷 계층의 주요 프로토콜 ★ ★ ★ ★ ★
IP(Internet Protocol) : 전송할 데이터에 주소를 지정하고 경로를 설정. 비연결형인 데이터 그램 방식을 사용, 신뢰성 보장되지 않음
ICMP : IP와 조합해 통신 중에 발생하는 오류의 처리 와 전송 경로 변경 등을 위한 제어 메시지를 관리 하는 역할
IGMP : 멀티 캐스트를 지원하는 호스트나 라우터 사이에서 멀티캐스트 그룹 유지 를 위해 사용하며, 화상회의, IPTV에서 활용. 그룹가입, 멤버쉽관리 멤버쉽 응답 등의 기능
ARP : 호스트의 IP 주소 를 물리적 주소(MAC Address) 로 변환
RARP : ARP와 반대 로 물리적 주소를 IP 주소로 변환
네트워크 액세스 계층의 주요 프로토콜 ★ ★ ★
Ethernet(IEEE 802.3) : CSMA/CD 방식의 LAN
IEEE 802 : LAN을 위한 표준 프로토콜
HDLC : 비트 위주의 데이터 링크 제어 프로토콜
X.25 : 패킷 교환망 을 통한 DTE와 DCE(모뎀) 간의 인터페이스를 제공 하는 프로토콜이며 전기 통신 국제기구 ITU-T에서 관리 감독하는 프로토콜. 패킷이라고 불리는 데이터 블록을 사용
RS-232C : 공중 전화 교환망(PSTN) 을 통한 DTE와 DCE 간의 인터페이스 를 제공하는 프로토콜이며 미국의 EIA(Electronic Industries Association)에 의해 인터페이스가 규격화 됨
네트워크 구축 방법 ★ ★
스타형 : 중앙에 중앙 컴퓨터가 있고, 이를 중심으로 단말장치들이 연결되는 중앙 집중식의 네트워크 구성 형태.
링형 : 컴퓨터와 단말장치들을 서로 이웃하는 것끼리 연결 시킨 포인트 투 포인트 방식의 구성 형태.
버스형 : 한 개의 통신 회선에 여러 대의 단말장치가 연결되어 있는 형태
계층형 : 중앙 컴퓨터와 일정 지역의 단말장치까지는 하나의 통신회선으로 연결시키고, 이웃하는 단말 장치는 일정지역내에 설치된 중간 단말 장치로부터 다시 연결시키는 형태. 분산 처리 시스템을 구성 하는 방식.
망형 : 모든 지점의 컴퓨터와 단말 장치를 서로 연결한 형태. ” 회선수 = n(n-1) / 2 ” “포트수 = n-1”
NAT(네트워크 주소 변환) : 한 개의 정식 IP 주소 에 다량의 가상 사설 IP 주소를 할당 및 연결하는 기능. IP 마스커레이드 이용.
라우팅 프로토콜 ★ ★ ★ ★ ★
경로제어 : 송수신 측 간에 전송 경로중에서 최적패킷 교환 경로를 결정 하는 기능. 경로 제어표를 참조. 라우터에 의해 수행
내부 라우팅 프로토콜(IGP) : 하나의 자율시스템(AS)내에 라우팅에 사용되는 프로토콜
– RIP : 현재 가장 널리 사용되는 라우팅 프로토콜로, 소규모 동종의 네트워크 내에서 효율적인 방법이며, 최대 홉수를 15로 제한 함. 거리벡터 방식 라우팅 프로토콜. 최단 경로 탐색에 Bellman-Ford 알고리즘 사용. 라우팅 정보를 30초 마다 네트워크내 모든 라우터에게 알림
– OSPF : RIP의 단점을 해결해 새로운 기능을 지원하는 인터넷 프로토콜로 대규모 네트워크 내에서 사용. 라우팅 정보에 노드 간의 거리 정보, 링크 상태 정보를 실시간으로 반영 . 자신을 기준으로 한 다익스트라 알고리즘 기반으로 최단 경로를 찾는 라우팅 (Link-State) 프로토콜. 하나의 자율 시스템에서 동작하면서 내부 라우팅 프로토콜의 그룹에 도달.
