
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 부스팅 모델 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://chewathai27.com/to team, along with other related topics such as: 부스팅 모델 부스팅 뜻, 부스팅 알고리즘, Boosting 기법, Boosting 장점, 앙상블 모델 종류, 부스팅 단점, 앙상블 모델 구현, Bagging, Boosting
부스팅이란 무엇인가요? 기계 학습에서 부스팅에 대한 가이드 – AWS
- Article author: aws.amazon.com
- Reviews from users: 4816
 Ratings
Ratings - Top rated: 4.0
- Lowest rated: 1
- Summary of article content: Articles about 부스팅이란 무엇인가요? 기계 학습에서 부스팅에 대한 가이드 – AWS 예를 들어 흰색 고양이의 이미지에 대해서만 고양이 식별 모델을 훈련한 경우, 가끔 검은색 고양이를 잘못 식별할 수 있습니다. 부스팅은 여러 모델을 순차적으로 훈련하여 … …
- Most searched keywords: Whether you are looking for 부스팅이란 무엇인가요? 기계 학습에서 부스팅에 대한 가이드 – AWS 예를 들어 흰색 고양이의 이미지에 대해서만 고양이 식별 모델을 훈련한 경우, 가끔 검은색 고양이를 잘못 식별할 수 있습니다. 부스팅은 여러 모델을 순차적으로 훈련하여 … 부스팅이란 무엇이고, AI/ML과 어떻게 작동하고, AWS의 기계 학습에서 부스팅을 어떻게 사용하는지에 대해 알아보세요.
- Table of Contents:
기계 학습에서 부스팅이란 무엇인가요
부스팅이 중요한 이유는 무엇인가요
부스팅은 어떻게 작동하나요
부스팅에서의 훈련은 어떻게 이뤄지나요
부스팅 유형에는 무엇이 있나요
부스팅을 사용하면 어떤 이점이 있나요
부스팅의 어려움에는 무엇이 있나요
AWS는 부스팅으로 어떤 도움을 줄 수 있나요
AWS 기계 학습 다음 단계
[ML/DL] 앙상블 학습 (Ensemble Learning): 3.Boosting(부스팅)이란? — 나무늘보의 개발 블로그
- Article author: continuous-development.tistory.com
- Reviews from users: 24290 Ratings
- Top rated: 3.1
- Lowest rated: 1
- Summary of article content: Articles about [ML/DL] 앙상블 학습 (Ensemble Learning): 3.Boosting(부스팅)이란? — 나무늘보의 개발 블로그 지금 캐글에서 가장 많이 인기있는 앙상블 모델 중 하나이다. Boosting의 종류. XG boosting – 경사 하강법을 통한 부스팅 방식. Gradient Boosting – … …
- Most searched keywords: Whether you are looking for [ML/DL] 앙상블 학습 (Ensemble Learning): 3.Boosting(부스팅)이란? — 나무늘보의 개발 블로그 지금 캐글에서 가장 많이 인기있는 앙상블 모델 중 하나이다. Boosting의 종류. XG boosting – 경사 하강법을 통한 부스팅 방식. Gradient Boosting – … Boosting(부스팅)이란? 여러 개의 분류기가 순차적으로 학습을 수행한다. 이때 이전 분류기가 예측이 틀린 데이터에 대해 올바르게 예측할 수 있도록 가중치를 부여하면서 학습과 예측을 진행한다. 이런 방식으로..
- Table of Contents:
부스팅 구현(AdaBoostClassifier)
티스토리툴바
![[ML/DL] 앙상블 학습 (Ensemble Learning): 3.Boosting(부스팅)이란? — 나무늘보의 개발 블로그](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FclQ4UJ%2FbtqMDznC9E7%2Fqqwm92Jw6p4xQwcIhrAUKK%2Fimg.jpg)
부스팅 알고리즘 (Boosting Algorithm)
- Article author: velog.io
- Reviews from users: 32776 Ratings
- Top rated: 4.7
- Lowest rated: 1
- Summary of article content: Articles about 부스팅 알고리즘 (Boosting Algorithm) 즉, 약한 학습기들을 결합하여 강한 예측 모형을 만드는 것이다. 부스팅 알고리즘이란. 여러 개의 알고리즘이 순차적으로 학습-예측을 하면서 이전에 학습 … …
- Most searched keywords: Whether you are looking for 부스팅 알고리즘 (Boosting Algorithm) 즉, 약한 학습기들을 결합하여 강한 예측 모형을 만드는 것이다. 부스팅 알고리즘이란. 여러 개의 알고리즘이 순차적으로 학습-예측을 하면서 이전에 학습 … 부스팅(Boosting)
부스팅은 머신러닝 앙상블 기법 중 하나로 약한 학습기(weak learner)들을 순차적으로 여러개 결합하여 예측 혹은 분류 성능을 높이는 알고리즘이다.
