
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 반 정규화 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://chewathai27.com/to team, along with other related topics such as: 반 정규화 반정규화 예시, 반정규화란, 반정규화 방법, 반정규화 역정규화, 반정규화 비정규화, 컬럼 반정규화, 반정규화 유형, 정보처리기사 반정규화
3-1-14장. 반정규화(Denormalization) – B
- Article author: lipcoder.tistory.com
- Reviews from users: 23425
 Ratings
Ratings - Top rated: 3.7
- Lowest rated: 1
- Summary of article content: Articles about 3-1-14장. 반정규화(Denormalization) – B 반정규화란 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙 … …
- Most searched keywords: Whether you are looking for 3-1-14장. 반정규화(Denormalization) – B 반정규화란 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙 … 반정규화의 개념 반정규화란 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙을 위배하는 행위이다. 반정규화를 수행하면..
- Table of Contents:
기록공간
3-1-14장 반정규화(Denormalization) – B 본문

반정규화와 성능 – DATA ON-AIR
- Article author: dataonair.or.kr
- Reviews from users: 43255 Ratings
- Top rated: 3.4
- Lowest rated: 1
- Summary of article content: Articles about 반정규화와 성능 – DATA ON-AIR 비정규화는 아예 정규화를 수행하지 않은 모델을 지칭할 때 사용한다. 반정규화를 정의하면 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 … …
- Most searched keywords: Whether you are looking for 반정규화와 성능 – DATA ON-AIR 비정규화는 아예 정규화를 수행하지 않은 모델을 지칭할 때 사용한다. 반정규화를 정의하면 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 … 1. 반정규화를 통한 성능향상 전략 가. 반정규화의 정의 반정규화(=역정규화) 용어는 조금 다르게 표현되어도 그 의미는 동일하다. 여기에서 반정규화는 ‘반(Half)’의 의미가 아닌 한자로 반대하다의 의미를 가진 ‘反’의 의미이다. 영어로는 De-Normalization이다. 비정규화는 아예 정규화를 수행하지 않은 모델을 지칭할 때 사용한다. 반정규화를 정의하면 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발(Development)과 운영(Maintenance)의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법을 의미한다. 협의의 반정규화는 데이터를 중복하여 성능을 향상시키기 위한 기법이라고 정의할 수 있고 좀 더 넓은 의미의 반정규화는 성능을 향상시키기 위해 정규화된 데이터 모델에서 중복, 통합, 분리 등을 수행하는 모든 과정을 의미한다. 데이터 무결성이 깨질 수 있는 위험을 무릅쓰고 데이터를 중복하여 반정규화를 적용하는 이유는 데이터를 조회할 때 디스크 I/O량이 많아서 성능이 저하되거나 경로가 너무 멀어 조인으로 인한 성능저하가 예상되거나 칼럼을 계산하여 읽을 때 성능이 저하될 것이 예상되는 경우 반정규화를 수행하게 된다. 기본적으로 정규화는 입력/수정/삭제에 대한 성능을 향상시킬 뿐만 아니라 조회에 대해서도 성능을 향상시키는 역할을 한다. 그러나 정규화만을 수행하면 엔터티의 갯수가 증가하고 관계가 많아져 일부 여러 개의 조인이 걸려야만 데이터를 가져오는 경우가 있다. 이러한 경우 업무적으로 조회에 대한 처리성능이 중요하다고 판단될 때 부분적으로 반정규화를 고려하게 되는 것이다. 또한 정규화의 함수적 종속관계는 위반하지 않지만 데이터의 중복성을 증가시켜야만 데이터조회의 성능을 향상시키는 경우가 있다. 이러한 경우 반정규화를 통해서 성능을 향상시킬 수 있게 되는 것이다. 프로젝트에서는 설계단계에서 반정규화를 적용하게 되는데 반정규화를 기술적으로 수행하지 않는 경우에는 다음과 같은 현상이 발생된다. 성능이 저하된 데이터베이스가 생성될 수 있다. 구축단계나 시험단계에서 반정규화를 적용할 때 수정에 따른 노력비용이 많이 들게 된다. 나. 반정규화의 적용방법 반정규화도 하나의 난이도 높은 데이터 모델링의 실무기술이다. 보통 프로젝트에서는 칼럼 중복을 통해서만 반정규화를 수행하게 된다. 칼럼의 반정규화가 많은 이유는 개발을 하다가 SQL문장 작성이 복잡해지고 그에 따라 SQL단위 성능 저하가 예상이 되어 다른 테이블에서 조인하여 가져와야 할 칼럼을 기준이 되는 테이블에 중복하여 SQL문장을 단순하게 처리하도록 하기 위해 요청하는 경우가 많다. 