
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me cnn lenet on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://chewathai27.com/to team, along with other related topics such as: cnn lenet LeNet, AlexNet, LeNet-5, DenseNet, LeNet architecture, GoogLeNet, Mạng GoogLeNet, Mạng AlexNet
Quá trình phát triển của CNN từ LeNet đến DenseNet.
- Article author: dlapplications.github.io
- Reviews from users: 24894
 Ratings
Ratings - Top rated: 3.9
- Lowest rated: 1
- Summary of article content: Articles about Quá trình phát triển của CNN từ LeNet đến DenseNet. LeNet là một trong những mạng CNN lâu đời nổi tiếng nhất được Yann LeCUn phát triển vào những năm 1998s. Cấu trúc của LeNet gồm 2 layer … …
- Most searched keywords: Whether you are looking for Quá trình phát triển của CNN từ LeNet đến DenseNet. LeNet là một trong những mạng CNN lâu đời nổi tiếng nhất được Yann LeCUn phát triển vào những năm 1998s. Cấu trúc của LeNet gồm 2 layer … từ architect đơn giản đến phức tạp
- Table of Contents:
LeNet – Convolutional Neural Network in Python – PyImageSearch
- Article author: pyimagesearch.com
- Reviews from users: 49499 Ratings
- Top rated: 4.1
- Lowest rated: 1
- Summary of article content: Articles about LeNet – Convolutional Neural Network in Python – PyImageSearch In today’s blog post, we are going to implement our first Convolutional Neural Network (CNN) — LeNet — using Python and the Keras deep … …
- Most searched keywords: Whether you are looking for LeNet – Convolutional Neural Network in Python – PyImageSearch In today’s blog post, we are going to implement our first Convolutional Neural Network (CNN) — LeNet — using Python and the Keras deep … In this tutorial, I demonstrate how to implement LeNet, a Convolutional Neural Network architecture for image classification using Python + Keras.
- Table of Contents:
LeNet – Convolutional Neural Network in Python
Summary
Reader Interactions
Primary Sidebar
Save your Keras and TensorFlow model to disk
Building a Pokedex in Python Scraping the Pokemon Sprites (Step 2 of 6)
Why I started a computer vision and deep learning conference
Footer
LeNet – Convolutional Neural Network in Python – PyImageSearch
- Article author: towardsdatascience.com
- Reviews from users: 8005 Ratings
- Top rated: 4.7
- Lowest rated: 1
- Summary of article content: Articles about LeNet – Convolutional Neural Network in Python – PyImageSearch LeNet-5 CNN architecture is made up of 7 layers. The layer composition consists of 3 convolutional layers, 2 subsampling layers and 2 fully … …
- Most searched keywords: Whether you are looking for LeNet – Convolutional Neural Network in Python – PyImageSearch LeNet-5 CNN architecture is made up of 7 layers. The layer composition consists of 3 convolutional layers, 2 subsampling layers and 2 fully … In this tutorial, I demonstrate how to implement LeNet, a Convolutional Neural Network architecture for image classification using Python + Keras.
- Table of Contents:
LeNet – Convolutional Neural Network in Python
Summary
Reader Interactions
Primary Sidebar
Save your Keras and TensorFlow model to disk
Building a Pokedex in Python Scraping the Pokemon Sprites (Step 2 of 6)
Why I started a computer vision and deep learning conference
Footer
7.6. Convolutional Neural Networks (LeNet) — Dive into Deep Learning 1.0.0-alpha0 documentation
- Article author: d2l.ai
- Reviews from users: 40044 Ratings
- Top rated: 4.1
- Lowest rated: 1
- Summary of article content: Articles about 7.6. Convolutional Neural Networks (LeNet) — Dive into Deep Learning 1.0.0-alpha0 documentation In this section, we will introduce LeNet, among the first published CNNs to capture we attention for its performance on computer vision tasks. The model was … …
- Most searched keywords: Whether you are looking for 7.6. Convolutional Neural Networks (LeNet) — Dive into Deep Learning 1.0.0-alpha0 documentation In this section, we will introduce LeNet, among the first published CNNs to capture we attention for its performance on computer vision tasks. The model was …
- Table of Contents:
761 LeNet¶
762 Training¶
763 Summary¶
764 Exercises¶
LeNet – Wikipedia
- Article author: en.wikipedia.org
- Reviews from users: 49060 Ratings
- Top rated: 3.7
- Lowest rated: 1
- Summary of article content: Articles about LeNet – Wikipedia LeNet is a convolutional neural network structure proposed by Yann LeCun et al. in 1989. In general, LeNet refers to LeNet-5 and is a simple convolutional … …
- Most searched keywords: Whether you are looking for LeNet – Wikipedia LeNet is a convolutional neural network structure proposed by Yann LeCun et al. in 1989. In general, LeNet refers to LeNet-5 and is a simple convolutional …
- Table of Contents:
Contents
Development history[edit]
Structure[edit]
Features[edit]
Application[edit]
Development analysis[edit]
References[edit]
Navigation menu
LeNet – Wikipedia
- Article author: medium.com
- Reviews from users: 17045 Ratings
- Top rated: 3.3
- Lowest rated: 1
- Summary of article content: Articles about LeNet – Wikipedia The network used a CNN inspired by LeNet but implemented a novel element which is dubbed an inception module. It used batch normalization, image distortions and … …
- Most searched keywords: Whether you are looking for LeNet – Wikipedia The network used a CNN inspired by LeNet but implemented a novel element which is dubbed an inception module. It used batch normalization, image distortions and …
- Table of Contents:
Contents
Development history[edit]
Structure[edit]
Features[edit]
Application[edit]
Development analysis[edit]
References[edit]
Navigation menu
Lenet-5 | Lenet-5 Architecture | Introduction to Lenet-5
- Article author: www.analyticsvidhya.com
- Reviews from users: 35112 Ratings
- Top rated: 3.9
- Lowest rated: 1
- Summary of article content: Articles about Lenet-5 | Lenet-5 Architecture | Introduction to Lenet-5 Let’s understand the architecture of Lenet-5. The network has 5 layers with learnable parameters and hence named Lenet-5. It has three sets of … …
- Most searched keywords: Whether you are looking for Lenet-5 | Lenet-5 Architecture | Introduction to Lenet-5 Let’s understand the architecture of Lenet-5. The network has 5 layers with learnable parameters and hence named Lenet-5. It has three sets of … Lenet-5 is one of the earliest pre-trained models proposed by Yann LeCun and others in the year 1998. Learn about Lenet 5 architecture here
- Table of Contents:
Objective
Introduction
What is Lenet5
The Architecture of the Model
Architecture Details
End Notes
Top Resources
×

6.6. Mạng NÆ¡-ron TÃch cháºp (LeNet) — Äắm mình và o Há»c Sâu 0.14.4 documentation
- Article author: d2l.aivivn.com
- Reviews from users: 13169 Ratings
- Top rated: 3.1
- Lowest rated: 1
- Summary of article content: Articles about 6.6. Mạng NÆ¡-ron TÃch cháºp (LeNet) — Äắm mình và o Há»c Sâu 0.14.4 documentation Mỗi ảnh trong Fashion-MNIST là một ma trận hai chiều có kích thước 28×28. Để tương thích với đầu vào dạng vector một chiều với độ dài cố định của các perceptron … …
- Most searched keywords: Whether you are looking for 6.6. Mạng NÆ¡-ron TÃch cháºp (LeNet) — Äắm mình và o Há»c Sâu 0.14.4 documentation Mỗi ảnh trong Fashion-MNIST là một ma trận hai chiều có kích thước 28×28. Để tương thích với đầu vào dạng vector một chiều với độ dài cố định của các perceptron …
- Table of Contents:
661 LeNet¶
662 Thu tháºp Dữ liá»u và Huấn luyá»n¶
663 Tóm tắt¶
664 Bà i táºp¶
665 Thảo luáºn¶
666 Những ngÆ°á»i thá»±c hiá»n¶
See more articles in the same category here: https://chewathai27.com/to/blog.