- Table of Contents:

머신러닝 – 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)
- Article author: bkshin.tistory.com
- Reviews from users: 38252 Ratings
- Top rated: 3.9
- Lowest rated: 1
- Summary of article content: Articles about 머신러닝 – 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting) 그리하여 모델의 정확성이 향상됩니다. 앙상블 학습법에는 두 가지가 있습니다. 배깅(Bagging)과 부스팅(Boosting)입니다. …
- Most searched keywords: Whether you are looking for 머신러닝 – 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting) 그리하여 모델의 정확성이 향상됩니다. 앙상블 학습법에는 두 가지가 있습니다. 배깅(Bagging)과 부스팅(Boosting)입니다. 앙상블(Ensemble) 앙상블은 조화 또는 통일을 의미합니다. 어떤 데이터의 값을 예측한다고 할 때, 하나의 모델을 활용합니다. 하지만 여러 개의 모델을 조화롭게 학습시켜 그 모델들의 예측 결과들을 이용한다면..
- Table of Contents:
귀퉁이 서재
머신러닝 – 11 앙상블 학습 (Ensemble Learning) 배깅(Bagging)과 부스팅(Boosting) 본문
티스토리툴바
앙상블 학습 – 부스팅(boosting) 알고리즘 개념 잡기
- Article author: moondol-ai.tistory.com
- Reviews from users: 26979 Ratings
- Top rated: 3.4
- Lowest rated: 1
- Summary of article content: Articles about 앙상블 학습 – 부스팅(boosting) 알고리즘 개념 잡기 부스팅은 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법을 말합니다. 부스팅 방법의 아이디어는 앞의 모델을 보완해나가면서 … …
- Most searched keywords: Whether you are looking for 앙상블 학습 – 부스팅(boosting) 알고리즘 개념 잡기 부스팅은 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법을 말합니다. 부스팅 방법의 아이디어는 앞의 모델을 보완해나가면서 … 해당 글은 핸즈온 머신러닝 2판을 기준으로 작성되었습니다. 앙상블 학습(ensemble learning)은 일련의 예측기(분류 or 회귀 모델)로부터 예측을 수집하여 하나의 모델을 사용했을 때보다 더 좋은 예측을 얻을 수..
- Table of Contents:
태그
‘문돌이 존버데이터 분석’ 관련글
티스토리툴바

XGBoost와 사이킷런을 활용한 그레이디언트 부스팅: 캐글 고수에게 배우는 실전 … – 코리 웨이드 – Google Sách
- Article author: books.google.com.vn
- Reviews from users: 8776 Ratings
- Top rated: 4.4
- Lowest rated: 1
- Summary of article content: Articles about XGBoost와 사이킷런을 활용한 그레이디언트 부스팅: 캐글 고수에게 배우는 실전 … – 코리 웨이드 – Google Sách Updating …