외부 라우팅 프로토콜
– EGP : 자율 시스템(AS) 간의 라우팅 프로토콜로, 게이트 웨이 간의 라우팅에 사용 되는 프로토콜
– BGP : 자율시스템 간의 라우팅 프로토콜로 EGP의 단점을 보완하기 위해 만들어짐. BGP 라우터들이 연결될 때에 전체 경로 제어표(라우팅 테이블) 를 교환.
네트워크 관련 장비 ★ ★
허브 : 한 사무실이나 가까운 거리의 컴퓨터들을 연결하는 장치로, 각 회선을 통합적으로 관리하며, 신호 증폭 기능을 하는 리피터 역할도 포함함
리피터 : 물리계층의 장비로, 전송되는 신호가 왜곡 되거나 약해질 경우 원래의 신호 형태로 재생함
브리지 : 데이터 링크 계층의 장비로 LAN과 LAN을 연결하거나 LAN 안에서 컴퓨터 그룹을 연결함
라우터 : 네트워크 계층의 장비로 LAN과 LAN의 연결 및 경로 선택, 서로 다른 LAN이나 LAN과 WAN을 연결함
게이트웨이 : 전 계층의 프로토콜 구조가 전혀 다른 네트워크의 연결을 수행함
스위치 : 브리지와 같이 LAN과 LAN을 연결하여 훨씬 더 큰 LAN을 만드는 장치
네트워크 제어 ★ ★ ★
트래픽 제어 : 네트워크의 보호, 성능 유지, 네트워크 자원의 효율적인 이용을 위해 전송되는 패킷의 흐름 또는 그 양을 조절하는 기능.
흐름 제어 : 네트워크 내의 원활한 흐름을 위해 송수신 측 사이에 전송되는 패킷의 양이나 속도를 규제하는 기능.
– 정지 대기 : 수신 측의 확인 신호를 받은 후에 다음 패킷을 전송하는 방식
– 슬라이딩 윈도우 : 수신 통지를 이용해 송신 데이터의 양을 조절 하는 방식. 패킷의 최대치가 윈도우 사이즈를 의미.
폭주 제어 : 네트워크 내의 패킷 수를 조절 해 네트워크의 오버 플로를 방지 하는 기능을 함.
기타 네트워크 ★ ★ ★
CDN(Contents Delivery Network) : 게임 클라이언트 나 콘텐츠 를 효율적으로 전달하기 위해 여러 노드를 가진 네트워크에 데이터를 저장해 사용자에게 제공하는 시스템
SDN(Software Defined Network) : 개방형 API(오픈 플로우)기반 으로 네트워크 장비의 트래픽 경로를 지정하는 컨트롤 플레인 과 트래픽 전송을 수행하는 데이터 플레인을 분리 해 네트워크 트래픽을 중앙 집중적으로 관리하는 기술
오픈 플로우 : 가상화 기반 네트워크 기술로 네트워크 장치의 컨트롤 플레인 과 데이터 플레인 간의 연계 및 제어 를 담당하는 개방형 표준 인터페이스.
오버레이 네트워크 : 가상화 기반 네트워크 기술로 기존의 물리적, 논리적으로 존재하는 토폴로지 위에 또 다시 다른 필요에 의해 논리적인 토폴로지를 재구성해 성능을 개선하고, 다양한 기능을 제공하는 네트워크
VPN : 인터넷과 같은 공중망 에서 터널링, 암호화 기법 등을 사용해 전용 회선으로 연결된 사설망과 같은 서비스를 제공하는 가상의 네트워크다.
백본망 : 다양한 네트워크를 상호 연결하는 컴퓨터 네트워크의 일부로서, 각기 다른 LAN이나 부분망 간에 정보를 교환하기 위한 경로를 제공 하는 망
QoS(Quality Of Service) : 다른 프로그램, 사용자, 데이터 흐름 등에 우선순위 를 정하며, 데이터 전송에 특정 수준의 성능(속도)를 보장 하기 위한 능력
ATM(비동기 전송모드) : 광대역 서비스의 다양한 특수성을 수용하기 위한 광대역 종합정보통신망(B-ISDN)의 실현을 목적으로 제안되었으며, 회선 교환 방식과 패킷교환방식의 장점을 통합시킨 연결 지향적 송성을 지닌 패킷교환(스위칭) 프로토콜
SECURE OS ★ ★
SECURE OS : OS에 내재된 보안 취약점을 해소하기 위해 보안 기능을 갖춘 커널을 이식 해 외부의 침입으로 부터 시스템 자원을 보호하는 운영체제 . TCB 기반 참조 모니터의 개념을 구현 하고 집행.
