
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 다층 퍼셉트론 xor on Google, you do not find the information you need! Here are the best content compiled and compiled by the Chewathai27.com/to team, along with other related topics such as: 다층 퍼셉트론 xor 파이썬 퍼셉트론 XOR, 퍼셉트론 XOR 문제, 다층 퍼셉트론 구현, 다층 퍼셉트론 코드, 퍼셉트론 AND, 다층 퍼셉트론 예제, xor 딥러닝 코드, 다층 퍼셉트론 딥러닝 차이
[인공지능]다층 퍼셉트론으로 XOR문제 해결하기
- Article author: ang-love-chang.tistory.com
- Reviews from users: 33488
 Ratings
Ratings - Top rated: 4.9
- Lowest rated: 1
- Summary of article content: Articles about [인공지능]다층 퍼셉트론으로 XOR문제 해결하기 [인공지능]다층 퍼셉트론으로 XOR문제 해결하기. ML.chang 2020. 7. 21. 17:58. 이 책에 있는 내용을 정리 한 것임. 모두의 딥러닝 개정2판: 3 코딩으로 XOR 문제 해결 … …
- Most searched keywords: Whether you are looking for [인공지능]다층 퍼셉트론으로 XOR문제 해결하기 [인공지능]다층 퍼셉트론으로 XOR문제 해결하기. ML.chang 2020. 7. 21. 17:58. 이 책에 있는 내용을 정리 한 것임. 모두의 딥러닝 개정2판: 3 코딩으로 XOR 문제 해결 … 이 책에 있는 내용을 정리 한 것임. 모두의 딥러닝 개정2판: 3 코딩으로 XOR 문제 해결하기 – 4 thebook.io 2 퍼셉트론의 과제 사람의 뇌가 작동하는 데 1,000억 개나 되는 뉴런이 존재해야 하는 이유는 하나의 뉴..
- Table of Contents:
7장 다층 퍼셉트론
‘인공지능’ Related Articles
![[인공지능]다층 퍼셉트론으로 XOR문제 해결하기](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbtWYV6%2FbtqFUBr6i1q%2FACQneTA52JHUCpsax2ZypK%2Fimg.jpg)
퍼셉트론 – XOR (exclusive OR) 문제 :: Atmosphere
- Article author: aeir.tistory.com
- Reviews from users: 972 Ratings
- Top rated: 4.3
- Lowest rated: 1
- Summary of article content: Articles about 퍼셉트론 – XOR (exclusive OR) 문제 :: Atmosphere XOR 문제 해결. 1990년대 다층 퍼셉트론(multilayer perceptron)으로 해결; 아래 그림과 같이 2차원 평면 공간을 3차원으로 확장해서 분류할 … …
- Most searched keywords: Whether you are looking for 퍼셉트론 – XOR (exclusive OR) 문제 :: Atmosphere XOR 문제 해결. 1990년대 다층 퍼셉트론(multilayer perceptron)으로 해결; 아래 그림과 같이 2차원 평면 공간을 3차원으로 확장해서 분류할 … 진리표 컴퓨터 디지털 회로 gate 논리 AND: 둘다 1 이면 1 OR: 둘 중 하나라도 1 이면 1 XOR: 둘 중 하나만 1이면 1 분류기 퍼셉트론 XOR (exclusive OR) 문제 그림처럼, 각각 두 개씩 다른 점이 있다고 할..