Convolutional Neural Network in Python
In today’s blog post, we are going to implement our first Convolutional Neural Network (CNN) — LeNet — using Python and the Keras deep learning package.
The LeNet architecture was first introduced by LeCun et al. in their 1998 paper, Gradient-Based Learning Applied to Document Recognition. As the name of the paper suggests, the authors’ implementation of LeNet was used primarily for OCR and character recognition in documents.
The LeNet architecture is straightforward and small, (in terms of memory footprint), making it perfect for teaching the basics of CNNs — it can even run on the CPU (if your system does not have a suitable GPU), making it a great “first CNN”.
However, if you do have GPU support and can access your GPU via Keras, you will enjoy extremely fast training times (in the order of 3-10 seconds per epoch, depending on your GPU).
In the remainder of this post, I’ll be demonstrating how to implement the LeNet Convolutional Neural Network architecture using Python and Keras.
From there, I’ll show you how to train LeNet on the MNIST dataset for digit recognition.
To learn how to train your first Convolutional Neural Network, keep reading.
Looking for the source code to this post? Jump Right To The Downloads Section
LeNet – Convolutional Neural Network in Python
This tutorial will be primarily code oriented and meant to help you get your feet wet with Deep Learning and Convolutional Neural Networks. Because of this intention, I am not going to spend a lot of time discussing activation functions, pooling layers, or dense/fully-connected layers — there will be plenty of tutorials on the PyImageSearch blog in the future that will cover each of these layer types/concepts in lots of detail.
Again, this tutorial is meant to be your first end-to-end example where you get to train a real-life CNN (and see it in action). We’ll get to the gory details of activation functions, pooling layers, and fully-connected layers later in this series of posts (although you should already know the basics of how convolution operations work); but in the meantime, simply follow along, enjoy the lesson, and learn how to implement your first Convolutional Neural Network with Python and Keras.
The MNIST dataset
You’ve likely already seen the MNIST dataset before, either here on the PyImageSearch blog, or elsewhere in your studies. In either case, I’ll go ahead and quickly review the dataset to ensure you know exactly what data we’re working with.
The MNIST dataset is arguably the most well-studied, most understood dataset in the computer vision and machine learning literature, making it an excellent “first dataset” to use on your deep learning journey.
Note: As we’ll find out, it’s also quite easy to get > 98% classification accuracy on this dataset with minimal training time, even on the CPU.
The goal of this dataset is to classify the handwritten digits 0-9. We’re given a total of 70,000 images, with (normally) 60,000 images used for training and 10,000 used for evaluation; however, we’re free to split this data as we see fit. Common splits include the standard 60,000/10,000, 75%/25%, and 66.6%/33.3%. I’ll be using 2/3 of the data for training and 1/3 of the data for testing later in the blog post.
Each digit is represented as a 28 x 28 grayscale image (examples from the MNIST dataset can be seen in the figure above). These grayscale pixel intensities are unsigned integers, with the values of the pixels falling in the range [0, 255]. All digits are placed on a black background with a light foreground (i.e., the digit itself) being white and various shades of gray.
It’s worth noting that many libraries (such as scikit-learn) have built-in helper methods to download the MNIST dataset, cache it locally to disk, and then load it. These helper methods normally represent each image as a 784-d vector.
Where does the number 784 come from?
Simple. It’s just the flattened 28 x 28 = 784 image.
To recover our original image from the 784-d vector, we simply reshape the array into a 28 x 28 image.
In the context of this blog post, our goal is to train LeNet such that we maximize accuracy on our testing set.
The LeNet architecture
The LeNet architecture is an excellent “first architecture” for Convolutional Neural Networks (especially when trained on the MNIST dataset, an image dataset for handwritten digit recognition).
LeNet is small and easy to understand — yet large enough to provide interesting results. Furthermore, the combination of LeNet + MNIST is able to run on the CPU, making it easy for beginners to take their first step in Deep Learning and Convolutional Neural Networks.
In many ways, LeNet + MNIST is the “Hello, World” equivalent of Deep Learning for image classification.
The LeNet architecture consists of the following layers:
INPUT => CONV => RELU => POOL => CONV => RELU => POOL => FC => RELU => FC
Instead of explaining the number of convolution filters per layer, the size of the filters themselves, and the number of fully-connected nodes right now, I’m going to save this discussion until our “Implementing LeNet with Python and Keras” section of the blog post where the source code will serve as an aid in the explantation.
In the meantime, let’s took at our project structure — a structure that we are going to reuse many times in future PyImageSearch blog posts.
Note: The original LeNet architecture used TANH activation functions rather than RELU . The reason we use RELU here is because it tends to give much better classification accuracy due to a number of nice, desirable properties (which I’ll discuss in a future blog post). If you run into any other discussions on LeNet, you might see that they use TANH instead — again, just something to keep in mind.
Our CNN project structure
Before we dive into any code, let’s first review our project structure:
|— output |— pyimagesearch | |— __init__.py | |— cnn | | |— __init__.py | | |— networks | | | |— __init__.py | | | |— lenet.py |— lenet_mnist.py
To keep our code organized, we’ll define a package named pyimagesearch . And within the pyimagesearch module, we’ll create a cnn sub-module — this is where we’ll store our Convolutional Neural Network implementations, along with any helper utilities related to CNNs.
Taking a look inside cnn , you’ll see the networks sub-module: this is where the network implementations themselves will be stored. As the name suggests, the lenet.py file will define a class named LeNet , which is our actual LeNet implementation in Python + Keras.
The lenet_mnist.py script will be our driver program used to instantiate the LeNet network architecture, train the model (or load the model, if our network is pre-trained), and then evaluate the network performance on the MNIST dataset.