참조 모니터 : 보호 대상 객체에 대한 접근 통제를 수행하는 추상 머신 이며, 보안 커널 데이터베이스를 참조 해 객체애 다한 접근 허가 여부를 결정
DB 관련 신기술 ★ ★ ★
하둡 : 오픈 소스를 기반으로 한 분산 컴퓨팅 플랫폼. 가상화된 대형 스토리지 형성, 거대한 데이터 세트를 병렬로 처리할 수 있도록 개발된 자바 소프트웨어 프레임워크
맵 리듀스 : 대용량 데이터를 분산 처리 하기 위한 목적으로 개발된 프로그래밍 모델
타조 : 오픈 소스 기반 분산 컴퓨팅 플랫폼인 아파치 하둡 기반의 분산 데이터 웨어하우스 프로젝트
운영체제
배치 프로그램
배치 프로그램 : 사용자와 상호작용 없이 일련의 작업을 작업 단위로 묶어 정기적으로 반복 수행하는 일괄 처리 방법
– 스프링 배치 : Spring Source 사와 Accenture 사가 2007년 공동 개발한 오픈 소스 프레임 워크 . 로그 관리, 추적, 트랜잭션 관리, 작업처리 통계, 재시작 기능 제공
– 쿼츠 스케줄러 : 스프링 프레임워크로 개발되는 오픈 소스 라이브러리 로 수행할 작업과 수행시간을 관리하는 요소들을 분리해 일괄처리 작업에 유연성을 제공(크론식 : (초) 분 시 일 월 요일 (년) 명령어 )
Windows 주요 특징
Pnp(자동감지기능) : 컴퓨터 시스템에 하드웨어 를 설치했을 때, 필요한 시스템 환경을 운영체제가 자동으로 구성 해주는 기능
OLE : 다른 프로그램에서 작성된 문자나 그림 등의 개체를 현재 작성 중인 문서에 자유롭게 연결하거나 삽입해 편집할 수 있게 하는 기능
Unix 시스템 특징
커널 : 프로그램과 하드웨어 간의 인터페이스 담당. 프로세스 관리, 기억장치 관리, 파일 관리, 입출력 관리 등
쉘 : 사용자 명령어 를 인식해 명령을 수행하는 명령어 해석기 . 시스템과 사용자 간의 인터페이스를 담당
기억장치 관리 전략
반입 전략 : 프로그램이나 데이터를 언제 주기억장치로 적재할 것인지 결정
– 요구 반입 : 실행 중인 프로그램이 특정 프로그램이나 데이터 등의 참조를 요구할 때 적재
– 예상 반입 : 실행 중인 프로그램에 의해 참조될 프로그램이나 데이터를 미리 예상해 적재
가상 기억 장치
보조기억장치의 일부를 주기억장치처럼 사용하는 것
– 페이징(Paging) 기법 : 가상 기억장치에 보관되어 있는 프로그램과 주기억장치의 영역을 동일한 크기 로 나눈 후, 나눠진 프로그램(페이지)을 동일하게 나눠진 주기억장치의 영역(페이지 프레임)에 적재시켜 실행. 외부 단편화 발생x, 내부 단편화 발생o . 주소 변환을 위해 페이지 맵 테이블이 필요함. 페이지 맵 테이블 사용 으로 비용이 증가, 처리속도가 감소.
– 세그먼테이션(Segmentation) 기법 : 가상기억장치에 보관되어 있는 프로그램을 다양한 크기 의 논리적인 단위로 나눈 후 주기억장치에 적재시켜 실행시키는 기법. 배열이나 함수 등과 같은 논리적 크기로 나눈 단위를 세그먼트라고 부르며, 각 세그먼트는 고유한 이름과 크기를 가짐. 기억장치의 사용 관점을 보존하는 기억장치 관리 기법이다. 주소 변환을 위해 세그먼트 맵 테이블 이 필요함. 세그먼트가 주 기억장치에 적재될 때 다른 세그먼트에게 할당된 영역을 침범할 수 없도록 기억장치 보호키가 필요함. 내부 단편화x, 외부 단편화o
페이지 교체 알고리즘
페이지 부재(Page Fault) : CPU가 액세스한 가상 페이지가 주기억장치 에 없는 경우. 페이지 부재가 발생하면 해당 페이지를 보조기억장치(디스크)에서 주기억장치로 가져와야함.