- Table of Contents:
퍼셉트론 – XOR (exclusive OR) 문제
진리표
분류기 퍼셉트론
XOR (exclusive OR) 문제
XOR 문제 해결
다층 퍼셉트론
연습 XOR 문제 해결
티스토리툴바
1.2 다층퍼셉트론(MLP) 개념과 XOR 구현 : 네이버 블로그
- Article author: m.blog.naver.com
- Reviews from users: 32616 Ratings
- Top rated: 4.5
- Lowest rated: 1
- Summary of article content: Articles about 1.2 다층퍼셉트론(MLP) 개념과 XOR 구현 : 네이버 블로그 1.2 다층퍼셉트론(MLP) 개념과 XOR 구현 · 1. 퍼셉트론의 한계. AND, NAND, OR 게이트 구현은 하나의 퍼셉트론으로 쉽게 구현할 수 있는 것을 1.1 단원에서 … …
- Most searched keywords: Whether you are looking for 1.2 다층퍼셉트론(MLP) 개념과 XOR 구현 : 네이버 블로그 1.2 다층퍼셉트론(MLP) 개념과 XOR 구현 · 1. 퍼셉트론의 한계. AND, NAND, OR 게이트 구현은 하나의 퍼셉트론으로 쉽게 구현할 수 있는 것을 1.1 단원에서 …
- Table of Contents:
카테고리 이동
아이리스님의블로그
이 블로그
기계학습(머신러닝)
카테고리 글
카테고리
이 블로그
기계학습(머신러닝)
카테고리 글
머신러닝에서 단층/다층퍼셉트론(And, XOR Perceptron) 구현하기 | 양념치킨
- Article author: kejdev.github.io
- Reviews from users: 47244 Ratings
- Top rated: 4.7
- Lowest rated: 1
- Summary of article content: Articles about 머신러닝에서 단층/다층퍼셉트론(And, XOR Perceptron) 구현하기 | 양념치킨 머신러닝에서 단층/다층퍼셉트론(And, XOR Perceptron) 구현하기 … 저번 포스팅에 이어 이번에는 퍼셉트론에 대해 좀더 자세히 다뤄보겠습니다. 또한 직접 PYTHON으로 … …
- Most searched keywords: Whether you are looking for 머신러닝에서 단층/다층퍼셉트론(And, XOR Perceptron) 구현하기 | 양념치킨 머신러닝에서 단층/다층퍼셉트론(And, XOR Perceptron) 구현하기 … 저번 포스팅에 이어 이번에는 퍼셉트론에 대해 좀더 자세히 다뤄보겠습니다. 또한 직접 PYTHON으로 … 저번 포스팅에 이어 이번에는 퍼셉트론에 대해 좀더 자세히 다뤄보겠습니다. 또한 직접 PYTHON으로 구현해보겠습니다.
- Table of Contents:
XOR을 위한 다층 퍼셉트론
- Article author: haningya.tistory.com
- Reviews from users: 7034 Ratings
- Top rated: 3.0
- Lowest rated: 1
- Summary of article content: Articles about XOR을 위한 다층 퍼셉트론 XOR. 퍼셉트론. 1943년 신경과학자 Warren S McCulloch 와 논리학자 Walter Pitts는 하나의 사람 뇌 신경세포를 하나의 이진(Binary)출력을 가지는 … …
- Most searched keywords: Whether you are looking for XOR을 위한 다층 퍼셉트론 XOR. 퍼셉트론. 1943년 신경과학자 Warren S McCulloch 와 논리학자 Walter Pitts는 하나의 사람 뇌 신경세포를 하나의 이진(Binary)출력을 가지는 … XOR 퍼셉트론 1943년 신경과학자 Warren S McCulloch 와 논리학자 Walter Pitts는 하나의 사람 뇌 신경세포를 하나의 이진(Binary)출력을 가지는 단순 논리 게이트로 설명. 여러개의 입력 신호가 가지돌기에 도..
- Table of Contents:
XOR
퍼셉트론
단층 퍼셉트론에서 XOR게이트 구현이 불가능한 이유
다층 퍼셉트론을 학습할 때 학습률(learning rate)이 모델의 학습에 미치는 영향
학습 파라미터를 어떤식으로 초기화 하는게 좋은가
코드
sigmoid 말고 tanh 사용하기
코드 실행해본 Colab 링크
관련글
댓글0
공지사항
최근글
인기글
최근댓글
태그
전체 방문자
티스토리툴바
See more articles in the same category here: https://chewathai27.com/to/blog.
[인공지능]다층 퍼셉트론으로 XOR문제 해결하기
이 책에 있는 내용을 정리 한 것임.
2 퍼셉트론의 과제
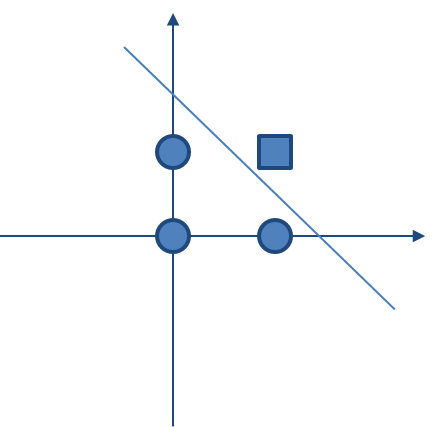
사람의 뇌가 작동하는 데 1,000억 개나 되는 뉴런이 존재해야 하는 이유는 하나의 뉴런만으로는 아무것도 할 수 없기 때문입니다. 퍼셉트론도 마찬가지입니다. 단 하나의 퍼셉트론으로는 많은 것을 기대할 수가 없습니다. 지금부터는 퍼셉트론의 한계와 이를 해결하는 과정을 보며 신경망의 기본 개념을 확립해 보겠습니다. 먼저 그림 6-2를 볼까요?