- Most searched keywords: Whether you are looking for XGBoost와 사이킷런을 활용한 그레이디언트 부스팅: 캐글 고수에게 배우는 실전 … – 코리 웨이드 – Google Sách Updating 캐글 우승자들의 머신러닝 우승 비법이자 현존하는 가장 우월한 머신러닝 모델 XGBoost 이 책은 기본적인 머신러닝과 판다스부터 사용자 정의 변환기, 파이프라인과 희소 행렬로 새로운 데이터의 예측을 만드는 강력한 XGBoost 모델 튜닝까지 모두 다룹니다. 또한 XGBoost의 탄생 배경과 XGBoost를 특별하게 만드는 수학적 이론과 기술, 물리학자와 천문학자가 우주를 연구하는 사례 연구까지 다양한 XGBoost의 흥미로운 이야기와 캐글 마스터들의 우승 비법까지 소개합니다. 마지막으로 더 확실한 이해를 위해 원서에는 없는 친절하고 상세한 역자 노트와 다른 그레이디언트 부스팅 라이브러리를 배울 수 있는 한국어판만의 부록을 추가하여 내용을 더욱 가득 채웠습니다. 이 책 한 권이면 복잡한 XGBoost 개념을 완벽하게 이해하고 제품을 위한 머신러닝을 구축해볼 수 있게 됩니다. 그레이디언트 부스팅을 현업에 적용해보고 싶은 머신러닝 엔지니어나 캐글 대회를 준비하고 있는 캐글 도전자에게 훌륭한 안내서가 되어줄 것입니다. 데이터 과학 전문가를 위한 XGBoost와 사이킷런 활용법 XGBoost는 빠르고 효율적으로 수십억 개의 데이터 포인트에 적용하기 위한 그레이디언트 부스팅 프레임워크로, 업계에서 입증된 오픈 소스 소프트웨어 라이브러리입니다. 이 책은 그레이디언트 부스팅에 대한 이론을 설명하기 전에 사이킷런으로 머신러닝과 XGBoost를 소개합니다. 결정 트리를 다루고 머신러닝 관점에서 배깅을 분석하며 XGBoost까지 확장되는 하이퍼파라미터를 배우겠습니다. 밑바닥부터 그레이디언트 부스팅 모델을 구축해보고 그레이디언트 부스팅을 빅 데이터로 확장하면서 속도의 중요성을 설명합니다. 그리고 속도 향상 및 수학적인 이론에 초점을 두고 XGBoost의 세부 사항을 알아봅니다. 자세한 사례 연구를 이용하여 사이킷런 API와 원본 파이썬 API 방식으로 XGBoost 분류 모델과 회귀 모델을 만들고 튜닝하는 방법을 연습합니다. 또한, XGBoost 하이퍼파라미터를 활용하여 성능 개선, 누락된 값 수정 및 불균형 데이터 세트 적용, 그리고 다른 기본 학습기를 튜닝합니다. 마지막으로 상관관계가 낮은 앙상블과 스태킹 모델을 만들어보고, 모델 배포를 위해 희소 행렬과 사용자 정의 변환기, 파이프라인과 같은 고급 XGBoost 기술을 적용합니다. 주요 내용그레이디언트 부스팅 모델 구축정확하고 빠른 XGBoost 회귀 및 분류 모델 개발XGBoost 하이퍼파라미터 미세 조정 측면에서 분산 및 편향 분석상관관계가 없는 앙상블을 구축하고 XGBoost 모델을 스태킹하여 정확성 향상다트, 선형 모델 및 XGBoost 랜덤 포레스트와 같은 기본 학습기 적용사용자 정의 변환기와 파이프라인을 사용한 XGBoost 모델 배포누락된 값 자동 수정 및 불균형 데이터 조정
- Table of Contents:
꿈 많은 사람의 이야기
- Article author: lsjsj92.tistory.com
- Reviews from users: 29306 Ratings
- Top rated: 3.8
- Lowest rated: 1
- Summary of article content: Articles about 꿈 많은 사람의 이야기 이 앙상블에는 배깅(bagging), 부스팅(boosting) 등의 종류가 나뉘어져 있습니다. … 과정으로 데이터를 랜덤으로 추출한 뒤 모델을 훈련시켰습니다. …
- Most searched keywords: Whether you are looking for 꿈 많은 사람의 이야기 이 앙상블에는 배깅(bagging), 부스팅(boosting) 등의 종류가 나뉘어져 있습니다. … 과정으로 데이터를 랜덤으로 추출한 뒤 모델을 훈련시켰습니다. 머신러닝에서는 앙상블(ensemble)을 정말 많이 사용합니다. 그 효과가 매우매우 강력하기 때문인데요. 이 앙상블에는 배깅(bagging), 부스팅(boosting) 등의 종류가 나뉘어져 있습니다. 지난 포스팅 때는 ensemble..나의 IT 공부 히스토리와 지식 공유 창고
- Table of Contents:
꿈 많은 사람의 이야기
머신러닝 앙상블 부스팅이란 – ensemble boosting 본문
티스토리툴바

데이터 과학을 위한 통계(2판): 데이터 분석에서 머신러닝까지 파이썬과 R로 살펴 … – 피터 브루스, 앤드루 브루스, 피터 게데크 – Google Sách