* 페이지 부재 빈도(PFF) : 페이지 부재 횟수를 의미.
* 프리페이징(Prepaging) : 처음의 과도한 페이지 부재를 방지하기 위해 필요할 것 같은 모든 페이지를 한꺼번에 페이지 프레임에 적재 하는 기법
OPT(OPTimal replacement, 최적 교체) : 앞으로 가장 오랫동안 사용하지 않을 페이지를 교체
FIFO(First In First Out) : 가장 먼저 들어와서 오래있었던 페이지를 교체
LRU(Least Recently Used) : 최근에 가장 오랫동안 사용하지 않은 페이지를 교체
LFU(Least Frequently Used) : 사용 빈도 가 가장 적은 페이지를 교체
NUR(Not Used Recently) : 최근에 사용하지 않은 페이지를 교체. 사용 여부를 확인 하기 위해 참조 비트와 변형 비트 2개의 비트 를 사용함.
가상기억장치 관리사항
Locality(지역성) : 데닝(Denning) 교수에 의해 개념 증명. 프로세스가 실행되는 동안 주기억장치를 참조할 때 일부 페이지만 집중적으로 참조 하는 성질. 스래싱을 방지하기 위한 워킹셋의 기반 이 됨.
– 시간 구역성 : 프로세스가 실행되면서 하나의 페이지를 일정 시간 동안 집중적으로 액세스 하는 현상. 한번 참조한 페이지는 가까운 시간 내에 계속 참조할 가능성이 높음
– 시간 구역성이 이뤄지는 기억 장소 : Loop(반복,순환), 스택(Stack), 부 프로그램(Sub Routine), Counting(1씩 증감), 집계에 사용되는 변수
– 공간 구역성 : 프로세스 실행시 일정 위치의 페이지를 집중적으로 액세스 하는 현상. 어느 페이지를 참조하면 그 근처의 페이지를 계속 참조할 가능성이 높음.
– 공간 구역성이 이뤄지는 기억 장소 : 배열 순회(Array Traversal), 순차적 코드의 실행, 프로그래머들이 관련된 변수(데이터를 저장할 기억 장소)들을 서로 근처에 할당되는 기억장소, 같은 영역에 있는 변수
워킹 셋(Working Set) : 프로세스가 일정시간 동안 자주 참조하는 페이지들의 집합 . 자주 참조되는 워킹 셋을 주기억장치에 상주시킴으로서 페이지 부재 및 페이지 교체 현상을 줄이고 프로세스의 기억 장치 사용이 안정됨.
스래싱(Thrashing) : 프로세스의 처리시간 보다 페이지 교체에 소요되는 시간이 더 많아지는 현상. 다중 프로그래밍 정도가 상승하면 CPU의 이용률은 어느 특정 시점까지 높아지며, 정도가 더욱 커지면 스래싱이 발생해 CPU의 이용률이 급격히 감소 하게 된다.
프로세스 상태 전이
PCB(프로세스 제어 블록) : 운영체제가 프로세스에 대한 중요한 정보를 저장해 놓는 곳이다.
제출(Submit, 생성) : 작업을 처리하기 위해 사용자가 작업을 시스템에 제출한 상태
접수(Hold, 생성) : 제출된 작업이 스풀 공간인 디스크의 할당 위치에 저장된 상태. 생성 과정 안에 (제출->접수)이 포함.
준비(Ready) : 프로세스가 프로세서를 할당받기 위해 기다리고 있는 상태. 프로세스는 준비상태 큐에서 실행을 준비.
접수(Hold) : 상태에서 준비상태로의 전이는 Job 스케줄러에 의해 수행된다.
실행(Run) : 준비상태 큐에 있는 프로세스가 프로세서를 할당받아 실행되는 상태. 프로세스 수행이 완료되기 전에 프로세스에게 주어진 프로세서 할당 시간(Timer Runout)이 종료 되면 프로세스는 준비 상태로 전이됨. 실행중인 프로세스에 입출력 처리가 필요하면 실행중인 프로세스는 대기 상태로 전이됨.