Finally, the output directory will store our LeNet model after it has been trained, allowing us to classify digits in subsequent calls to lenet_mnist.py without having to re-train the network.
I personally have been using this project structure (or a project structure very similar to it) over the past year. I’ve found it well organized and easy to extend — this will become more evident in future blog posts as we add to this library with more network architectures and helper functions.
Implementing LeNet with Python and Keras
To start, I am going to assume that you already have Keras, scikit-learn, and OpenCV installed on your system (and optionally, have GPU-support enabled). If you do not, please refer to this blog post to help you get your system configured properly.
Otherwise, open up the lenet.py file and insert the following code:
# import the necessary packages from keras.models import Sequential from keras.layers.convolutional import Conv2D from keras.layers.convolutional import MaxPooling2D from keras.layers.core import Activation from keras.layers.core import Flatten from keras.layers.core import Dense from keras import backend as K class LeNet: @staticmethod def build(numChannels, imgRows, imgCols, numClasses, activation=”relu”, weightsPath=None): # initialize the model model = Sequential() inputShape = (imgRows, imgCols, numChannels) # if we are using “channels first”, update the input shape if K.image_data_format() == “channels_first”: inputShape = (numChannels, imgRows, imgCols)
Lines 2-8 handle importing the required functions/classes from the keras library.
The LeNet class is defined on Line 10, followed by the build method on Line 12. Whenever I define a new network architecture, I always place it in its own class (mainly for namespace and organization purposes) — followed by creating a static build function.
The build method, as the name suggests, takes any supplied parameters, which at a bare minimum include:
The width of our input images.
The height of our input images.
The depth (i.e., number of channels) of our input images.
And the number of classes (i.e., unique number of class labels) in our dataset.
I also normally include a weightsPath which can be used to load a pre-trained model. Given these parameters, the build function is responsible for constructing the network architecture.
Speaking of building the LeNet architecture, Line 15 instantiates a Sequential class which we’ll use to construct the network.
Then, we handle whether we’re working with “channels last” or “channels first” tensors on Lines 16-20. Tensorflow’s default is “channels last”.
Now that the model has been initialized, we can start adding layers to it:
# define the first set of CONV => ACTIVATION => POOL layers model.add(Conv2D(20, 5, padding=”same”, input_shape=inputShape)) model.add(Activation(activation)) model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
On Lines 23-26 we create our first set of CONV => RELU => POOL layer sets.
Our CONV layer will learn 20 convolution filters, where each filter is of size 5 x 5. The input dimensions of this value are the same width, height, and depth as our input images — in this case, the MNIST dataset, so we’ll have 28 x 28 inputs with a single channel for depth (grayscale).
We’ll then apply the ReLU activation function followed by 2 x 2 max-pooling in both the x and y direction with a stride of 2 (imagine a 2 x 2 sliding window that “slides” across the activation volume, taking the max operation of each region, while taking a step of 2 pixels in both the horizontal and vertical direction).
Note: This tutorial is primarily code based and is meant to be your first exposure to implementing a Convolutional Neural Network — I’ll be going into lots more detail regarding convolutional layers, activation functions, and max-pooling layers in future blog posts. In the meantime, simply try to follow along with the code.
We are now ready to apply our second set of CONV => RELU => POOL layers:
# define the second set of CONV => ACTIVATION => POOL layers model.add(Conv2D(50, 5, padding=”same”)) model.add(Activation(activation)) model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
This time we’ll be learning 50 convolutional filters rather than the 20 convolutional filters as in the previous layer set.
It’s common to see the number of CONV filters learned increase in deeper layers of the network.
Next, we come to the fully-connected layers (often called “dense” layers) of the LeNet architecture:
# define the first FC => ACTIVATION layers model.add(Flatten()) model.add(Dense(500)) model.add(Activation(activation)) # define the second FC layer model.add(Dense(numClasses)) # lastly, define the soft-max classifier model.add(Activation(“softmax”))
On Line 34 we take the output of the preceding MaxPooling2D layer and flatten it into a single vector, allowing us to apply dense/fully-connected layers. If you have any prior experience with neural networks, then you’ll know that a dense/fully-connected layer is a “standard” type of layer in a network, where every node in the preceding layer connects to every node in the next layer (hence the term, “fully-connected”).
Our fully-connected layer will contain 500 units (Line 35) which we pass through another nonlinear ReLU activation.
Line 39 is very important, although it’s easy to overlook — this line defines another Dense class, but accepts a variable (i.e., not hardcoded) size. This size is the number of class labels represented by the classes variable. In the case of the MNIST dataset, we have 10 classes (one for each of the ten digits we are trying to learn to recognize).
Finally, we apply a softmax classifier (multinomial logistic regression) that will return a list of probabilities, one for each of the 10 class labels (Line 42). The class label with the largest probability will be chosen as the final classification from the network.
Our last code block handles loading a pre-existing weightsPath (if such a file exists) and returning the constructed model to the calling function:
# if a weights path is supplied (inicating that the model was # pre-trained), then load the weights if weightsPath is not None: model.load_weights(weightsPath) # return the constructed network architecture return model
Creating the LeNet driver script
Now that we have implemented the LeNet Convolutional Neural Network architecture using Python + Keras, it’s time to define the lenet_mnist.py driver script which will handle:
Loading the MNIST dataset. Partitioning MNIST into training and testing splits. Loading and compiling the LeNet architecture. Training the network. Optionally saving the serialized network weights to disk so that it can be reused (without having to re-train the network). Displaying visual examples of the network output to demonstrate that our implementaiton is indeed working properly.
Open up your lenet_mnist.py file and insert the following code:
# import the necessary packages from pyimagesearch.cnn.networks.lenet import LeNet from sklearn.model_selection import train_test_split from keras.datasets import mnist from keras.optimizers import SGD from keras.utils import np_utils from keras import backend as K import numpy as np import argparse import cv2 # construct the argument parser and parse the arguments ap = argparse.ArgumentParser() ap.add_argument(“-s”, “–save-model”, type=int, default=-1, help=”(optional) whether or not model should be saved to disk”) ap.add_argument(“-l”, “–load-model”, type=int, default=-1, help=”(optional) whether or not pre-trained model should be loaded”) ap.add_argument(“-w”, “–weights”, type=str, help=”(optional) path to weights file”) args = vars(ap.parse_args())
Lines 2-10 handle importing our required Python packages. Notice how we’re importing our LeNet class from the networks sub-module of cnn and pyimagesearch .
Note: If you’re following along with this blog post and intend on executing the code, please use the “Downloads” section at the bottom of this post. In order to keep this post shorter and concise, I’ve left out the __init__.py updates which might throw off newer Python developers.