- Article author: books.google.com.vn
- Reviews from users: 3447 Ratings
- Top rated: 4.4
- Lowest rated: 1
- Summary of article content: Articles about 데이터 과학을 위한 통계(2판): 데이터 분석에서 머신러닝까지 파이썬과 R로 살펴 … – 피터 브루스, 앤드루 브루스, 피터 게데크 – Google Sách Updating …
- Most searched keywords: Whether you are looking for 데이터 과학을 위한 통계(2판): 데이터 분석에서 머신러닝까지 파이썬과 R로 살펴 … – 피터 브루스, 앤드루 브루스, 피터 게데크 – Google Sách Updating 파이썬과 R로 필요한 만큼만 배우는 실용주의 통계학 통계 기법은 데이터 과학의 핵심이지만, 데이터 과학자가 고전 통계를 낱낱이 알아야 하는 것은 아니다. 이 책은 데이터 과학의 관점에서 통계 핵심 개념과 기법을 필요한 것만 골라 소개한다. 50가지 개념을 차근차근 정리하고 코드를 실행해보면, 필수 통계 지식을 빠르게 흡수할 수 있다. 2판에는 기존 R 코드와 호응하는 파이썬 코드를 새롭게 추가했다. 이 책으로 필요한 이론을 적재적소에 잘 활용하는 실력 있는 데이터 과학자로 거듭나길 바란다. 주요 내용 데이터 과학의 초석인 탐색적 데이터 분석 시작하기임의표본추출로 편향을 줄이고 고품질 데이터셋을 얻는 방법실험설계 원칙을 적용해 타당한 결론을 도출하고 명확한 답을 찾는 방법회귀분석으로 결과를 추정하고 이상을 탐지하는 방법범주를 예측하고 찾아내는 주요 분류 기법데이터로 학습하는 통계적 머신러닝 기법레이블 없는 데이터에서 의미를 추출하는 비지도 학습 기법 추천사다른 통계 교과서나 머신러닝 매뉴얼과는 차별되는 책이다. 통계 용어와 오늘날 데이터 마이닝 용어를 연결해 설명한다는 점에서 훨씬 낫다. 설명은 간명하고 예제도 많다. 데이터 과학 입문자와 숙련자 모두에게 권할 만한 레퍼런스다._갈리트 시뮤엘리, 『비즈니스 애널리틱스를 위한 데이터마이닝』 주 저자데이터 분석에서 머신러닝까지 50가지 핵심 개념파이썬과 R 코드를 실행해보며, 필요한 만큼만 배운다! 많은 데이터 과학자가 통계 개념을 이해하지 못해 한계에 부딪힌다. 문제가 조금만 복잡해도 어디서부터 어떻게 해결해야 할지 몰라 당황하거나, 출력한 결과를 이해하지 못해 난감해하기 일쑤다. 이 책은 통계 지식에 목마른 현업 데이터 과학자와 인공지능 개발자를 위해 쓰였다. 목표는 다음 두 가지다. 첫째, 데이터 과학과 관련된 통계의 핵심 개념을 소화하기 쉽고 따라 하기 쉽게 소개한다.둘째, 데이터 과학의 관점에서 어떤 개념이 정말 중요하고 유용한지, 어떤 개념이 덜 중요한지 구분해 알게 한다. EDA, 표본분포, 유의성 검정, 회귀분석, 분류, 통계적 머신러닝, 비지도 학습 등 오늘날 데이터 분석과 머신러닝 분야에서 널리 사용하는 주제로 구성했고, 데이터 과학자가 꼭 알아야 하는 개념을 50여 가지만 ‘콕’ 집어 정리했다. 자유도, p 값, 상관계수 등 고전 통계에서 중요하게 생각하는 개념 중, 빅데이터를 다루는 데이터 과학자가 세부 사항까지 자세히 알 필요가 없는 것은 그에 맞게 안내한다. 주요 절마다 ‘용어 정리’와 ‘주요 개념’을 정리해 학습 편의를 높이고, 같은 용어라도 통계학, 데이터 과학, 컴퓨터 과학에서 저마다 다르게 쓰는 경우에는 그 차이점을 정리했다. 2판의 가장 큰 특징은 새로 제공하는 파이썬 코드다. 파이썬 코드를 싣기 위해 과학 계산과 데이터 과학 분야에서 30년 이상의 경력을 갖춘 저자가 새로 투입됐다. 파이썬이나 R, 둘 중 하나만 다룰 줄 알아도 책의 내용을 이해하고 코드를 실행해볼 수 있다. 모두 다룰 줄 안다면 두 언어 간의 구현 차이를 비교하는 재미가 쏠쏠할 것이다. 일반인 대상의 통계책은 시시하고 전공 수준의 통계학 교과서는 어려워 엄두가 안 난다면, 이 책을 징검다리 삼아 통계 지식과 통계적 사고력을 키워보길 바란다. 누구든 이 책을 끝까지 잘 마치면, 필요한 이론을 적재적소에 잘 활용하는 실력 있는 데이터 과학자로 거듭날 수 있다.