이 때문에 칼럼의 반정규화 유형이 많이 나타나게 된다. 이렇게 무분별하게 칼럼의 반정규화를 많이 하게 되는 것은 데이터에 대한 무결성을 깨뜨리는 결정적인 역할을 하는 경우가 많이 있다. 반정규화에 대한 필요성이 결정이 되면 칼럼의 반정규화 뿐만 아니라 테이블의 반정규화와 관계의 반정규화를 종합적으로 고려하여 적용해야 한다. 또한 반정규화를 막연하게 중복을 유도하는 것만을 수행하기 보다는 성능을 향상시킬 수 있는 다른 방법들을 고려하고 그 이후에 반정규화를 적용하도록 해야 한다. 반정규화를 적용할 때는 기본적으로 데이터 무결성이 깨질 가능성이 많이 있기 때문에 반드시 데이터 무결성을 보장할 수 있는 방법을 고려한 이후에 반정규화를 적용하도록 해야 한다. 정규화와 반정규화 사이에는 Trade-Off 관계 즉, 마치 저울추가 양쪽에 존재하여 한쪽이 무거워지면 다른 쪽은 위로 올라가는 것처럼 정규화만을 강조하다 보면 성능의 이슈가 발생될 수 있고 반정규화를 과도하게 적용하다 보면 데이터 무결성이 깨질 수 있는 위험이 증가하게 되는 것이다. 따라서 반정규화를 적용할 때에는 데이터 무결성이 중요함을 알고 데이터 무결성이 충분히 유지될 수 있도록 프로세스 처리에 있어서 안정성이 먼저 확인이 되어야 한다. 반정규화를 적용하기 위해서는 [그림 Ⅰ-2-13]에 나타난 것처럼 먼저 반정규화의 대상을 조사하고 다른 방법을 적용할 수 있는지 검토하고 그 이후에 반정규화를 적용하도록 한다. 반정규화의 대상을 조사한다. 일단 전체 데이터의 양을 조사하고 그 데이터가 해당 프로세스를 처리할 때 성능저하가 나타날 수 있는지 검증해야 한다. 데이터가 대량이고 성능이 저하될 것으로 예상이 되면 다음 4가지 경우를 고려하여 반정규화를 고려하게 된다. – 자주 사용되는 테이블에 접근(Access)하는 프로세스의 수가 많고 항상 일정한 범위만을 조회하는 경우에 반정규화를 검토한다. – 테이블에 대량의 데이터가 있고 대량의 데이터 범위를 자주 처리하는 경우에 처리범위를 일정하게 줄이지 않으면 성능을 보장할 수 없을 경우에 반정규화를 검토한다. – 통계성 프로세스에 의해 통계 정보를 필요로 할 때 별도의 통계테이블(반정규화 테이블)을 생성한다. – 테이블에 지나치게 많은 조인(JOIN)이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우 반정규화를 검토한다. 반정규화의 대상에 대해 다른 방법으로 처리할 수 있는지 검토한다. 가급적이면 데이터를 중복하여 데이터 무결성을 깨뜨릴 위험을 제어하기 위하여 반정규화를 결정하기 이전에 성능을 향상시킬 수 있는 다른 방법을 모색하도록 한다. – 지나치게 많은 조인(JOIN)이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우 뷰(VIEW)를 사용하면 이를 해결할 수도 있다. 뷰가 조회의 성능을 향상시키는 역할을 수행하지는 않는다. 다만 개발자별로 SQL문장을 만드는 방법에 따라 성능저하가 나타날 수 있으므로 성능을 고려한 뷰를 생성하여 개발자가 뷰를 통해 접근하게 함으로써 성능저하의 위험을 예방하는 것도 좋은 방법이 된다. – 대량의 데이터처리나 부분처리에 의해 성능이 저하되는 경우에 클러스터링을 적용하거나 인덱스를 조정함으로써 성능을 향상시킬 수 있다. 클러스터링을 적용하는 방법은 대량의 데이터를 특정 클러스터링 팩트에 의해 저장방식을 다르게 하는 방법이다. 이 방법의 경우 데이터를 입력/수정/삭제하는 경우 성능이 많이 저하되므로 조회중심의 테이블이 아니라면 생성하면 안되는 오브젝트이다. 다만, 조회가 대부분이고 인덱스를 통해 성능향상이 불가능하다면 클러스터링을 고려할 만하다. 또한 인덱스를 통해 성능을 충분히 확보할 수 있다면 인덱스를 조정하여 반정규화를 회피하도록 한다. – 대량의 데이터는 Primary Key의 성격에 따라 부분적인 테이블로 분리할 수 있다. 즉 파티셔닝 기법(Partitioning)이 적용되어 성능저하를 방지할 수 있다. 인위적인 테이블을 통합/분리하지 않고 물리적인 저장기법에 따라 성능을 향상시킬 수 있는 파티셔닝을 고려해 볼 수 있다. 이 경우는 데이터가 특정 기준(파티셔닝 키)에 의해 다르게 저장되고 파티셔닝 키에 따른 조회가 될 때 성능이 좋아지는 특성이 있다. 따라서 특정 기준에 의해 물리적인 저장공간이 구분될 수 있고 트랜잭션이 들어올 때 일정한 기준에 의해 들어온다면 파티셔닝 테이블을 적용하여 조회의 성능을 향상시키는 것도 좋은 방법이 될 수 있다. – 응용 애플리케이션에서 로직을 구사하는 방법을 변경함으로써 성능을 향상시킬 수 있다. 응용 메모리 영역에 데이터를 처리하기 위한 값을 캐쉬한다든지 중간 클래스 영역에 데이터를 캐쉬하여 공유하게 하여 성능을 향상 시키는 것도 성능을 향상시키는 방법이 될 수 있다. 반정규화를 적용한다. 반정규화를 적용하기 이전에 사전에 충분히 성능에 대한 고려가 이루어져서 반정규화를 적용해야겠다는 판단이 들었다면 이 때 반정규화의 세 가지 규칙을 고려하여 반정규화를 적용하도록 한다. 반정규화를 하는 대상으로는 테이블, 속성, 관계에 대해 적용할 수 있으며 꼭 테이블과 속성, 관계에 대해 중복으로 가져가는 방법만이 반정규화가 아니고 테이블, 속성, 관계를 추가할 수도 있고 분할할 수도 있으며 제거할 수도 있다. 성능을 향상시킬 수 있는 포괄적인 방법을 적용하여 반정규화를 적용하는 것이 전문화된 반정규화의 기법임을 기억할 필요가 있다. 2. 