From there, Lines 13-20 parse three optional command line arguments, each of which are detailed below:
–save-model : An indicator variable, used to specify whether or not we should save our model to disk after training LeNet.
: An indicator variable, used to specify whether or not we should save our model to disk after training LeNet. –load-model : Another indicator variable, this time specifying whether or not we should load a pre-trained model from disk.
: Another indicator variable, this time specifying whether or not we should load a pre-trained model from disk. –weights : In the case that –save-model is supplied, the –weights-path should point to where we want to save the serialized model. And in the case that –load-model is supplied, the –weights should point to where the pre-existing weights file lives on our system.
We are now ready to load the MNIST dataset and partition it into our training and testing splits:
# grab the MNIST dataset (if this is your first time running this # script, the download may take a minute — the 55MB MNIST dataset # will be downloaded) print(“[INFO] downloading MNIST…”) ((trainData, trainLabels), (testData, testLabels)) = mnist.load_data() # if we are using “channels first” ordering, then reshape the # design matrix such that the matrix is: # num_samples x depth x rows x columns if K.image_data_format() == “channels_first”: trainData = trainData.reshape((trainData.shape[0], 1, 28, 28)) testData = testData.reshape((testData.shape[0], 1, 28, 28)) # otherwise, we are using “channels last” ordering, so the design # matrix shape should be: num_samples x rows x columns x depth else: trainData = trainData.reshape((trainData.shape[0], 28, 28, 1)) testData = testData.reshape((testData.shape[0], 28, 28, 1)) # scale data to the range of [0, 1] trainData = trainData.astype(“float32”) / 255.0 testData = testData.astype(“float32”) / 255.0
Line 26 loads the MNIST dataset from disk. If this is your first time calling the fetch_mldata function with the “MNIST Original” string, then the MNIST dataset will need to be downloaded. The MNIST dataset is a 55MB file, so depending on your internet connection, this download may take anywhere from a couple seconds to a few minutes.
Lines 31-39 handle reshaping data for either “channels first” or “channels last” implementation. For example, TensorFlow supports “channels last” ordering.
Finally, Lines 42-43 perform a training and testing split, using 2/3 of the data for training and the remaining 1/3 for testing. We also reduce our images from the range [0, 255] to [0, 1.0], a common scaling technique.
The next step is to process our labels so they can be used with the categorical cross-entropy loss function:
# transform the training and testing labels into vectors in the # range [0, classes] — this generates a vector for each label, # where the index of the label is set to `1` and all other entries # to `0`; in the case of MNIST, there are 10 class labels trainLabels = np_utils.to_categorical(trainLabels, 10) testLabels = np_utils.to_categorical(testLabels, 10) # initialize the optimizer and model print(“[INFO] compiling model…”) opt = SGD(lr=0.01) model = LeNet.build(numChannels=1, imgRows=28, imgCols=28, numClasses=10, weightsPath=args[“weights”] if args[“load_model”] > 0 else None) model.compile(loss=”categorical_crossentropy”, optimizer=opt, metrics=[“accuracy”])
Lines 49 and 50 handle processing our training and testing labels (i.e., the “ground-truth” labels of each image in the MNIST dataset).
Since we are using the categorical cross-entropy loss function, we need to apply the to_categorical function which converts our labels from integers to a vector, where each vector ranges from [0, classes] . This function generates a vector for each class label, where the index of the correct label is set to 1 and all other entries are set to 0.
In the case of the MNIST dataset, we have 10 lass labels, therefore each label is now represented as a 10-d vector. As an example, consider the training label “3”. After applying the to_categorical function, our vector would now look like:
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]Notice how all entries in the vector are zero except for the third index which is now set to one.
We’ll be training our network using Stochastic Gradient Descent (SGD) with a learning rate of 0.01 (Line 54). Categorical cross-entropy will be used as our loss function, a fairly standard choice when working with datasets that have more than two class labels. Our model is then compiled and loaded into memory on Lines 55-59.
We are now ready to build our LeNet architecture, optionally load any pre-trained weights from disk, and then train our network:
# only train and evaluate the model if we *are not* loading a # pre-existing model if args[“load_model”] < 0: print("[INFO] training...") model.fit(trainData, trainLabels, batch_size=128, epochs=20, verbose=1) # show the accuracy on the testing set print("[INFO] evaluating...") (loss, accuracy) = model.evaluate(testData, testLabels, batch_size=128, verbose=1) print("[INFO] accuracy: {:.2f}%".format(accuracy * 100)) In the case that --load-model is not supplied, we need to train our network (Line 63). Training our network is accomplished by making a call to the .fit method of the instantiated model (Lines 65 and 66). We’ll allow our network to train for 20 epochs (indicating that our network will “see” each of the training examples a total of 20 times to learn distinguishing filters for each digit class). We then evaluate our network on the testing data (Lines 70-72) and display the results to our terminal. Next, we make a check to see if we should serialize the network weights to file, allowing us to run the lenet_mnist.py script subsequent times without having to re-train the network from scratch: # check to see if the model should be saved to file if args["save_model"] > 0: print(“[INFO] dumping weights to file…”) model.save_weights(args[“weights”], overwrite=True)
Our last code block handles randomly selecting a few digits from our testing set and then passing them through our trained LeNet network for classification:
# randomly select a few testing digits for i in np.random.choice(np.arange(0, len(testLabels)), size=(10,)): # classify the digit probs = model.predict(testData[np.newaxis, i]) prediction = probs.argmax(axis=1) # extract the image from the testData if using “channels_first” # ordering if K.image_data_format() == “channels_first”: image = (testData[i][0] * 255).astype(“uint8”) # otherwise we are using “channels_last” ordering else: image = (testData[i] * 255).astype(“uint8”) # merge the channels into one image image = cv2.merge([image] * 3) # resize the image from a 28 x 28 image to a 96 x 96 image so we # can better see it image = cv2.resize(image, (96, 96), interpolation=cv2.INTER_LINEAR) # show the image and prediction cv2.putText(image, str(prediction[0]), (5, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 2) print(“[INFO] Predicted: {}, Actual: {}”.format(prediction[0], np.argmax(testLabels[i]))) cv2.imshow(“Digit”, image) cv2.waitKey(0)
For each of the randomly selected digits, we classify the image using our LeNet model (Line 82).
The actual prediction of our network is obtained by finding the index of the class label with the largest probability. Remember, our network will return a set of probabilities via the softmax function, one for each class label — the actual “prediction” of the network is therefore the class label with the largest probability.
Lines 87-103 handle resizing the 28 x 28 image to 96 x 96 pixels so we can better visualize it, followed by drawing the prediction on the image .
Finally, Lines 104-107 display the result to our screen.
Training LeNet with Python and Keras
To train LeNet on the MNIST dataset, make sure you have downloaded the source code using the “Downloads” form found at the bottom of this tutorial. This .zip file contains all the code I have detailed in this tutorial — furthermore, this code is organized in the same project structure that I detailed above, which ensures it will run properly on your system (provided you have your environment configured properly).