- Table of Contents:
부스팅 방법 — 데이터 사이언스 스쿨
- Article author: datascienceschool.net
- Reviews from users: 23291 Ratings
- Top rated: 3.1
- Lowest rated: 1
- Summary of article content: Articles about 부스팅 방법 — 데이터 사이언스 스쿨 에이다부스트는 위원회에 넣을 개별 모형 km을 선별하는 방법으로는 학습 데이터 집합의 i번째 데이터에 가중치 wi를 주고 분류 모형이 틀리게 예측한 데이터의 가중치를 … …
- Most searched keywords: Whether you are looking for 부스팅 방법 — 데이터 사이언스 스쿨 에이다부스트는 위원회에 넣을 개별 모형 km을 선별하는 방법으로는 학습 데이터 집합의 i번째 데이터에 가중치 wi를 주고 분류 모형이 틀리게 예측한 데이터의 가중치를 …
- Table of Contents:
에이다부스트¶
그레디언트 부스트¶
[머신러닝] Boosting Algorithm
- Article author: hyunlee103.tistory.com
- Reviews from users: 24524 Ratings
- Top rated: 4.4
- Lowest rated: 1
- Summary of article content: Articles about [머신러닝] Boosting Algorithm 부스팅 계열 모델은 AdaBoost, Gradient Boost(GBM), XGBoost, LightGBM, CatBoost 등이 있다. 순서대로 정리해보자. AdaBoost. 출처 : https://www. …
- Most searched keywords: Whether you are looking for [머신러닝] Boosting Algorithm 부스팅 계열 모델은 AdaBoost, Gradient Boost(GBM), XGBoost, LightGBM, CatBoost 등이 있다. 순서대로 정리해보자. AdaBoost. 출처 : https://www. 처음 머신러닝을 공부할 때, 가장 어려웠던 부스팅 계열 알고리즘, 보아즈에서 발표를 하게 되면서 다시 한번 내용을 정리해두려고 한다. 학부생의 철없는 질문을 받아주신 건국대학교 권성훈 교수님과 이재병 연..
- Table of Contents:
INDEX
태그
‘ML & DL’ 관련글
티스토리툴바
![[머신러닝] Boosting Algorithm](https://t1.daumcdn.net/tistory_admin/static/images/openGraph/opengraph.png)
See more articles in the same category here: 607+ tips for you.
[ML/DL] 앙상블 학습 (Ensemble Learning): 3.Boosting(부스팅)이란?
반응형
Boosting(부스팅)이란?
여러 개의 분류기가 순차적으로 학습을 수행한다. 이때 이전 분류기가 예측이 틀린 데이터에 대해 올바르게 예측할 수 있도록 가중치를 부여하면서 학습과 예측을 진행한다.
이런 방식으로 앞 훈련에서 틀렸던 부분을 가중치를 주면서 모델 자체를 발전해나간다.
이러한 부스팅은 약검출기들을 여러 개 모아 강 검출기를 생성하는 방법이다.
이러한 방법으로 strong classifier를 생성하게 된다.
지금 캐글에서 가장 많이 인기있는 앙상블 모델 중 하나이다.
Boosting의 종류
XG boosting – 경사 하강법을 통한 부스팅 방식
Gradient Boosting – leaf 를 통한 부스팅 방식
AdaBoost – stump를 통한 부스팅 방식
lightGBM – Gradient Boosting 기반의 더 빠른 부스팅 모델
histgradientboosting – 히스토 그램 기반 부스팅
부스팅 구현(AdaBoostClassifier)
여기서는 간단한 Adaboosclassifier를 구현하겠다.
from sklearn.ensemble import AdaBoostClassifier
ada_model = AdaBoostClassifier() ada_model.fit(X_train, y_train) y_pred = ada_model.predict(X_test)
print(‘예측 정확도 : ‘ , accuracy_score(y_test , y_pred))
반응형
11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)
앙상블(Ensemble)
앙상블은 조화 또는 통일을 의미합니다.
어떤 데이터의 값을 예측한다고 할 때, 하나의 모델을 활용합니다. 하지만 여러 개의 모델을 조화롭게 학습시켜 그 모델들의 예측 결과들을 이용한다면 더 정확한 예측값을 구할 수 있을 겁니다.
앙상블 학습은 여러 개의 결정 트리(Decision Tree)를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝 기법입니다. 앙상블 학습의 핵심은 여러 개의 약 분류기 (Weak Classifier)를 결합하여 강 분류기(Strong Classifier)를 만드는 것입니다. 그리하여 모델의 정확성이 향상됩니다.