반정규화의 기법 넓은 의미에서 반정규화를 고려할 때 성능을 향상시키기 위한 반정규화는 여러 가지가 나타날 수 있다. 가. 테이블 반정규화 나. 칼럼 반정규화 다. 관계 반정규화 테이블과 칼럼의 반정규화는 데이터 무결성에 영향을 미치게 되나 관계의 반정규화는 데이터 무결성을 깨뜨릴 위험을 갖지 않고서도 데이터처리의 성능을 향상시킬 수 있는 반정규화의 기법이 된다. 데이터 모델 전체가 관계로 연결되어 있고 관계가 서로 먼 친척간에 조인관계가 빈번하게 되어 성능저하가 예상이 된다면 관계의 반정규화를 통해 성능향상을 도모할 필요가 있다. 3. 정규화가 잘 정의된 데이터 모델에서 성능이 저하될 수 있는 경우 [그림 Ⅰ-2-14]는 공급자라고 하는 엔터티가 마스터이고 전화번호와 메일주소 위치가 각각 변경되는 내용이 이력형태로 관리되는 데이터 모델이다. 이 모델에서 공급자정보를 가져오는 경우를 가정해 보자. 공급자와 전화번호, 메일주소, 위치는 1:M 관계이므로 한 명의 공급자당 여러 개의 전화번호, 메일주소, 위치가 존재한다. 따라서 가장 최근에 변경된 값을 가져오기 위해서는 조금 복잡한 조인이 발생될 수 밖에 없다. 다음 SQL은 위와 같은 조건을 만족하는 SQL구문이 된다. SELECT A.공급자명, B.전화번호, C.메일주소, D.위치 FROM 공급자 A, (SELECT X.공급자번호, X.전화번호 FROM 전화번호 X, (SELECT 공급자번호, MAX(순번) 순번 FROM 전화번호 WHERE 공급자번호 BETWEEN ‘1001’ AND ‘1005’ GROUP BY 공급자번호) Y WHERE X.공급자번호 = Y.공급자번호 AND X.순번 = Y.순번) B, (SELECT X.공급자번호, X.메일주소 FROM 메일주소 X, (SELECT 공급자번호, MAX(순번) 순번 FROM 메일주소 WHERE 공급자번호 BETWEEN ‘1001’ AND ‘1005’ GROUP BY 공급자번호) Y WHERE X.공급자번호 = Y.공급자번호 AND X.순번 = Y.순번) C, (SELECT X.공급자번호, X.위치 FROM 위치 X, (SELECT 공급자번호, MAX(순번) 순번 FROM 위치 WHERE 공급자번호 BETWEEN ‘1001’ AND ‘1005’ GROUP BY 공급자번호) Y WHERE X.공급자번호 = Y.공급자번호 AND X.순번 = Y.순번) D WHERE A.공급자번호 = B.공급자번호 AND A.공급자번호 = C.공급자번호 AND A.공급자번호 = D.공급자번호 AND A.공급자번호 BETWEEN ‘1001’ AND ‘1005’ 정규화 된 모델이 적절하게 반정규화 되지 않으면 위와 같은 복잡한 SQL구문은 쉽게 나올 수 있다. 이른바 A4용지 5장으로 작성된 SQL이 쉽지 않게 발견될 수 있는 것이다. 위의 모델을 적절하게 반정규화를 적용하면 즉, 가장 최근에 변경된 값을 마스터에 위치시키면 다음과 같이 아주 간단한 SQL구문이 작성 된다. 위에서 복잡하게 작성된 SQL문장이 반정규화를 적용하므로 인해 다음과 같이 간단하게 작성이 되어 가독성도 높아지고 성능도 향상되어 나타났다. SELECT 공급자명, 전화번호, 메일주소, 위치 FROM 공급자 WHERE 공급자번호 BETWEEN ‘1001’ AND ‘1005’ 결과만 보면 너무 당연하고 쉬운 것 같지만 기억해야 할 사실은 위 내용들은 모두 실제로 프로젝트를 할 때도 이와 같이 SQL문장의 성능과 단순성을 고려하지 않고 무모하게 설계되는 경우가 많이 있다는 점이다. 4. 정규화가 잘 정의된 데이터 모델에서 성능이 저하된 경우 업무의 영역이 커지고 다른 업무와 인터페이스가 많아짐에 따라 데이터베이스서버가 여러 대인 경우가 있다. [그림 Ⅰ-2-16]은 데이터베이스서버가 분리 되어 분산데이터베이스가 구성되어 있을 때 반정규화를 통해 성능을 향상시킬 수 있는 경우이다. 서버A에 부서와 접수 테이블이 있고 서버B에 연계라는 테이블이 있는데 서버B에서 데이터를 조회할 때 빈번하게 조회되는 부서번호가 서버A에 존재하기 때문에 연계, 접수, 부서 테이블이 모두 조인이 걸리게 된다. 게다가 분산데이터베이스 환경이기 때문에 다른 서버간에도 조인이 걸리게 되어 성능이 저하되는 것이다. 위의 모델을 통해 서버B의 연계테이블에서 부서명에 따른 연계상태코드를 가져오는 SQL구문은 다음과 같이 작성된다. SELECT C.부서명, A.연계상태코드 FROM 연계 A, 접수 B, 부서 C <== 서버A와 서버B가 조인이 걸림 WHERE A.부서코드 = B.부서코드 AND A.접수번호 = B.접수번호 AND B.부서코드 = C.부서코드 AND A.연계일자 BETWEEN '20040801' AND '20040901' Oracle의 경우 DB LINK 조인이 발생하여 일반조인보다 성능이 저하될 것이다. 위의 분산 환경에 따른 데이터 모델을 다음과 같이 서버A에 있는 부서테이블의 부서명을 서버B의 연계테이블에 부서명으로 속성 반정규화를 함으로써 조회 성능을 향상시킬 수 있다. [그림 Ⅰ-2-17]의 모델에 대한 SQL구문은 다음과 같이 작성된다. SELECT 부서명, 연계상태코드 FROM 연계 WHERE 연계일자 BETWEEN '20040801' AND '20040901' SQL구문도 간단해지고 분산되어 있는 서버간에도 DB LINK 조인이 발생하지 않아 성능이 개선되었다. 반정규화를 적용할 때 기억해야 할 내용은 데이터를 입력, 수정, 삭제할 때는 성능이 떨어지는 점을 기억해야 하고 데이터의 무결성 유지에 주의를 해야 한다.