대기(Wait), 보류, 블록(BlocK) : 프로세스에 입출력처리가 필요하면 현재 실행 중인 프로세스가 중단되고, 입출력처리가 완료될 때까지 대기하고 있는 상태
종료 : 프로세스의 실행이 끝나고 프로세스 할당이 해제된 상태
*요약 : 사용자가 작업을 요청하면 프로세스가 스풀 공간에서 생성되고, 프로세서를 할당받기 위해 준비하며 프로세서가 할당되면 실행됩니다. 이때 할당시간이 종료되면 다시 준비로 가거나 입출력 처리가 필요하면 대기로 가서 입출력이 완료되면 Wake Up에 의해 다시 준비로 갑니다.
Hold -> Job 스케쥴러 -> 준비
준비 -> Dispatch -> 실행
실행 -> Timer Runout -> 준비
대기 -> Wake up -> 준비
프로세스 상태 전이 관련 용어
Dispatch : 준비 상태 에서 대기하고 있는 프로세스 중 하나가 프로세서를 할당받아 실행 상태 로 전이되는 과정
Wake Up : 입출력작업이 완료되어 프로세스가 대기 상태 에서 준비 상태 로 전이되는 과정
Spooling : 입출력 장치의 공유 및 상대적으로 느린 입출력장치의 처리속도를 보완 하고 다중프로그래밍 시스템의 성능을 향상 시키기 위해 입출력할 데이터를 직접 입출력장치에 보내지 않고 나중에 한꺼번에 입출력하기 위해 디스크에 저장 하는 과정.
타이머 런 아웃 : CPU를 할당받아 실행되고 있는 프로세스는 지정된 할당 시간이 초과되면 스케줄러에 의해 CPU 반납 후 다시 준비 상태가 되는 프로세스 상태 전이
MMU(Memory Management Unit) : CPU가 메모리에 접근하는 것을 관리하는 하드웨어 부품 으로 가상 메모리를 실제 메모리 주소로 변환 하는 장치
스케줄링 과정
장기 스케쥴링 : 어떤 프로세스가 시스템의 자원을 차지할 수 있도록 할 것인가를 결정하여 준비상태 큐로 보내는 작업. 작업 스케줄링, 상위 스케줄링이라고 함. 작업 스케줄러에 의해 수행됨
중기 스케쥴링 : 어떤 프로세스들이 CPU를 할당받을 것인지 결정하는 작업. CPU를 할당받으려는 프로세스가 많을 경우 프로세스 일시 보류 후 활성화함으로 부하를 조절함.
단기 스케줄링 : 프로세스가 실행되기 위해 CPU를 할당받는 시기와 특정 프로세스를 지정하는 작업. 프로세서 스케줄링, 하위 스케줄링 이라고 함. 프로세스 스케줄러에 의해 문맥 교환이 수행됨
스케줄링 목적
공정성 : 모든 프로세스에 공정하게 할당
처리율 증가(Throughput) : 단위 시간당 프로세스 처리 비율 증가
CPU 이용률 증가 : CPU의 낭비시간 감소, CPU의 사용 시간 비율 증가
우선순위 제도 : 우선순위가 높은 프로세스 우선 수행
오버헤드 최소화 : 오버헤드 최소화
응답시간 최소화 : 반응 시간 최소화
반환 시간 최소화(Turn Around Time) : 프로세스 제출 시간으로부터 실행이 완료되기 까지의 걸리는 시간 최소화
대기 시간 최소화 : 준비상태 큐에 대기하는 시간 최소화
균형 있는 자원의 사용 : 메모리, 입출력장치의 자원을 균형있게 사용
무한 연기 회피 : 자원을 사용하기 위한 무한정 연기 상태 회피
스케줄링 기법
선점 스케쥴링 : 하나의 프로세스가 CPU를 할당받아 실행하고 있을 때 우선순위가 높은 다른 프로세스가 CPU를 강제로 빼앗아 사용할 수 있는 스케줄링 기법. 우선순위가 높은 프로세스 먼저 처리. 시분할 시스템에 용이.