앙상블 학습법에는 두 가지가 있습니다. 배깅(Bagging)과 부스팅(Boosting)입니다. 이를 이해하기 위해서는 부트스트랩(Bootstrap)과 결정 트리(Deicison Tree)에 대한 개념이 선행되어야 합니다. 부트스트랩과 결정 트리에 대해 잘 모르신다면 (DATA – 12. 부트스트랩(Bootstrap))과 (머신러닝 – 4. 결정 트리(Decision Tree))를 참고하시기 바랍니다.
배깅(Bagging)
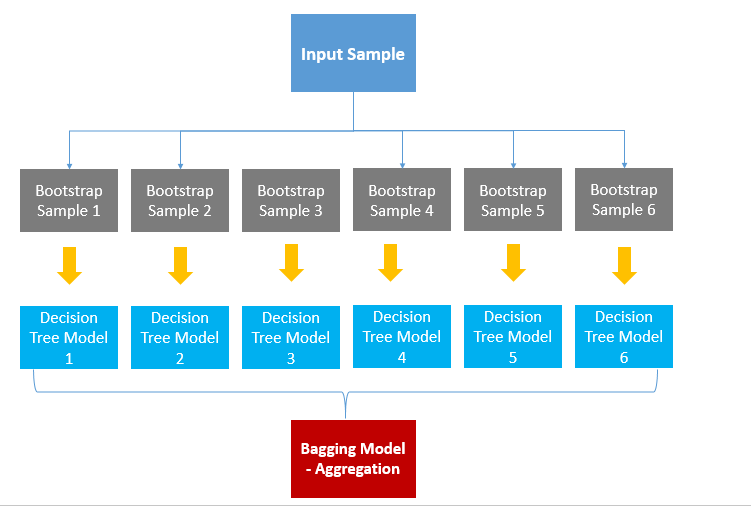
Bagging은 Bootstrap Aggregation의 약자입니다. 배깅은 샘플을 여러 번 뽑아(Bootstrap) 각 모델을 학습시켜 결과물을 집계(Aggregration)하는 방법입니다. 아래 그림을 보겠습니다.
출처: swallow.github.io
우선, 데이터로부터 부트스트랩을 합니다. (복원 랜덤 샘플링) 부트스트랩한 데이터로 모델을 학습시킵니다. 그리고 학습된 모델의 결과를 집계하여 최종 결과 값을 구합니다.
Categorical Data는 투표 방식(Votinig)으로 결과를 집계하며, Continuous Data는 평균으로 집계합니다.
Categorical Data일 때, 투표 방식으로 한다는 것은 전체 모델에서 예측한 값 중 가장 많은 값을 최종 예측값으로 선정한다는 것입니다. 6개의 결정 트리 모델이 있다고 합시다. 4개는 A로 예측했고, 2개는 B로 예측했다면 투표에 의해 4개의 모델이 선택한 A를 최종 결과로 예측한다는 것입니다.
평균으로 집계한다는 것은 말 그대로 각각의 결정 트리 모델이 예측한 값에 평균을 취해 최종 Bagging Model의 예측값을 결정한다는 것입니다.
배깅은 간단하면서도 파워풀한 방법입니다. 배깅 기법을 활용한 모델이 바로 랜덤 포레스트입니다.
부스팅(Boosting)
부스팅은 가중치를 활용하여 약 분류기를 강 분류기로 만드는 방법입니다. 배깅은 Deicison Tree1과 Decision Tree2가 서로 독립적으로 결과를 예측합니다. 여러 개의 독립적인 결정 트리가 각각 값을 예측한 뒤, 그 결과 값을 집계해 최종 결과 값을 예측하는 방식입니다. 하지만 부스팅은 모델 간 팀워크가 이루어집니다. 처음 모델이 예측을 하면 그 예측 결과에 따라 데이터에 가중치가 부여되고, 부여된 가중치가 다음 모델에 영향을 줍니다. 잘못 분류된 데이터에 집중하여 새로운 분류 규칙을 만드는 단계를 반복합니다. 아래 그림을 통해 설명해보겠습니다.
출처: Medium (Boosting and Bagging explained with examples)
+와 -로 구성된 데이터셋을 분류하는 문제입니다.
D1에서는 2/5 지점을 횡단하는 구분선으로 데이터를 나누어주었습니다. 하지만 위쪽의 +는 잘못 분류가 되었고, 아래쪽의 두 -도 잘못 분류되었습니다. 잘못 분류가 된 데이터는 가중치를 높여주고, 잘 분류된 데이터는 가중치를 낮추어 줍니다.