- Table of Contents:
[SQL] 정규화(Normalization)와 반정규화(De-Normalization)
- Article author: sodayeong.tistory.com
- Reviews from users: 3852 Ratings
- Top rated: 3.8
- Lowest rated: 1
- Summary of article content: Articles about [SQL] 정규화(Normalization)와 반정규화(De-Normalization) 반정규화란? · 데이터베이스의 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법이다. · 반정규화는 조회(select) … …
- Most searched keywords: Whether you are looking for [SQL] 정규화(Normalization)와 반정규화(De-Normalization) 반정규화란? · 데이터베이스의 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법이다. · 반정규화는 조회(select) … 정규화란? 정규화는 데이터의 일관성, 최소한의 데이터 중복, 최소한의 데이터 유연성을 위한 방법이며 데이터를 분해하는 과정이다. 정규화된 모델은 테이블이 분해된다. 테이블이 분해되면 직원 테이블과 부서..
- Table of Contents:
소품집
[SQL] 정규화(Normalization)와 반정규화(De-Normalization) 본문정규화란
정규화 절차
반정규화란
티스토리툴바
![[SQL] 정규화(Normalization)와 반정규화(De-Normalization)](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbjDo9i%2FbtqZRtay2yw%2FYtkTRGkPfZ34Lcg3gYP9N1%2Fimg.png)
반정규화
- Article author: velog.io
- Reviews from users: 26674 Ratings
- Top rated: 4.9
- Lowest rated: 1
- Summary of article content: Articles about 반정규화 반정규화의 유형 · Table Merge. Parent Table에 Child Table의 속성을 삽입하고 Child Table 삭제. · Redundat Column 추가 · Computed Column 추가 · Code … …
- Most searched keywords: Whether you are looking for 반정규화 반정규화의 유형 · Table Merge. Parent Table에 Child Table의 속성을 삽입하고 Child Table 삭제. · Redundat Column 추가 · Computed Column 추가 · Code … 가. 반정규화의 필요성정규화 시 빈번한 Join이 필요하여 검색 시간이 과다하게 소요나. 정규화 고려사항정합성과 데이터 무결성, 성능과 테이블 단순화의 Trade off를 검토다. 반정규화의 대상자주 사용되는 테이블에 접근하는 프로세스 수가 많고, 항상 일정한 범위만을
- Table of Contents:
반정규화란? 반정규화의 다양한 유형(중복 테이블 추가, 테이블 조합 등) 쉽게 설명!
- Article author: iworldt.tistory.com
- Reviews from users: 46386 Ratings
- Top rated: 3.7
- Lowest rated: 1
- Summary of article content: Articles about 반정규화란? 반정규화의 다양한 유형(중복 테이블 추가, 테이블 조합 등) 쉽게 설명! 반정규화의 유형 · 1. 중복 테이블 추가 · 2. 테이블 조합 · 3. 테이블 분할 · 4. 테이블 제거 · 5. 칼럼의 중복화. …
- Most searched keywords: Whether you are looking for 반정규화란? 반정규화의 다양한 유형(중복 테이블 추가, 테이블 조합 등) 쉽게 설명! 반정규화의 유형 · 1. 중복 테이블 추가 · 2. 테이블 조합 · 3. 테이블 분할 · 4. 테이블 제거 · 5. 칼럼의 중복화. 이번 포스팅은 지난 정규화(https://iworldt.tistory.com/99) 에 이어 반정규화에 대해 알아보겠습니다. 반정규화 Denormalization 반정규화의 정의 정규화에 충실하여 모델링을 수행하면 종속성, 활용성은 향상되..
- Table of Contents:
태그
관련글
댓글0
최근글
인기글
티스토리툴바

시험장에 몰래 가져갈 이경오의 SQL+SQLD 비밀노트: 국가 공인 SQL 개발자 자격증 … – 이경오 – Google Sách
- Article author: books.google.com.vn
- Reviews from users: 24130 Ratings
- Top rated: 5.0
- Lowest rated: 1
- Summary of article content: Articles about 시험장에 몰래 가져갈 이경오의 SQL+SQLD 비밀노트: 국가 공인 SQL 개발자 자격증 … – 이경오 – Google Sách Updating …
- Most searched keywords: Whether you are looking for 시험장에 몰래 가져갈 이경오의 SQL+SQLD 비밀노트: 국가 공인 SQL 개발자 자격증 … – 이경오 – Google Sách Updating 공공 데이터로 SQL 기본부터 실무 활용, 그리고 SQLD 자격증까지 한번에 끝낸다! 이 책은 IT 전공자를 포함한 일반인도 SQL을 더 수월하게 학습을 할 수 있도록 다음과 같이 구성했습니다. ① 손쉬운 설치 환경 : 손쉽게 오라클 DBMS를 설치하고, 설치한 DBMS를 활용할 수 있는 DBMS 도구도 설치해봅니다.② 실생활 밀접 데이터 : 전국의 상가 상권 정보, 지하철역 승하차, 인구 정보 등 일상 생활과 밀접하게 관련 있는 공공 데이터를 기반으로 실습합니다.③ SQLD 완벽 대응 : 국가 공인 SQL 개발자(SQLD) 자격증의 커리큘럼과 동일한 이론 및 실습을 제공합니다.④연습문제 + 풀이 제공 : 공공 데이터를 기반으로 이론 및 실습을 진행하고, 연습문제 풀이를 통해 이해의 깊이를 더합니다.⑤ 헷갈리기 쉬운 패턴만 따로 모은 비밀노트 제공 SQL을 사용하면서 헷갈리기 쉬운 패턴을 따로 정리하여 실무 능력을 최대치로 끌어올립니다. 데이터 뉴딜 시대, SQL을 통한 공공 데이터 분석 도서가 나왔다! 수없이 쏟아지는 데이터 속에서 SQL은 이제 IT 개발자뿐 아니라 비전공 실무자도 배워야 하는 필수 아이템이 되었습니다. 이 책은 프로그래밍 지식이 없는 입문자도 공공 데이터를 쉽게 활용하여 SQL의 핵심 개념과 원리를 배우고, 더불어 자격증 취득까지 준비할 수 있는 책입니다. 전국 상가 상권 정보, 지하철역 승하차 데이터, 인구 정보 등 우리 실생활과 맞닿아 있는 데이터로 실습하며 데이터와 친해지고, 데이터베이스를 직접 구축해보며 SQL과 DB의 감을 잡습니다.또한 쿼리문을 직접 작성해보면서 실무 능력을 향상시켜 레벨업하도록 구성했습니다. 관련 자격증이 필요하다면 이 책 한 권으로 충분합니다. 꼭 필요한 이론과 실전 연습문제만으로도 완벽히 준비할 수 있습니다. 『소문난 명강의: 이경오의 SQL+SQLD 비밀노트』와 함께 지금 바로 시작하세요!