– SRT(Shortest Remaining Time First) : 가장 짧은 시간이 소요되는 프로세스를 먼저 수행하고, 남은 처리 시간이 더 짧다고 판단되는 프로세스가 준비 큐에 생기면 언제라도 프로세스가 점유되는 스케줄링 알고리즘
– 라운드 로빈 : CPU 할당 시간 설정 후 프로세스가 할당된 시간 내에 처리하지 못할 경우 큐리스트의 가장 맨 뒤로 이동 하고 다음 프로세스를 CPU에 할당하는 기법
비선점 스케쥴링 : 이미 할당된 CPU를 다른 프로세스가 강제로 빼앗아 사용할 수 없는 스케줄링 기법(순서대로). 프로세스가 CPU를 할당받으면 해당 프로세스가 완료될 때까지 CPU 사용. 일괄처리 방식에 적합
– FCFS(First Come First Service, 선입 선출) : 준비 상태 큐에 도착한 순서 에 따라 차례로 CPU를 할당하는 기법
– SJF(Shortest Job First, 단기 작업 우선) : 실행 시간이 가장 짧은 프로세스에게 먼저 CPU를 할당하는 기법
– HRN(Hightest Responsse-ratio Next) : SJF 기법 보완하기 위한 것으로, 대기시간과 서비스 실행 시간을 이용하는 기법. 우선순위 계산식 : (대기 시간 + 서비스 시간) / 서비스 시간
– 기한부(Deadline) : 프로세스에게 일정한 시간을 주어 그 시간 안에 프로세스를 완료하도록 하는 기법
우선순위 : 준비상태 큐에서 기다리는 각 프로세스마다 우선순위를 부여해 그중 가장 높은 프로세스에게 먼저 CPU를 할당하는 기법
에이징 기법 : 시스템에서 특정 프로세스의 우선순위가 낮아 무한정 기다리게 되는 경우 , 한 번 양보하거나 기다린 시간에 비례해 일정 시간이 지나면 우선순위를 한단계씩 높여 가까운 시간 안에 자원을 할당 받도록 하는 기법.
mutex : 임계영역 을 가진 스레드들의 실행 시간이 서로 겹치지 않게 각각 단독으로 실행 되게 하는 기술
문맥교환 : 하나의 프로세스에 다른 프로세스로 CPU가 할당되는 과정에서 발생 되는 것. 새 프로세스에 CPU를 할당하기 위해 현재 CPU가 할당된 프로세스의 상태 정보를 저장하고, 새 프로세스에 상태 정보를 설정한 후 CPU를 할당해 실행되도록 하는 작업
교착상태(Dead Lock)
상호 배제에 의해 나타나는 문제점으로, 둘 이상의 프로세스들이 자원을 점유한 상태에서 서로 다른 프로세스가 점유하고 있는 자원을 요구하며 무한정 기다리는 현상
교착상태 필요 충분 조건
– 상호 배제 : 한 번에 한 개 의 프로세스만이 공유 자원을 사용할 수 있어야 함
– 점유와 대기 : 최소한 하나의 자원을 점유 하고 있으면서 다른 프로세스에 할당되어 사용되고 있는 자원을 추가로 점유하기 위해 대기하는 프로세스가 있어야 함
– 비선점 : 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없어야 함
– 환형 대기 : 공유 자원과 공유 자원을 사용하기 위해 대기하는 프로세스들이 원형 으로 구성되어 있어 자신에게 할당된 자원을 점유하면서 앞이나 뒤 에 있는 프로세스의 자원을 요구해야 함
교착상태 해결 방법[예회발복]
예방 기법 : 상호 배제, 점유 및 대기, 비선점, 환형 대기 조건 중에서 어느 하나를 제거하여 해결
회피 기법 : 은행원 알고리즘(교착상태가 발생할 가능성을 배제하지 않고 교착상태가 발생시 적절히 피해나가는 방법)
발견 기법 : 자원 할당 그래프 활용
회복 기법 : 교착 상태의 프로세스에 할당된 자원을 선점해 회복
클라우드 컴퓨팅 유형
Iaas(인프라형) : 서버, 스토리지 같은 시스템 자원을 클라우드로 제공하는 서비스로, 컴퓨팅 자원에 운영체제나 애플리케이션 등의 소프트웨어 탑재 및 실행을 하는 서비스
Paas(플랫폼형) : 인프라 생성, 관리 등 복잡한 절차 없이 애플리케이션 개발, 실행, 관리 할 수 있도록 플랫폼을 제공하는 서비스로 OS, 애플리케이션과 애플리케이션 호스팅 환경 구성의 제어권을 가진다.