그림 6-2
사각형 종이에 놓인 검은점 두 개와 흰점 두 개
사각형 종이에 검은점 두 개와 흰점 두 개가 놓여 있습니다. 이 네 점 사이에 직선을 하나 긋는다고 합시다. 이때 직선의 한쪽 편에는 검은점만 있고, 다른 한쪽에는 흰점만 있게끔 선을 그을 수 있을까요?
그림 6-3
선으로는 같은 색끼리 나눌 수 없다: 퍼셉트론의 한계
여러 개의 선을 아무리 그어보아도 하나의 직선으로는 흰점과 검은점을 구분할 수 없습니다.
앞서 배운 선형 회귀와 로지스틱 회귀를 통해 머신러닝이 결국 선이나 2차원 평면을 그리는 작업이란 것을 배웠습니다. 따라서 이와 같은 개념인 퍼셉트론 역시 선을 긋는 작업이라고 할 수 있습니다. 그런데 이 예시처럼 경우에 따라서는 선을 아무리 그어도 해결되지 않는 상황이 있습니다.
3 XOR 문제
이것이 퍼셉트론의 한계를 설명할 때 등장하는 XOR(exclusive OR) 문제입니다.
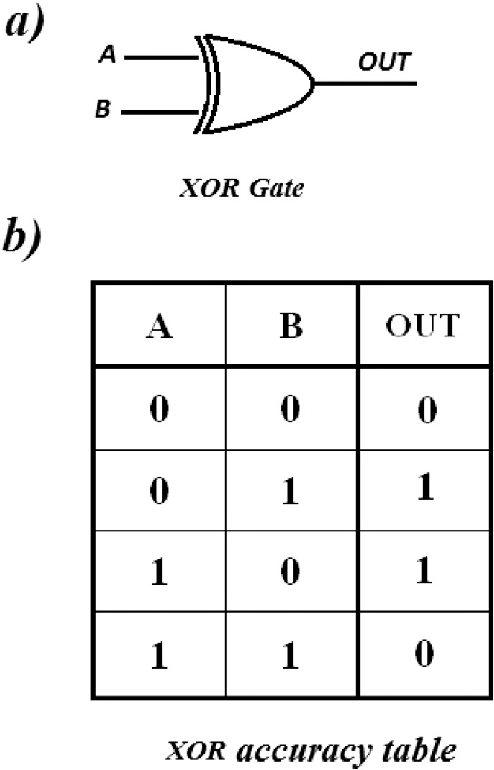
XOR 문제는 논리 회로에 등장하는 개념입니다. 컴퓨터는 두 가지의 디지털 값, 즉 0과 1을 입력해 하나의 값을 출력하는 회로가 모여 만들어지는데, 이 회로를 ‘게이트(gate)’라고 부릅니다.
표 6-1은 AND 게이트, OR 게이트 그리고 XOR 게이트에 대한 값을 정리한 것입니다. AND 게이트는 x1와 x2 둘 다 1일 때 결괏값이 1로 출력됩니다. OR 게이트는 둘 중 하나라도 1이면 결괏값이 1로 출력됩니다. XOR 게이트는 둘 중 하나만 1일 때 1이 출력됩니다.
AND 진리표 OR 진리표 XOR 진리표 x1 x2 결괏값 x1 x2 결괏값 x1 x2 결괏값 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 0 1 1 1 0 0 1 0 1 1 0 1 1 1 1 1 1 1 1 1 0
표 6-1
AND, OR, XOR 게이트에 대한 진리표
표 6-1을 각각 그래프로 좌표 평면에 나타내 보겠습니다. 결괏값이 0이면 흰점으로, 1이면 검은점으로 나타낸 후 조금 전처럼 직선을 그어 위 조건을 만족할 수 있는지 보겠습니다.
그림 6-4
AND, OR, XOR 진리표대로 좌표 평면에 표현한 뒤 선을 그어 색이 같은 점끼리 나누기(XOR은 불가능)
AND와 OR 게이트는 직선을 그어 결괏값이 1인 값(검은점)을 구별할 수 있습니다. 그러나 XOR의 경우 선을 그어 구분할 수 없습니다.