- Table of Contents:
반정규화(De-normalization)
- Article author: sanggil.tistory.com
- Reviews from users: 28071 Ratings
- Top rated: 4.7
- Lowest rated: 1
- Summary of article content: Articles about 반정규화(De-normalization) 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법을 의미 … …
- Most searched keywords: Whether you are looking for 반정규화(De-normalization) 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법을 의미 … 1. 반정규화의 개념(약술형) 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법을 의미한다. 둘 이상의 릴레이션들에..
- Table of Contents:
반정규화(De-normalization)
티스토리툴바
데이터베이스 반정규화 > 도리의 디지털라이프
- Article author: blog.skby.net
- Reviews from users: 11502 Ratings
- Top rated: 3.1
- Lowest rated: 1
- Summary of article content: Articles about 데이터베이스 반정규화 > 도리의 디지털라이프 I. 성능 향상을 위한 데이터 중복 허용, 반정규화 ; 데이터베이스 정규화 후 성능향상, 개발편의성 등 위해 정규화기법 위배행위 의도적 수행 기법, – 다수 … …
- Most searched keywords: Whether you are looking for 데이터베이스 반정규화 > 도리의 디지털라이프 I. 성능 향상을 위한 데이터 중복 허용, 반정규화 ; 데이터베이스 정규화 후 성능향상, 개발편의성 등 위해 정규화기법 위배행위 의도적 수행 기법, – 다수 …
- Table of Contents:
도리의 디지털라이프
I 성능 향상을 위한 데이터 중복 허용 반정규화
II 반정규화 필요 대상 및 유형
III 반정규화 절차
IV 반정규화 시 고려사항
 Read More
Read More
[2021 정보처리기사-3과목] 반정규화(Denormalization)
- Article author: y-oni.tistory.com
- Reviews from users: 19916 Ratings
- Top rated: 4.2
- Lowest rated: 1
- Summary of article content: Articles about [2021 정보처리기사-3과목] 반정규화(Denormalization) 반정규화란 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터를 통합, 중복, 분리하는 과정으로 의도적으로 정규화 원칙을 위배 … …
- Most searched keywords: Whether you are looking for [2021 정보처리기사-3과목] 반정규화(Denormalization) 반정규화란 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터를 통합, 중복, 분리하는 과정으로 의도적으로 정규화 원칙을 위배 … [정보처리기사 3과목 필기 예상 키워드] 목록으로 돌아가기 과목: 3. 데이터베이스 구축 챕터: 1장 논리 DB 설계 키워드: 반정규화(Denormalization) #반정규화 목차 반정규화(Denormalization)의 개념 반..
- Table of Contents:
태그
‘2021 정보처리기사3과목 데이터베이스 구축’ 관련글
Comments
티스토리툴바
![[2021 정보처리기사-3과목] 반정규화(Denormalization)](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdDYzPm%2Fbtq2Zoc3wwC%2FrfZTblFkL1TjF9LT8c272k%2Fimg.png)
SQLD – 과목1. (8) 반정규화와 성능
- Article author: chae-developer.tistory.com
- Reviews from users: 17403 Ratings
- Top rated: 3.0
- Lowest rated: 1
- Summary of article content: Articles about SQLD – 과목1. (8) 반정규화와 성능 : 反 (되돌릴 반) 의 ‘반’ 이다. · De – Normalization. · 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위해 · 중복, … …
- Most searched keywords: Whether you are looking for SQLD – 과목1. (8) 반정규화와 성능 : 反 (되돌릴 반) 의 ‘반’ 이다. · De – Normalization. · 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위해 · 중복, … 1. 반정규화를 통한 성능향상 전략 ① 반정규화의 정의 ▷ 반정규화 ( = 역정규화 ) : 反 (되돌릴 반) 의 ‘반’ 이다. De – Normalization. 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발..
- Table of Contents:
티스토리 뷰
티스토리툴바

See more articles in the same category here: Chewathai27.com/to/blog.
3-1-14장. 반정규화(Denormalization)
반응형
반정규화의 개념
반정규화란 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙을 위배하는 행위이다.
반정규화를 수행하면 시스템의 성능이 향상되고 관리 효율성을 증가하지만 데이터의 일관성 및 정합성이 저하될 수 있음
과도한 반정규화는 오히려 성능을 저하시킴
반정규화를 위해서는 사전에 데이터의 일관성과 무결성을 우선으로 할지, 데이터베이스의 성능과 단순화를 우선으로 할지를 결정해야 함
반정규화 방법에는 테이블 통합, 테이블 분할, 중복 테이블 추가, 중복 속성 추가 등이 있음
테이블 통합
테이블 통합은 두 개의 테이블이 조인되는 경우가 많아 하나의 테이블로 합쳐 사용하는 것이 성능 향상에 도움이 될 경우 수행한다.