Saas(소프트웨어형) : 소프트웨어 및 관련 데이터는 중앙에 호스팅 되고 사용자는 웹 브라이주 등의 클라이언트를 통해 접속해 소프트웨어를 서비스 형태로 이용하는 서비스로 주문형 소프트웨어라고도 불린다.
제품 소프트웨어 패키징
소프트웨어 패키징 ★ ★ ★
모듈별로 생성한 실행 파일들을 묶어 배포용 설치 파일을 만드는것
소프트웨어 패키징 작업 순서[기모빌환적변배]
– 기능 식별 : 코드의 기능 확인
– 모듈화 : 기능 단위로 코드 분류
– 빌드 진행 : 모듈 별로 실행 파일
– 사용자 환경 분석 : 사용 환경(웹/모바일/PC 등), 운영체제(인도우/유닉스/안드로이드 등), CPU, RAM
– 패키징 및 적용 시험 : 빌드한 파일을 배포용 파일 형식으로 패키징하고 테스팅
– 패키지 변경 개선 : 적용 시험 후 확인된 불편 사항 반영
– 배포 : 오류 발생 시 개발자에게 전달 및 수정 요청
릴리즈 노트 ★ ★ ★
개발 과정에서 정리된 릴리즈 정보를 최종 사용자인 고객과 공유하기 위한 문서
릴리즈 노트 작성 순서[모정개영정추]
– 모듈 식별 -> 릴리즈 정보 확인 -> 릴리즈 노트 개요 작성 -> 영향도 체크 -> 정식 릴리즈 노트 작성 -> 추가 개선 항목 식별
디지털 저작권 관리(DRM) ★ ★
저작권자가 배포한 디지털 콘텐츠가 저작권자가 의도한 용도로만 사용되도록 하는 디지털 콘텐츠 관리 및 보호 기술임.
디지털 저작권 관리 용어
– 콘텐츠 제공자 : 콘텐츠를 제공하는 저작권자
– 패키저 : 콘텐츠를 메타 데이터(데이터에 대한 속성정보)와 함께 배포 가능한 형태로 묶어 암호화 하는 프로그램
– 콘텐츠 분배자 : 암호화된 콘텐츠를 유통하는 곳이나 사람
– 콘텐츠 소비자 : 콘텐츠를 구매해서 사용하는 주체
– DRM 컨트롤러 : 배포된 콘텐츠의 이용 권한을 통제하는 프로그램
– 보안 컨테이너 : 콘텐츠 원본을 안전하게 유통하기 위한 전자적 보안 장치
– 클리어링 하우스 : 저작권 관리에서 키관리 및 라이선스 발급 관리 를 수행하는 것
– DOI(Digital Object Identifier) : 디지털 저작물에 특정 번호를 부여 하는 일종의 바코드 시스템
디지털 저작권 관리의 기술 요소
– 암호화 : 콘텐츠 및 라이선스를 암호화하고 전자서명할 수 있는 기술
– 키관리 : 암호화한 키에 대한 저장 및 분배 기술
– 암호화 파일 생성 : 암호화된 콘텐츠로 생성
– 식별 기술 : 콘텐츠에 대한 식별 체계 표현 기술
– 저작권 표현 : 라이선스의 내용 표현 기술
– 정책 관리 : 라이선스 발급 및 사용에 대한 정책 표현 및 관리 기술
– 크랙 방지 : 크랙에 의한 콘텐츠 사용 방지 기술
– 인증 : 라이선스 발급 및 사용자 기준이 되는 기술
형상관리 ★ ★ ★ ★
형상관리 : 개발과정에서 소프트웨어의 변경사항을 관리하기 위해 개발된 일련의 활동.
– 형상식별 : 관리 대상에 이름, 관리번호 부여. 계층 구조로 구분.
– 버전제어 : 업그레이드나 유지보수 과정에서 다른 버전의 형상 항목을 관리, 결합 하는 작업.
– 형상통제 : 형상 항목에 대한 변경 요구를 검토 . 현재의 기준선이 잘 반영될 수 있도록 조정 .
– 형상감사 : 기준선의 무결성을 평가 하기 위해 확인
– 형상기록 : 식별, 통제, 감사의 결과를 기록 및 관리.