D2를 보면 D1에서 잘 분류된 데이터는 크기가 작아졌고(가중치가 낮아졌고) 잘못 분류된 데이터는 크기가 커졌습니다.(가중치가 커졌습니다.) 분류가 잘못된 데이터에 가중치를 부여해주는 이유는 다음 모델에서 더 집중해 분류하기 위함입니다. D2에서는 오른쪽 세 개의 -가 잘못 분류되었습니다.
따라서 D3에서는 세 개의 -의 가중치가 커졌습니다. 맨 처음 모델에서 가중치를 부여한 +와 -는 D2에서는 잘 분류가 되었기 때문에 D3에서는 가중치가 다시 작아졌습니다.
D1, D2, D3의 Classifier를 합쳐 최종 Classifier를 구할 수 있습니다. 최종 Classfier는 +와 -를 정확하게 구분해줍니다.
배깅과 부스팅 차이
출처: swallow.github.io
위 그림에서 나타내는 바와 같이 배깅은 병렬로 학습하는 반면, 부스팅은 순차적으로 학습합니다. 한번 학습이 끝난 후 결과에 따라 가중치를 부여합니다. 그렇게 부여된 가중치가 다음 모델의 결과 예측에 영향을 줍니다.
오답에 대해서는 높은 가중치를 부여하고, 정답에 대해서는 낮은 가중치를 부여합니다. 따라서 오답을 정답으로 맞추기 위해 오답에 더 집중할 수 있게 되는 것입니다.
부스팅은 배깅에 비해 error가 적습니다. 즉, 성능이 좋습니다. 하지만 속도가 느리고 오버 피팅이 될 가능성이 있습니다. 그렇다면 실제 사용할 때는 배깅과 부스팅 중 어떤 것을 선택해야 할까요? 상황에 따라 다르다고 할 수 있습니다. 개별 결정 트리의 낮은 성능이 문제라면 부스팅이 적합하고, 오버 피팅이 문제라면 배깅이 적합합니다.
References
Reference1: Medium (Ensemble Learning – Bagging and Boosting)
Reference2: Bagging과 Boosting 그리고 Stacking
앙상블 학습 – 부스팅(boosting) 알고리즘 개념 잡기
728×90
해당 글은 핸즈온 머신러닝 2판을 기준으로 작성되었습니다.
앙상블 학습(ensemble learning) 은 일련의 예측기(분류 or 회귀 모델)로부터 예측을 수집하여 하나의 모델을 사용했을 때보다 더 좋은 예측을 얻을 수 있습니다. 쉽게 말해 대중의 지혜라고 표현하는데, 속담으로는 “백지장도 맞들면 낫다”가 적당하려나요? ( 좀 아닌 것 같지만ㅎㅎ )
부스팅은 앙상블 학습의 한 방법으로 이외에 배깅, 스택킹 등의 방법이 있습니다. 여기서는 부스팅에 대한 이야기를 해보겠습니다.
부스팅은 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법을 말합니다. 부스팅 방법의 아이디어는 앞의 모델을 보완해나가면서 일련의 예측기를 학습시키는 것입니다. 부스팅 방법에는 여러 가지가 있지만 가장 인기 있는 것은 그레이디언트 부스팅(gradient boosting) 과 에이다부스트(AdaBoost) 입니다. 참고로 에이다부스트는 adaptive boosting의 줄임말입니다.
먼저, 그레이디언트 부스팅에 대해 이야기해보겠습니다. 간단히 말하면, 이전 예측기가 만든 잔여 오차(residual error)에 새로운 예측기를 학습시키는 것입니다. 따라서 모델 학습에서 항상 문제가 되는 variance-bias tradeoff에서 bias를 증가시키지 않고, variance를 감소시킬 수 있는 좋은 방법이기도 합니다.
의사결정나무를 기반 예측기로 사용하는 간단한 회귀 문제를 살펴보겠습니다. 이를 그레이디언트 부스티드 회귀 트리(gradient boosted regression tree, 이하 GBRT) 라고도 부릅니다.
from sklearn.tree import DecisionTreeRegressor tree_reg1 = DecisionTreeRegressor(max_depth=2) tree_reg.fit(X, y)
y2 = y – tree_reg1.predict(X) tree_reg2 = DecisionTreeRegressor(max_depth=2) tree_reg2.fit(X, y2)
y3 = y2 – tree_reg2.predict(X) tree_reg3 = DecisionTreeRegressor(max_depth=2) tree_reg3.fit(X, y3)
3개의 트리를 포함하는 앙상블 모델이 생겼고, 새로운 샘플에 대해 예측하려면 모든 트리의 예측을 더하면 됩니다.