두 개의 테이블에서 발생하는 프로세스가 동일하게 자주 처기되는 경우, 두 개의 테이블을 이용하여 항상 조회를 수행하는 경우 테이블 통합을 고려
테이블 통합의 종류에는 1:1 관계 테이블 통합, 1:N 관계 테이블 통합, 슈퍼타입/서브타입 테이블 통합이 있음
테이블 통합 시 고려 사항 데이터 검색은 간편하지만 레코드 증가로 인해 처리량이 증가 테이블 통합으로 인해 입력, 수정, 삭제 규칙이 복잡해질 수 있음 Not Null, Default, Check 등의 제약조건을 설계하기 어려움
테이블 분할
테이블 분할은 테이블을 수직 또는 수평으로 분할하는 것이다.
수평 분할 수평 분할은 레코드를 기준으로 테이블을 분할하는 것 레코드별로 사용 빈도의 차이가 큰 경우 사용 빈도에 따라 테이블을 분할함
수직 분할 수직 분할은 하나의 테이블에 속성이 너무 많을 경우 속성을 기준으로 테이블을 분할하는 것 갱신 위주의 속성 분할 : 데이터 갱신 시 레코드 잠금으로 인해 다른 작업을 수행 할 수 없으므로 갱신이 자주 일어나는 속성들을 수직 분할하여 사용 자주 조회되는 속성 분할 : 자주 조회되는 속성이 극히 일부일 경우 그 속성들을 수직 분할하여 사용 크기가 큰 속성 분할 : 이미지나 2GB 이상 저장될 수 있는 텍스트 형식 등으로 된 속성들을 수직 분할하여 사용 보안을 적용해야하는 속성 분할 : 특정 속성에 대해 보안을 적용할 수 없으므로 보안을 적용해야 하는 속성들을 수직 분할하여 사용
테이블 분할 시 고려 사항 기본키의 유일성 관리가 어려워짐 데이터 양이 적거나 사용 빈도가 낮은 경우 테이블 분할이 필요한지를 고려해야 함 분할된 테이블로 인해 수행 속도가 느려질 수 있음 데이터 검색에 중점을 두어 테이블 분할 여부를 결정
중복 테이블 추가
여러 테이블에서 데이터를 추출해서 사용해야 하거나 다른 서버에 저장된 테이블을 이용해야 하는 경우 중복 테이블을 추가하여 작업의 효율성을 향상시킬 수 있다.
중복 테이블을 추가하는 경우 정규화로 인해 수행 속도가 느려지는 경우 많은 범위의 데이터를 자주 처리해야 하는 경우 특정 범위의 데이터만 자주 처리해야 하는 경우 처리 범위를 줄이지 않고는 수행 속도를 개선할 수 없는 경우
중복 테이블을 추가하는 방법 집계 테이블 의 추가 : 집계 데이터를 위한 테이블을 생성하고, 각 원본 테이블에 트리거를 설정하여 사용하는 것으로, 트리거 오버헤드에 유의해야 함 진행 테이블 의 추가 : 이력 관리 등의 목적으로 추가하는 테이블로, 적절한 데이터 양의 유지와 활용도를 높이기 위해 기본키를 적절히 설정 특정 부분만을 포함하는 테이블 의 추가 : 데이터가 많은 테이블의 특정 부분만을 사용하는 경우 해당 부분만으로 새로운 테이블을 생성
중복 속성 추가
중복 속성 추가는 조인해서 데이터를 처리할 때 데이터를 조회하는 경로를 단축하기 위해 자주 사용하는 속성을 하나 더 추가하는 것이다.
중복 속성을 추가하면 데이터의 무결성 확보가 어렵고, 디스크 공간이 추가로 필요
중복 속성을 추가하는 경우 조인이 자주 발생하는 속성 접근 경로가 복잡한 속성 액세스의 조건으로 자주 사용되는 속성 기본키의 형태가 적절하지 않거나 여러 개의 속성으로 구성된 경우
중복 속성 추가 시 고려 사항 테이블 중복과 속성의 중복 고려 데이터 일관성 및 무결성에 유의 SQL 그룹 함수를 이용하여 처리할 수 있어야 함 저장 공간의 지나친 낭비 고려
반응형
[SQL] 정규화(Normalization)와 반정규화(De-Normalization)
정규화란?
정규화는 데이터의 일관성, 최소한의 데이터 중복, 최소한의 데이터 유연성을 위한 방법이며 데이터를 분해하는 과정이다.
정규화된 모델은 테이블이 분해된다. 테이블이 분해되면 직원 테이블과 부서 테이블 간에 부서코드로 조인(join)을 수행하며 하나의 합집합으로 만들 수 있다.
정규화를 하면 불필요한 데이터를 입력하지 않아도 되기 때문에 중복 데이터가 제거된다.
정규화 절차
정규화의 문제점
정규화는 데이터 조회(select) 시에 조인(join)을 유발하기 때문에 CPU와 메모리를 많이 사용한다.
아래 코드를 프로그램화 한다면 중첩된 루프(Nested Loop)를 사용해야 한다.
[ANSI JOIN} select 사원번호, 부서코드, 부서명, 이름, 전화번호, 주소 from 직원, 부서 where 직원.부서코드 = 부서.부서코드; select 사원번호, 부서코드, 부서명, 이름, 전화번호, 주소 from 직원 inner join 부서 on직원.부서코드=부서.부서코드;정규화를 사용한 성능 튜닝
조인으로 인하여 성능이 저하되는 문제를 반정규화로 해결할 수 있다.