이는 인공지능 분야의 선구자였던 MIT의 마빈 민스키(Marvin Minsky) 교수가 1969년에 발표한 <퍼셉트론즈(Perceptrons)>라는 논문에 나오는 내용입니다. ‘뉴런 → 신경망 → 지능’이라는 도식을 따라 ‘퍼셉트론 → 인공 신경망 → 인공지능’이 가능하리라 꿈꾸던 당시 사람들은 이것이 생각처럼 쉽지 않다는 사실을 깨닫게 됩니다. 알고 보니 간단한 XOR 문제조차 해결할 수 없었던 것입니다. 이 논문 이후 인공지능 연구가 한동안 침체기를 겪게 됩니다. 10여 년이 지난 후에야 이 문제가 해결되는데, 이를 해결한 개념이 바로 다층 퍼셉트론(multilayer perceptron)입니다.
7장 다층 퍼셉트론
앞서 종이 위에 각각 엇갈려 놓인 검은점 두 개와 흰점 두 개를 하나의 선으로는 구별할 수 없다는 것을 살펴보았습니다. 언뜻 보기에 해답이 없어 보이는 이 문제를 해결하려면 새로운 접근이 필요합니다.
어릴 적 친구들에게 장난처럼 들었던 문제인데 의외로 기발한 해답에 기억에 오래 남는 것이 하나 있습니다. 바로 ‘성냥개비 여섯 개로 정삼각형 네 개를 만들 수 있는가’라는 문제였습니다.
그림 7-1
성냥개비 여섯 개로 정삼각형 네 개를?
골똘히 연구해도 답을 찾지 못했던 이 문제는 2차원 평면에서만 해결하려는 고정관념을 깨고 피라미드 모양으로 성냥개비를 쌓아 올리니 해결되었습니다.
그림 7-2
차원을 달리하니 쉽게 완성!
인공지능 학자들은 인공 신경망을 개발하기 위해서 반드시 XOR 문제를 극복해야만 했습니다. 이 문제 역시 고정관념을 깬 기발한 아이디어에서 해결점이 보였습니다. 그림 7-3은 전혀 새로운 방법으로 이를 해결하는 모습을 보여 줍니다.
그림 7-3
XOR 문제의 해결은 평면을 휘어주는 것!
로 종이를 휘어 주는 것이 답이었습니다. 즉, 좌표 평면 자체에 변화를 주는 것입니다. XOR 문제를 해결하기 위해서 우리는 두 개의 퍼셉트론을 한 번에 계산할 수 있어야 합니다. 이를 가능하게 하려면 숨어있는 층, 즉 은닉층(hidden layer)을 만들면 됩니다.
그림 7-4
퍼셉트론에서 다층 퍼셉트론으로
입력층과 은닉층의 그래프를 집어넣어 보면 그림 7-5와 같습니다. 은닉층이 좌표 평면을 왜곡시키는 결과를 가져옵니다.
그림 7-5
은닉층의 공간 왜곡(https://goo.gl/8qEGHD 참조)
입력 값(input)을 놓고 파란색과 빨간색의 영역을 구분한다고 할 때, 그림 7-5의 왼쪽 그림을 보면 어떤 직선으로도 이를 해결할 수 없습니다. 하지만 은닉층을 만들어 공간을 왜곡하면 두 영역을 가로지르는 선이 직선으로 바뀝니다.
1 다층 퍼셉트론의 설계
다층 퍼셉트론이 입력층과 출력층 사이에 숨어있는 은닉층을 만드는 것을 도식으로 나타내면 그림 7-6과 같습니다.
그림 7-6
다중 퍼셉트론의 내부
가운데 숨어있는 은닉층으로 퍼셉트론이 각각 자신의 가중치(w)와 바이어스(b) 값을 보내고, 이 은닉층에서 모인 값이 한 번 더 시그모이드 함수(기호로 σ라고 표시합니다)를 이용해 최종 값으로 결과를 보냅니다. 은닉층에 모이는 중간 정거장을 노드(node)라고 하며, 여기서는 n1과 n2로 표현하였습니다.
n1과 n2의 값은 각각 단일 퍼셉트론의 값과 같습니다.
n1 = σ(x1w11 + x2w21+b1)
n2 = σ(x1w12 + x2w22 + b2)
위 두 식의 결괏값이 출력층으로 보내집니다. 출력층에서는 역시 시그모이드 함수를 통해 y 값이 정해집니다. 이 값을 y out이라 할 때 식으로 표현하면 다음과 같습니다.