* CCB(Configuration Control Board; 형상통제 위원회) : 형상 항목에 대한 형상 베이스라인이 승인 된 후, 발생되는 형상 항목의 변경에 대하여 평가, 조정, 승인/보류/기각을 결정 하는 심의 조직
소프트웨어 버전 등록 관련 용어 ★ ★
저장소(Respository) : 저장소
가져오기(Import) : 아무것도 없는 저장소에서 처음으로 파일을 복사
체크아웃(Check-Out) : 파일 받기
체크인(Check-In) : 체크아웃 한 파일의 수정을 완료한 후 저장소의 파일을 새로운 버전으로 갱신한다.
커밋(Commit) : diff도구 (비교 대상이 되는 파일 들의 내용을 비교하여 서로 다른 부분을 표시해주는 도구)를 이용해 충돌을 알리고 내용을 갱신한다.
동기화(Update) : 최신 버전으로 동기화
소프트웨어 버전 관리 도구 ★ ★
버전 관리 도구 : 형상 관리 지침을 활용해 제품 소프트웨어의 신규 개발, 변경, 개선과 관련된 수정사항을 관리하는 도구 다. 또한 소프트웨어 개발과 관련해 코드와 라이브러리 관련 문서 등 시간의 변화에 따른 변경을 관리하는 전체활동을 의미한다.
– 공유 폴더 방식 : 버전 관리 자료가 지역 컴퓨터의 공유 폴더 에 저장되어 관리 되는 방식. SCCS, RCS 등
– 클라이언트/서버 방식 : 버전 관리 자료가 서버에 저장 되어 관리 되는 방식. CVS, SVN(Subversion) 등
– 분산 저장소 방식 : 버전 관리 자료가 하나의 원격 저장소 와 분산된 개발자 PC의 지역 저장소에 함께 저장 되어 관리되는 방식. Git, GNU arch, DCVS 등
빌드 자동화 도구 ★ ★ ★
빌드를 포함해 테스트 및 배포를 자동화 하는 도구. 애자일과 같은 지속적인 통합 개발 환경에 활용.
Jenkins : Java 기반 오픈 소스, 서블릿 컨테이너 , 여러 대의 컴퓨터를 이용한 분산 빌드 가능
Gradle : Groovy 기반 오픈소스, 안드로이드 앱 개발환경, Task 단위, 이전에 사용했던 태스크를 재사용하거나 다른 시스템의 태스크를 공유할 수 있는 빌드 캐시 기능 지원
반응형
2021 정보처리기사 실기 정리(完)
728×90
본 정리 글은 시나공 정보처리기사 실기책과 2020년 기출문제 등을 참고하여 작성하였습니다. -> 책 정보 확인하기
2021년 정보처리기사 실기 정리 글입니다. 계속해서 글을 업데이트할 예정이지만 시험 일정에 맞추지 못할 수 있습니다.
정리 글에는 책의 내용을 요약하여 작성하였기 때문에 내용이 부족할 수 있습니다. 부가적인 내용과 출제 예상 문제, 기출 문제를 확인하기 위해 꼭 책을 참고해 주시길 바랍니다.
작성이 안된 과목은 검은 글씨로 작성이 완료된 과목은 파란 글씨로 표시하여 제목을 클릭하시면 해당 글로 이동이 됩니다.
1장. 요구사항 확인
2장. 데이터 입출력 구현
3장. 통합 구현
4장. 서버 프로그램 구현
5장. 인터페이스 구현
6장. 화면 설계
7장. 애플리케이션 테스트 관리
8장. SQL 응용
9장. 소프트웨어 개발 보안 구축
10장. 프로그래밍 언어 활용
11장. 응용 SW 기초 기술 활용
12장. 제품 소프트웨어 패키징
반응형
So you have finished reading the 정보 처리 기사 실기 정리 topic article, if you find this article useful, please share it. Thank you very much. See more: 정보처리기사 실기 요약 pdf, 2022 정보처리기사 실기 요약 pdf, 2021 정보처리기사 실기 요약, 정보처리기사 실기 요약 2021 pdf, 정보처리기사 실기 2021 pdf, 정보처리기사 실기 벼락치기, 정보처리기사 실기 2022 pdf, 시나공 정보처리기사 실기 pdf