After downloading the .zip code archive, you can train LeNet on MNIST by executing the following command:
$ python lenet_mnist.py –save-model 1 –weights output/lenet_weights.hdf5
I’ve included the output from my machine below:
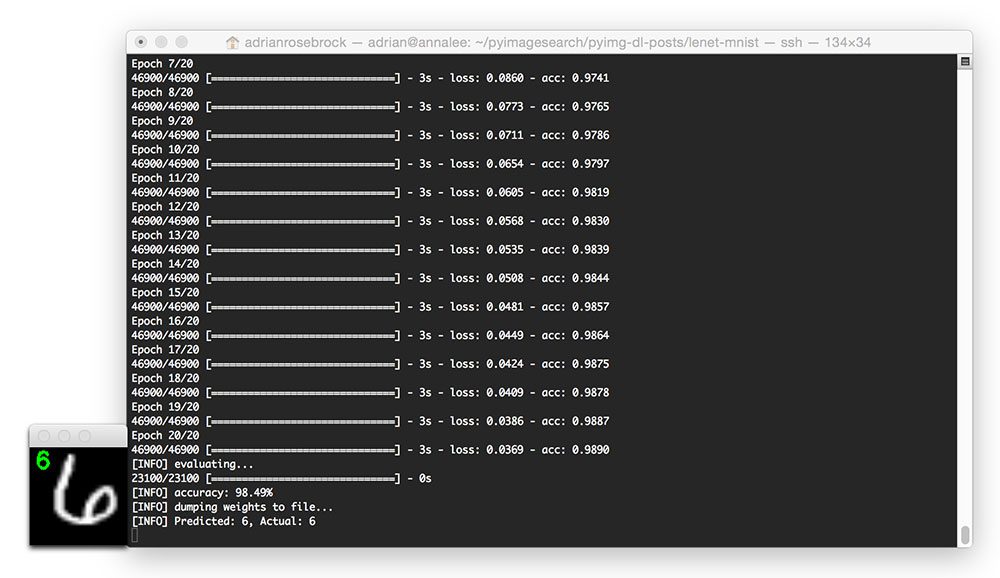
On my Titan X GPU, it takes approximately 3 seconds per epoch, allowing the entire training process to finish in approximately 60 seconds.
After only 20 epochs, LeNet is reaching 98.49% classification accuracy on the MNIST dataset — not bad at all for only 60 seconds of computation time!
Note: If you execute the lenet_mnist.py script on our CPU rather than GPU, expect the per-epoch time to jump to 70-90 seconds. It’s still possible to train LeNet on your CPU, it will just take a little while longer.
Evaluating LeNet with Python and Keras
Below I have included a few example evaluation images from our LeNet + MNIST implementation:
In the above image, we are able to correctly classify the digit as “6”.
And in this image, LeNet correctly recognizes the digit as a “2”:
The image below is a great example of the robust, discriminating nature of convolution filters learned by CNN filters: This “6” is quite contorted, leaving little-to-no gap between the circular region of the digit, but LeNet is still able to correctly classify the digit:
Here is another image, this time classifying a heavily skewed “1”:
Finally, this last example demonstrates the LeNet model classifying a “2”:
Running the serialized LeNet model
After our lenet_mnist.py script finishes executing the first time (provided you supplied both –save-model and –weights ), you should now have a lenet_weights.hdf5 file in your output directory.
Instead of re-training our network on subsequent runs of lenet_mnist.py , we can instead load these weights and use them to classify digits.
To load our pre-trained LeNet model, just execute the following command:
$ python lenet_mnist.py –load-model 1 –weights output/lenet_weights.hdf5
I’ve included a GIF animation of LeNet used to correctly classify handwritten digits below:
What’s next? I recommend PyImageSearch University. Course information:
45+ total classes • 39h 44m video • Last updated: July 2022
★★★★★ 4.84 (128 Ratings) • 15,800+ Students Enrolled I strongly believe that if you had the right teacher you could master computer vision and deep learning. Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science? That’s not the case. All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught. If you’re serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery. Inside PyImageSearch University you’ll find: ✓ 45+ courses on essential computer vision, deep learning, and OpenCV topics
on essential computer vision, deep learning, and OpenCV topics ✓ 45+ Certificates of Completion
of Completion ✓ 52+ hours of on-demand video
of on-demand video ✓ Brand new courses released regularly , ensuring you can keep up with state-of-the-art techniques
, ensuring you can keep up with state-of-the-art techniques ✓ Pre-configured Jupyter Notebooks in Google Colab
✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
✓ Access to centralized code repos for all 450+ tutorials on PyImageSearch
on PyImageSearch ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
for code, datasets, pre-trained models, etc. ✓ Access on mobile, laptop, desktop, etc. Click here to join PyImageSearch University
Summary
In today’s blog post, I demonstrated how to implement the LeNet architecture using the Python programming language and the Keras library for deep learning.
The LeNet architecture is a great “Hello, World” network to get your feet wet with deep learning and Convolutional Neural Networks. The network itself is simple, has a small memory footprint, and when applied to the MNIST dataset, can be run on either your CPU or GPU, making it ideal for experimenting and learning, especially if you’re a deep learning newcomer.
This tutorial was primarily code focused, and because of this, I needed to skip over detailed reviews of important Convolutional Neural Network concepts such as activation layers, pooling layers, and dense/fully-connected layers (otherwise this post could have easily been 5x as long).
In future blog posts, I’ll be reviewing each of these layer types in lots of detail — in the meantime, simply familiarize yourself with the code and try executing it yourself. And if you’re feeling really daring, try tweaking the number of filters and filter sizes per convolutional layer and see what happens!
Anyway, I hope you’ve enjoyed this blog post — I’ll certainly be doing more deep learning and image classification posts in the future.
But before you go, be sure to enter your email address in the form below to be notified when future PyImageSearch blog posts are published — you won’t want to miss them!
7.6. Convolutional Neural Networks (LeNet) — Dive into Deep Learning 1.0.0-alpha0 documentation
7.6. Convolutional Neural Networks (LeNet)¶ Colab [pytorch] Open the notebook in Colab Colab [mxnet] Open the notebook in Colab Colab [tensorflow] Open the notebook in Colab SageMaker Studio Lab Open the notebook in SageMaker Studio Lab
We now have all the ingredients required to assemble a fully-functional CNN. In our earlier encounter with image data, we applied a linear model with softmax regression (Section 4.4) and an MLP (Section 5.2) to pictures of clothing in the Fashion-MNIST dataset. To make such data amenable we first flattened each image from a \(28\times28\) matrix into a fixed-length \(784\)-dimensional vector, and thereafter processed them in fully connected layers. Now that we have a handle on convolutional layers, we can retain the spatial structure in our images. As an additional benefit of replacing fully connected layers with convolutional layers, we will enjoy more parsimonious models that require far fewer parameters.