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
위의 코드를 수식으로 표현하면 이와 같습니다. $h(x)$을 예측기의 함수 식이라고 생각합시다. 여기에 우리가 가진 데이터를 입력하면 예측값 y_val이 나오고 그 차이는 $e$라고 표현합니다.
$y = h_1(x_1) + e_1$
$e_1 = h_2(x_2) + e_2$
$e_2 = h_3(x_3) + e_3$
$y = h_1(x_1) + h_2(x_2) + h_3(x_3) + e_3$
핵심은 실제 값과 처음에 예측한 값의 차이인 $e_1$을 새로운 y로 보고 이를 예측한다는 것입니다. 즉 잔차에 대한 함수를 계속해서 생성하는 것이고, 이를 반복하다 보면 마지막 잔차 $e_n$는 0에 가까워질 것입니다.
<출처: hands-on machine learning 2>
잔차에 대한 함수를 생성하고 실제값과 차이를 최소화하는 과정에서 사용되는 개념이 gradient 입니다. 먼저 아래 Loss function 수식은 익숙하실 것입니다. 실제값과 예측값의 차이를 최소화하는 것이죠.
$minL =$ $1\over2 $ $\sum_{i=1}^n (y_i – f(x_i))^2$
# 위 loss function을 미분한 값
$\delta L\over \delta f(x_i)$ $=f(x_i) – y_i$
$y-f(x_i) =$ $-$$\delta L \over \delta f(x_i)$
미분한 값을 음수로 취하면 실제값에서 예측한 값을 빼는 gradient인 것을 알 수 있습니다.
사이킷런을 이용하면 GBRT 앙상블을 간단하게 훈련시킬 수 있습니다. 이때 learning_rate 매개변수는 각 트리의 기여 정도를 조절합니다. 즉 0.1처럼 낮게 설정하면 앙상블을 훈련 세트에 학습시키기 위해 많은 트리가 필요하지만, 일반적으로 예측의 성능은 좋아집니다(단, 오버피팅의 위험도 있습니다). 쉽게 말해 축소(shrinkage) 라고 부르는 규제 방법입니다.
from sklearn.ensemble import GradientBoostingRegressor gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0) gbrt.fit(X, y)
최적의 트리 수를 찾기 위해선 어떻게 해야 할까요? 일단 조기 종료 기법(early stopping method) 을 사용할 수 있습니다. staged_predict() 메서드를 이용하여 각 단계(트리 1개, 2개 등)에서 앙상블에 의해 만들어진 예측기를 순회하는 반복자를 반환합니다.
import numpy as np from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error X_train, X_val, y_train, y_val = train_test_split(X, y) gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120) # 초기엔 120개 트리로 훈련 gbrt.fit(X_train, y_train) errors = [mean_squared_error(y_val, y_pred) for y_pred in gbrt.staged_predict(X_val)] bst_n_estimators = np.argmin(errors) + 1 # 에러가 최소일 때의 트리 수 저장 gbrt_best = GradientBoostingRegressor(max_depth=2, n_estimators=bst_n_estimators) gbrt_best.fit(X_train, y_train)
사이킷런의 GradientBoostingRegressor는 각 트리가 훈련할 때 사용할 훈련 샘플의 비율을 지정할 수 있는 subsample 매개변수도 지원합니다. 예를 들어, subsample=0.25라고 하면 각 트리는 무작위로 선택된 25%의 훈련 샘플로 학습되는 것이죠. 이럴 경우, 편향이 높아지는 대신 분산이 낮아지고, 훈련 속도가 상당히 빨라집니다. 이런 기법을 확 률적 그레이디언트 부스팅(stochastic gradient boosting) 이라고 합니다.
최적화된 그레이디언트 부스팅 구현으로는 XGBoost 파이썬 라이브러리가 유명합니다. 분산환경에서도 실행할 수 있도록 하여 빠른 속도, 확장성, 이식성의 장점을 가지고 있습니다.
import xgboost xgb_reg = xgboost.XGBRegressor() xgb_reg.fit(X_train, y_train) # 자동 조기 종료 기능 존재 # ex) eval_set=[(X_val, y_val)], early_stopping_rounds=2 y_pred = xgb_reg.predict(X_val)
그레이디언트 부스팅의 동작 과정을 차근차근 설명한 동영상이 있어 첨부하니 참고하시기 바랍니다.
728×90
So you have finished reading the 부스팅 모델 topic article, if you find this article useful, please share it. Thank you very much. See more: 부스팅 뜻, 부스팅 알고리즘, Boosting 기법, Boosting 장점, 앙상블 모델 종류, 부스팅 단점, 앙상블 모델 구현, Bagging, Boosting