반정규화는 데이터를 중복시키기 때문에 또 다른 문제점을 발생시킨다.
반정규화란?
데이터베이스의 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법이다.
반정규화는 조회(select) 속도를 향상시키지만, 데이터 모델의 유연성은 낮아진다.
반정규화를 수행하는 이유
정규화에 충실하여 종속성, 활용성은 향상 되었지만 수행속도가 느려진 경우
다량의 범위를 자주 처리해야하는 경우
특정 범위의 데이터만 자주 처리하는 경우
요약/집계 정보가 자주 요구되는 경우
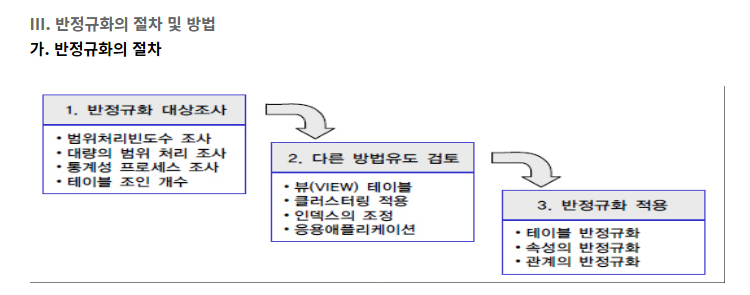
반정규화 절차
[Clustering?]클러스터링 인덱스라는 것은 인덱스 정보를 저장할 때, 물리적으로 정렬해서 저장하는 방법이다.
따라서 조회 시 인접 블록을 연속적으로 읽기 때문에 성능이 향상된다.
반정규화 기법
계산된 컬럼 추가
배치 프로그램으로 총판매액, 평균잔고, 계좌평가를 미리 계산하고 그 결과를 특정 칼럼에 추가한다.
테이블 수직 분할
하나의 테이블의 두 개 이상의 테이블로 분할한다. 즉, 칼럼을 분할하여 새로운 테이블을 만드는 것이다.
테이블 수평분할
하나의 테이블에 있는 값을 기준으로 테이블을 분할하는 방법이다.
[Partition] – 데이터베이스에서 파티션을 사용하여 테이블을 분할할 수 있다. – 파티션을 사용하면 논리적으로는 하나의 테이블이지만, 여러 개의 데이터 파일에 분산되어 저장된다. – Range Partition: 데이터 값의 범위를 기준으로 파티션을 수행한다. – List Partition: 특정한 값을 지정하여 파티션을 수행한다. – Hash Partition: 해시 함수를 적용하여 파티션을 수행한다. – Composite Partition: 범위와 해시를 복합적으로 사용하여 파티션을 수행한다.테이블 병합
1:1 관계의 테이블을 하나의 테이블로 병합해서 성능을 향상시킨다.
1:N 관계의 테이블을 병합하여 성능을 향상시킨다. 하지만 많은 양의 데이터 중복이 발생한다.
슈퍼 타입과 서브 타입 관계가 발생하면 테이블을 통합하여 성능을 향상시킨다.\
[Super type과 Sub type] – 슈퍼타입과 서브타입의 관계는 배타적 관계와 포괄적 관계가 있는데, 배타적 관계는 고객이 개인이거나 법인고객인 경우를 의미한다. – 포괄적인 관계는 고객이 개인고객일 수도 있고 법인고객일 수도 있는 것이다.슈퍼 타입 및 서브 타입 변환 방법
728×90
반정규화란? 반정규화의 다양한 유형(중복 테이블 추가, 테이블 조합 등) 쉽게 설명!
반응형
이번 포스팅은 지난 정규화(https://iworldt.tistory.com/99) 에 이어 반정규화에 대해 알아보겠습니다.
반정규화 Denormalization
반정규화의 정의
정규화에 충실하여 모델링을 수행하면 종속성, 활용성은 향상되나 수행속도가 증가 하는 경우가 발생하여 이를 극복하기 위해 성능에 중점을 두어 정규화하는 방법
-> 과도한 정규화로 인해 오히려 더 복잡해진 경우, 정규화를 풀어낸다고 생각하시면 되겠습니다.
반정규화의 특징
– 데이터 모델링 규칙에 얽매이지 않고 수행한다.
– 시스템이 물리적으로 구현되었을 때 성능향상을 목적으로 한다.
반정규화 사용 시기
반정규화가 필요한 때, 반정규화 언제 하는지?
(1) 정규화에 충실하였으나 수행속도에 문제가 있는 경우
(2) 다량의 범위를 자주 처리해야 하는 경우
(3) 특정범위의 데이터만 자주 처리하는 경우
(4) 처리범위를 줄이지 않고는 수행속도를 개선할 수 없는 경우
(5) 요약 자료만 주로 요구되는 경우
(6) 추가된 테이블의 처리를 위한 오버헤드를 고려하여 결정
(7) 인덱스의 조정이나 부분범위처리로 유도하고, 클러스터링을 이용하여 해결할 수 있는 지를 철저히 검토 후 결정
반정규화의 유형
1. 중복 테이블 추가
– 다량의 범위를 자주 처리하는 경우
– 특정 범위의 데이터만 자주 처리되는 경우
– 처리범위를 줄이지 않고는 수행속도를 개선할 수 없는 경우
-> 자주 쓰이는 부분이 뭉쳐있을 때, 내용이 중복되더라도 테이블을 하나 추가하는 방법입니다.
중복 테이블 추가 방법
– 집계 테이블의 추가 활용하고자 하는 집계정보를 위한 테이블을 추가하고, 각 원본테이블에 트리거를 등록시켜 생성하여 활용하는데, 이때 트리거의 오버헤드에 유의해야 한다.