In this section, we will introduce LeNet, among the first published CNNs to capture wide attention for its performance on computer vision tasks. The model was introduced by (and named for) Yann LeCun, then a researcher at AT&T Bell Labs, for the purpose of recognizing handwritten digits in images [LeCun et al., 1998b]. This work represented the culmination of a decade of research developing the technology. In 1989, LeCun’s team published the first study to successfully train CNNs via backpropagation [LeCun et al., 1989].
At the time LeNet achieved outstanding results matching the performance of support vector machines, then a dominant approach in supervised learning, achieving an error rate of less than 1% per digit. LeNet was eventually adapted to recognize digits for processing deposits in ATM machines. To this day, some ATMs still run the code that Yann LeCun and his colleague Leon Bottou wrote in the 1990s!
7.6.1. LeNet¶ At a high level, LeNet (LeNet-5) consists of two parts: (i) a convolutional encoder consisting of two convolutional layers; and (ii) a dense block consisting of three fully connected layers; The architecture is summarized in Fig. 7.6.1. The basic units in each convolutional block are a convolutional layer, a sigmoid activation function, and a subsequent average pooling operation. Note that while ReLUs and max-pooling work better, these discoveries had not yet been made at the time. Each convolutional layer uses a \(5\times 5\) kernel and a sigmoid activation function. These layers map spatially arranged inputs to a number of two-dimensional feature maps, typically increasing the number of channels. The first convolutional layer has 6 output channels, while the second has 16. Each \(2\times2\) pooling operation (stride 2) reduces dimensionality by a factor of \(4\) via spatial downsampling. The convolutional block emits an output with shape given by (batch size, number of channel, height, width). In order to pass output from the convolutional block to the dense block, we must flatten each example in the minibatch. In other words, we take this four-dimensional input and transform it into the two-dimensional input expected by fully connected layers: as a reminder, the two-dimensional representation that we desire uses the first dimension to index examples in the minibatch and the second to give the flat vector representation of each example. LeNet’s dense block has three fully connected layers, with 120, 84, and 10 outputs, respectively. Because we are still performing classification, the 10-dimensional output layer corresponds to the number of possible output classes. While getting to the point where you truly understand what is going on inside LeNet may have taken a bit of work, hopefully the following code snippet will convince you that implementing such models with modern deep learning frameworks is remarkably simple. We need only to instantiate a Sequential block and chain together the appropriate layers, using Xavier initialization as introduced in Section 5.4.2.2. pytorchmxnettensorflow import torch from torch import nn from d2l import torch as d2l def init_cnn ( module ): #@save “””Initialize weights for CNNs.””” if type ( module ) == nn . Linear or type ( module ) == nn . Conv2d : nn . init . xavier_uniform_ ( module . weight ) class LeNet ( d2l . Classifier ): def __init__ ( self , lr = 0.1 , num_classes = 10 ): super () . __init__ () self . save_hyperparameters () self . net = nn . Sequential ( nn . LazyConv2d ( 6 , kernel_size = 5 , padding = 2 ), nn . Sigmoid (), nn . AvgPool2d ( kernel_size = 2 , stride = 2 ), nn . LazyConv2d ( 16 , kernel_size = 5 ), nn . Sigmoid (), nn . AvgPool2d ( kernel_size = 2 , stride = 2 ), nn . Flatten (), nn . LazyLinear ( 120 ), nn . Sigmoid (), nn . LazyLinear ( 84 ), nn . Sigmoid (), nn . LazyLinear ( num_classes )) from mxnet import autograd , gluon , init , np , npx from mxnet.gluon import nn from d2l import mxnet as d2l npx . set_np () class LeNet ( d2l . Classifier ): def __init__ ( self , lr = 0.1 , num_classes = 10 ): super () . __init__ () self . save_hyperparameters () self . net = nn . Sequential () self . net . add ( nn . Conv2D ( channels = 6 , kernel_size = 5 , padding = 2 , activation = ‘sigmoid’ ), nn . AvgPool2D ( pool_size = 2 , strides = 2 ), nn . Conv2D ( channels = 16 , kernel_size = 5 , activation = ‘sigmoid’ ), nn . AvgPool2D ( pool_size = 2 , strides = 2 ), nn . Dense ( 120 , activation = ‘sigmoid’ ), nn . Dense ( 84 , activation = ‘sigmoid’ ), nn . Dense ( num_classes )) self . net . initialize ( init . Xavier ()) import tensorflow as tf from d2l import tensorflow as d2l class LeNet ( d2l . Classifier ): def __init__ ( self , lr = 0.1 , num_classes = 10 ): super () . __init__ () self . save_hyperparameters () self . net = tf . keras . models . Sequential ([ tf . keras . layers . Conv2D ( filters = 6 , kernel_size = 5 , activation = ‘sigmoid’ , padding = ‘same’ ), tf . keras . layers . AvgPool2D ( pool_size = 2 , strides = 2 ), tf . keras . layers . Conv2D ( filters = 16 , kernel_size = 5 , activation = ‘sigmoid’ ), tf . keras . layers . AvgPool2D ( pool_size = 2 , strides = 2 ), tf . keras . layers . Flatten (), tf . keras . layers . Dense ( 120 , activation = ‘sigmoid’ ), tf . keras . layers . Dense ( 84 , activation = ‘sigmoid’ ), tf . keras . layers . Dense ( num_classes )]) We take some liberty in the reproduction of LeNet insofar as we replace the Gaussian activation layer by a softmax layer. This greatly simplifies the implementation, not the least due to the fact that the Gaussian decoder is rarely used nowadays. Other than that, this network matches the original LeNet-5 architecture. Let’s see what happens inside the network. By passing a single-channel (black and white) \(28 \times 28\) image through the network and printing the output shape at each layer, we can inspect the model to make sure that its operations line up with what we expect from Fig. 7.6.2. pytorchmxnettensorflow @d2l . add_to_class ( d2l . Classifier ) #@save def layer_summary ( self , X_shape ): X = torch . randn ( * X_shape ) for layer in self . net : X = layer ( X ) print ( layer . __class__ . __name__ , ‘output shape: \t ‘ , X . shape ) model = LeNet () model . layer_summary (( 1 , 1 , 28 , 28 )) Conv2d output shape : torch . Size ([ 1 , 6 , 28 , 28 ]) Sigmoid output shape : torch . Size ([ 1 , 6 , 28 , 28 ]) AvgPool2d output shape : torch . Size ([ 1 , 6 , 14 , 14 ]) Conv2d output shape : torch . Size ([ 1 , 16 , 10 , 10 ]) Sigmoid output shape : torch . Size ([ 1 , 16 , 10 , 10 ]) AvgPool2d output shape : torch . Size ([ 1 , 16 , 5 , 5 ]) Flatten output shape : torch . Size ([ 1 , 400 ]) Linear output shape : torch . Size ([ 1 , 120 ]) Sigmoid output shape : torch . Size ([ 1 , 120 ]) Linear output shape : torch . Size ([ 1 , 84 ]) Sigmoid output shape : torch . Size ([ 1 , 84 ]) Linear output shape : torch . Size ([ 1 , 10 ]) / home / d2l – worker / miniconda3 / envs / d2l – en – release – 1 / lib / python3 .8 / site – packages / torch / nn / modules / lazy . py : 178 : UserWarning : Lazy modules are a new feature under heavy development so changes to the API or functionality can happen at any moment . warnings . warn ( ‘Lazy modules are a new feature under heavy development ‘ @d2l . add_to_class ( d2l . Classifier ) #@save def layer_summary ( self , X_shape ): X = np . random . randn ( * X_shape ) for layer in self . net : X = layer ( X ) print ( layer . __class__ . __name__ , ‘output shape: \t ‘ , X . shape ) model = LeNet () model . layer_summary (( 1 , 1 , 28 , 28 )) Conv2D output shape : ( 1 , 6 , 28 , 28 ) AvgPool2D output shape : ( 1 , 6 , 14 , 14 ) Conv2D output shape : ( 1 , 16 , 10 , 10 ) AvgPool2D output shape : ( 1 , 16 , 5 , 5 ) Dense output shape : ( 1 , 120 ) Dense output shape : ( 1 , 84 ) Dense output shape : ( 1 , 10 ) @d2l . add_to_class ( d2l . Classifier ) #@save def layer_summary ( self , X_shape ): X = tf . random . normal ( X_shape ) for layer in self . net . layers : X = layer ( X ) print ( layer . __class__ . __name__ , ‘output shape: \t ‘ , X . shape ) model = LeNet () model . layer_summary (( 1 , 28 , 28 , 1 )) Conv2D output shape : ( 1 , 28 , 28 , 6 ) AveragePooling2D output shape : ( 1 , 14 , 14 , 6 ) Conv2D output shape : ( 1 , 10 , 10 , 16 ) AveragePooling2D output shape : ( 1 , 5 , 5 , 16 ) Flatten output shape : ( 1 , 400 ) Dense output shape : ( 1 , 120 ) Dense output shape : ( 1 , 84 ) Dense output shape : ( 1 , 10 ) Note that the height and width of the representation at each layer throughout the convolutional block is reduced (compared with the previous layer). The first convolutional layer uses 2 pixels of padding to compensate for the reduction in height and width that would otherwise result from using a \(5 \times 5\) kernel. As an aside, the image size of \(28 \times 28\) pixels in the original MNIST OCR dataset is a result of trimming 2 pixel rows (and columns) from the original scans that measured \(32 \times 32\) pixels. This was done primarily to save space (a 30% reduction) at a time when Megabytes mattered. In contrast, the second convolutional layer forgoes padding, and thus the height and width are both reduced by 4 pixels. As we go up the stack of layers, the number of channels increases layer-over-layer from 1 in the input to 6 after the first convolutional layer and 16 after the second convolutional layer. However, each pooling layer halves the height and width. Finally, each fully connected layer reduces dimensionality, finally emitting an output whose dimension matches the number of classes.
7.6.2. Training¶ Now that we have implemented the model, let’s run an experiment to see how the LeNet-5 model fares on Fashion-MNIST. While CNNs have fewer parameters, they can still be more expensive to compute than similarly deep MLPs because each parameter participates in many more multiplications. If you have access to a GPU, this might be a good time to put it into action to speed up training. Note that the d2l.Trainer class takes care of all details. By default, it initializes the model parameters on the available devices. Just as with MLPs, our loss function is cross-entropy, and we minimize it via minibatch stochastic gradient descent. pytorchmxnettensorflow trainer = d2l . Trainer ( max_epochs = 10 , num_gpus = 1 ) data = d2l . FashionMNIST ( batch_size = 128 ) model = LeNet ( lr = 0.1 ) model . apply_init ([ next ( iter ( data . get_dataloader ( True )))[ 0 ]], init_cnn ) trainer . fit ( model , data ) trainer = d2l . Trainer ( max_epochs = 10 , num_gpus = 1 ) data = d2l . FashionMNIST ( batch_size = 128 ) model = LeNet ( lr = 0.1 ) trainer . fit ( model , data ) trainer = d2l . Trainer ( max_epochs = 10 ) data = d2l . FashionMNIST ( batch_size = 128 ) with d2l . try_gpu (): model = LeNet ( lr = 0.1 ) trainer . fit ( model , data )
7.6.3. Summary¶ In this chapter we made significant progress. We moved from the MLPs of the 1980s to the CNNs of the 1990s and early 2000s. The architectures proposed, e.g., in the form of LeNet-5 remain meaningful, even to this day. It is worth comparing the error rates on Fashion-MNIST achievable with LeNet-5 both to the very best possible with MLPs (Section 5.2) and those with significantly more advanced architectures such as ResNet (Section 8.6). LeNet is much more similar to the latter than to the former. One of the primary differences, as we shall see, is that greater amounts of computation afforded significantly more complex architectures. A second difference is the relative ease with which we were able to implement LeNet. What used to be an engineering challenge worth months of C++ and assembly code, engineering to improve SN, an early Lisp based deep learning tool [Bottou & Le Cun, 1988], and finally experimentation with models can now be accomplished in minutes. It is this incredible productivity boost that has democratized deep learning model development tremendously. In the next chapter we will follow down this rabbit to hole to see where it takes us.
Wikipedia
LeNet is a convolutional neural network structure proposed by Yann LeCun et al. in 1989. In general, LeNet refers to LeNet-5 and is a simple convolutional neural network. Convolutional neural networks are a kind of feed-forward neural network whose artificial neurons can respond to a part of the surrounding cells in the coverage range and perform well in large-scale image processing.
Development history [ edit ]
LeNet-5 was one of the earliest convolutional neural networks and promoted the development of deep learning. Since 1988, after years of research and many successful iterations, the pioneering work has been named LeNet-5.