– 진행 테이블의 추가 이력관리 등의 목적으로 사용되며 활용도가 좋아지도록 기본키를 적절히 설정 하여야 한다.
– 특정 부분만을 포함하는 테이블 추가 거대한 테이블의 특정 부분만을 사용하는 경우 자주 사용되는 부분으로 새로운 테이블 생성하여 활용한다.
2. 테이블 조합
– 대부분 처리가 두 개 이상의 테이블에 대해 항상 같이 일어나는 경우에 활용한다.
->데이터를 사용할 때, 자꾸 두세개의 테이블을 엮어서 쓰게 된다면 그 테이블들을 아예 합쳐버리는 방법입니다.
테이블 조합 방법
– 해당 테이블을 통합하여 설계한다.
테이블 조합 고려사항
– 데이터 액세스가 보다 간편하지만 Row수가 증가하여 처리량이 증가하는 경우가 발생될 수 있으므로 이를 고려해야 한다.
– 입력, 수정, 삭제 규칙이 복잡해질 수 있음에 유의해야 한다.
– Not Null, Default, Check 등의 Constraint를 완벽히 설계하기 어려운 점이 있다.
3. 테이블 분할
– 칼럼의 사용빈도의 차이가 많은 경우
– 각각의 사용자가 각기 특정한 부분만 지속적으로 사용하는 경우
– 상황에 따라 SUPER-TYPE을 모두 내려 SUB-TYPE 별로 분할하거나 SUPER-TYPE 만은 따로 테이블을 생성하는 경우
-> 한 테이블에서 자주 쓰이는 칼럼과 아닌 부분으로 나뉜다거나, 1연산에는 이 칼럼들, 2연산에는 저 칼럼들만 사용하는 식으로 그룹져 있을 때 그 칼럼들을 그냥 나누어 여러 테이블로 분할하는 방법입니다.
테이블 분할 방법
– 수직 분할 칼럼별 사용빈도의 차이가 많은 경우 자주 사용되는 칼럼들과 그렇지 않은 칼럼으로 분류하여 테이블을 분할하는 방법이다.
– 수평 분할 특정 범위별 사용 빈도의 차이가 많은 경우 해당 범위 별로 테이블을 분할하 는 방법이다.
테이블 분할 고려사항
– 특정 칼럼 또는 범위를 사용하지 않는 경우 수행속도에 많은 영향이 있음을 고려 해야 한다.
– 기본키의 유일성 관리가 어려워진다.
– 액세스 빈도나 처리할 데이터양이 적은 경우는 분할이 불필요함을 고려하여야 한다.
– 분할된 테이블은 오히려 수행속도를 나쁘게 하기도 함에 유의하여야 한다.
– 데이터 프로세싱 관점이 아니라 검색에 중점을 두어 결정하여야 한다.
4. 테이블 제거
– 테이블 재정의나 칼럼의 중복화로 더 이상 액세스 되지 않는 테이블 발생할 경우
-> 정규화와 반정규화를 거치면서 안쓰이게 되어버린 테이블이 생겼을 때 제거하는 것입니다.
테이블 제거 방법
– 해당 테이블을 삭제한다.
테이블 제거 고려사항
– 관리 소홀로 인해, 누락시 유지보수 단계에서 많이 발생하는 현상임을 고려해야 한다.
– 유지보수 단계에서 초기 설계 시 예상하지 못했던 새로운 요구사항이 증가하게되면 눈앞의 해결에만 급급하여 테이블의 추가나 변경이 함부로 일어나게 되어 시스템은 일관성과 통합성이 무너지게 된다는 사실을 간과해서는 안된다.
5. 칼럼의 중복화
– 자주 사용되는 칼럼이 다른 테이블에 분산되어 있어 상세한 조건에도 불구하고 액세스 범위를 줄이지 못하는 경우
– 대량 데이터에서 Row별 연산 결과를 얻고자 할 때 성능향상을 위한 파생(Derived) 칼럼을 추가할 경우
– 기본키의 형태가 적절하지 않거나 너무 많은 칼럼으로 구성된 경우
– 정규화 규칙에 얽매이지 않으면서 성능향상을 목적으로 한 반정규화(Denomalization)를 통한 중복 데이터를 허용하는 경우
-> 자주 쓰이는 컬럼, 예를 들어 주민번호 컬럼이 모든 테이블의 외래키로 참조되면서 그 테이블들의 기본키가 되는 경우가 있겠습니다. 계속해서 다른 테이블을 참조해야하고, 한 테이블의 기본키들이 많으면서 외래키들로 구성된 경우, 그냥 그 외래키를 그 테이블의 기본키로 중복해서 생성시켜버리는 방법입니다. 너무 많은 테이블들간의 관계를 지운다고 생각하시면 되겠습니다.
칼럼의 중복화 방법
– 필요한 해당 테이블이나 칼럼을 추가한다.
칼럼의 중복화 고려사항
– 테이블 중복과 칼럼의 중복을 고려한다.
– 데이터 일관성 및 무결성에 유의해야 한다.
– SQL Group Function을 이용하여 해결 가능한지 검토한다.
– 저장공간의 지나친 낭비를 고려해야 한다.
반정규화 유형 요약(출처:ncs 데이터입출력구현 학습모듈)
이번 포스팅은 이렇게 정규화에 이어 반정규화까지 자세히 알아보았습니다.
정규화는 논리 데이터 모델링에서 진행하고, 이후 물리 데이터 모델링 시에 반정규화를 수행한다는 것을 알아두시면 되겠습니다.
728×90
반응형
So you have finished reading the 반 정규화 topic article, if you find this article useful, please share it. Thank you very much. See more: 반정규화 예시, 반정규화란, 반정규화 방법, 반정규화 역정규화, 반정규화 비정규화, 컬럼 반정규화, 반정규화 유형, 정보처리기사 반정규화