Yann LeCun in 2018
In 1989, Yann LeCun et al. at Bell Labs first applied the backpropagation algorithm to practical applications, and believed that the ability to learn network generalization could be greatly enhanced by providing constraints from the task’s domain. He combined a convolutional neural network trained by backpropagation algorithms to read handwritten numbers and successfully applied it in identifying handwritten zip code numbers provided by the US Postal Service. This was the prototype of what later came to be called LeNet.[1] In the same year, LeCun described a small handwritten digit recognition problem in another paper, and showed that even though the problem is linearly separable, single-layer networks exhibited poor generalization capabilities. When using shift-invariant feature detectors on a multi-layered, constrained network, the model could perform very well. He believed that these results proved that minimizing the number of free parameters in the neural network could enhance the generalization ability of the neural network.[2]
In 1990, their paper described the application of backpropagation networks in handwritten digit recognition again. They only performed minimal preprocessing on the data, and the model was carefully designed for this task and it was highly constrained. The input data consisted of images, each containing a number, and the test results on the postal code digital data provided by the US Postal Service showed that the model had an error rate of only 1% and a rejection rate of about 9%.[3]
Their research continued for the next eight years, and in 1998, Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffner reviewed various methods on handwritten character recognition in paper, and used standard handwritten digits to identify benchmark tasks. These models were compared and the results showed that the network outperformed all other models. They also provided examples of practical applications of neural networks, such as two systems for recognizing handwritten characters online and models that could read millions of checks per day.[4]
The research achieved great success and aroused the interest of scholars in the study of neural networks. While the architecture of the best performing neural networks today are not the same as that of LeNet, the network was the starting point for a large number of neural network architectures, and also brought inspiration to the field.
Timeline 1989 Yann LeCun et al. proposed the original form of LeNet LeCun, Y.; Boser, B.; Denker, J. S.; Henderson, D.; Howard, R. E.; Hubbard, W. & Jackel, L. D. (1989). Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541-551.[1] 1989 Yann LeCun proves that minimizing the number of free parameters in neural networks can enhance the generalization ability of neural networks. LeCun, Y.(1989). Generalization and network design strategies. Technical Report CRG-TR-89-4, Department of Computer Science, University of Toronto.[2] 1990 Their paper describes the application of backpropagation networks in handwritten digit recognition once again LeCun, Y.; Boser, B.; Denker, J. S.; Henderson, D.; Howard, R. E.; Hubbard, W. & Jackel, L. D. (1990). Handwritten digit recognition with a back-propagation network. Advances in Neural Information Processing Systems 2 (NIPS*89).[3] 1998 They reviewed various methods applied to handwritten character recognition and compared them with standard handwritten digit recognition benchmarks. The results show that convolutional neural networks outperform all other models. LeCun, Y.; Bottou, L.; Bengio, Y. & Haffner, P. (1998). Gradient-based learning applied to document recognition.Proceedings of the IEEE. 86(11): 2278 – 2324.[4]
Structure [ edit ]
(AlexNet image size should be 227x227x3, instead of 224x224x3, so the math will come out right. The original paper said different numbers, but Andrej Karpathy, the head of computer vision at Tesla, said it should be 227x227x3 (he said Alex didn’t describe why he put 224x224x3). The next convolution should be 11×11 with stride 4: 55x55x96 (instead of 54x54x96). It would be calculated, for example, as: [(input width 227 – kernel width 11) / stride 4] + 1 = [(227 – 11) / 4] + 1 = 55. Since the kernel output is the same length as width, its area is 55×55.) Comparison of the LeNet and AlexNet convolution, pooling, and dense layers(AlexNet image size should be 227x227x3, instead of 224x224x3, so the math will come out right. The original paper said different numbers, but Andrej Karpathy, the head of computer vision at Tesla, said it should be 227x227x3 (he said Alex didn’t describe why he put 224x224x3). The next convolution should be 11×11 with stride 4: 55x55x96 (instead of 54x54x96). It would be calculated, for example, as: [(input width 227 – kernel width 11) / stride 4] + 1 = [(227 – 11) / 4] + 1 = 55. Since the kernel output is the same length as width, its area is 55×55.)
As a representative of the early convolutional neural network, LeNet possesses the basic units of convolutional neural network, such as convolutional layer, pooling layer and full connection layer, laying a foundation for the future development of convolutional neural network. As shown in the figure (input image data with 32*32 pixels) : LeNet-5 consists of seven layers. In addition to input, every other layer can train parameters. In the figure, Cx represents convolution layer, Sx represents sub-sampling layer, Fx represents complete connection layer, and x represents layer index.[1][5][6]
Layer C1 is a convolution layer with six convolution kernels of 5×5 and the size of feature mapping is 28×28, which can prevent the information of the input image from falling out of the boundary of convolution kernel.
Layer S2 is the subsampling/pooling layer that outputs 6 feature graphs of size 14×14. Each cell in each feature map is connected to 2×2 neighborhoods in the corresponding feature map in C1.
Layer C3 is a convolution layer with 16 5-5 convolution kernels. The input of the first six C3 feature maps is each continuous subset of the three feature maps in S2, the input of the next six feature maps comes from the input of the four continuous subsets, and the input of the next three feature maps comes from the four discontinuous subsets. Finally, the input for the last feature graph comes from all feature graphs of S2.
Layer S4 is similar to S2, with size of 2×2 and output of 16 5×5 feature graphs.
Layer C5 is a convolution layer with 120 convolution kernels of size 5×5. Each cell is connected to the 5*5 neighborhood on all 16 feature graphs of S4. Here, since the feature graph size of S4 is also 5×5, the output size of C5 is 1*1. So S4 and C5 are completely connected. C5 is labeled as a convolutional layer instead of a fully connected layer, because if LeNet-5 input becomes larger and its structure remains unchanged, its output size will be greater than 1×1, i.e. not a fully connected layer.
F6 layer is fully connected to C5, and 84 feature graphs are output.
Features [ edit ]
Every convolutional layer includes three parts: convolution, pooling, and nonlinear activation functions
Using convolution to extract spatial features (Convolution was called receptive fields originally)
Subsampling average pooling layer
tanh activation function
Using MLP as the last classifier
Sparse connection between layers to reduce the complexity of computation
Application [ edit ]
Recognizing simple digit images is the most classic application of LeNet as it was raised because of that.
Yann LeCun et al. raised the initial form of LeNet in 1989. The paper Backpropagation Applied to Handwritten Zip Code Recognition[1] demonstrates how such constraints can be integrated into a backpropagation network through the architecture of the network. And it had been successfully applied to the recognition of handwritten zip code digits provided by the U.S. Postal Service.[1]
Development analysis [ edit ]
The LeNet-5 means the emergence of CNN and defines the basic components of CNN.[4] But it was not popular at that time because of the lack of hardware equipment, especially GPU (Graphics Processing Unit, a specialized electronic circuit designed to rapidly manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display device) and other algorithm, such as SVM can achieve similar effects or even exceed the LeNet.
Since the success of AlexNet in 2012, CNN has become the best choice for computer vision applications and many different types of CNN has been raised, such as the R-CNN series. Nowadays, CNN models are quite different from LeNet, but they are all developed on the basis of LeNet.
So you have finished reading the cnn lenet topic article, if you find this article useful, please share it. Thank you very much. See more: LeNet, AlexNet, LeNet-5, DenseNet, LeNet architecture, GoogLeNet, Mạng GoogLeNet, Mạng AlexNet