이제 각각의 가중치(w)와 바이어스(b)의 값을 정할 차례입니다. 2차원 배열로 늘어놓으면 다음과 같이 표시할 수 있습니다. 은닉층을 포함해 가중치 6개와 바이어스 3개가 필요합니다.
한 노드당 바이어스 하나를 주는구나..
2 XOR 문제의 해결
앞서 우리에게 어떤 가중치와 바이어스가 필요한지를 알아보았습니다. 이를 만족하는 가중치와 바이어스의 조합은 무수히 많습니다. 이를 구하는 방법은 8장에서 소개할 예정입니다. 지금은 먼저 다음과 같이 각 변숫값을 정하고 이를 이용해 XOR 문제를 해결하는 과정을 알아보겠습니다.
이것을 도식에 대입하면 다음과 같습니다.
그림 7-7
다중 퍼셉트론의 내부에 변수를 채워보자.
이제 x1의 값과 x2의 값을 각각 입력해 y 값이 우리가 원하는 값으로 나오는지를 점검해 보겠습니다.
x1 x2 n1 n2 yout 우리가 원하는 값 0 0 σ(0 * (-2) + 0 * (-2) + 3) ≈ 1 σ(0 * 2 + 0 * 2 – 1) ≈ 0 σ(1 * 1 + 0 * 1 – 1) ≈ 0 0 0 1 σ(0 * (-2) + 1 * (-2) + 3) ≈ 1 σ(0 * 2 + 1 * 2 – 1) ≈ 1 σ(1 * 1 + 1 * 1 – 1) ≈ 1 1 1 0 σ(1 * (-2) + 0 * (-2) + 3) ≈ 1 σ(1 * 2 + 0 * 2 – 1) ≈ 1 σ(1 * 1 + 1 * 1 – 1) ≈ 1 1 1 1 σ(1 * (-2) + 1 * (-2) + 3) ≈ 0 σ(1 * 2 + 1 * 2 – 1) ≈ 1 σ(0 * 1 + 1 * 1 – 1) ≈ 0 0
표 7-1
XOR 다층 문제 해결
TIP
≈ 기호는 ‘거의 같다’를 의미하는 것으로 이해하면 됩니다.
표 7-1에서 볼 수 있듯이 n1, n2, y를 구하는 공식에 차례로 대입하니 우리가 원하는 결과를 구할 수 있었습니다. 숨어있는 두 개의 노드를 둔 다층 퍼셉트론을 통해 XOR 문제가 해결된 것입니다.
3 코딩으로 XOR 문제 해결하기
이제 주어진 가중치와 바이어스를 이용해 XOR 문제를 해결하는 파이썬 코드를 작성해 볼까요?
먼저 표 7-1에서 n1의 값을 잘 보면 입력 값 x1, x2가 모두 1일 때 0을 출력하고 하나라도 0이 아니면 1을 출력하게 되어 있습니다. 이는 표 6-1에서 배운 AND 게이트의 정반대 값을 출력하는 방식입니다. 이를 NAND(Negative And) 게이트라고 부릅니다.
그리고 n2의 값을 잘 보면 x1, x2에 대한 OR 게이트에 대한 답입니다.
NAND 게이트와 OR 게이트, 이 두 가지를 내재한 각각의 퍼셉트론이 다중 레이어 안에서 각각 작동하고, 이 두 가지 값에 대해 AND 게이트를 수행한 값이 바로 우리가 구하고자 하는 Y_out임을 알 수 있습니다.
정해진 가중치와 바이어스를 numpy 라이브러리를 사용해 다음과 같이 선언하겠습니다.
import numpy as np w11 = np.array([-2, -2]) w12 = np.array([2, 2]) w2 = np.array([1, 1]) b1 = 3 b2 = -1 b3 = -1
이제 퍼셉트론 함수를 만들어 줍니다. 0과 1 중에서 값을 출력하게 설정합니다.
def MLP(x, w, b): y = np.sum(w * x) + b if y <= 0: return 0 else: return 1 각 게이트의 정의에 따라 NAND 게이트, OR 게이트, AND 게이트, XOR 게이트 함수를 만들어 줍니다. # NAND 게이트 def NAND(x1, x2): return MLP(np.array([x1, x2]), w11, b1) # OR 게이트 def OR(x1, x2): return MLP(np.array([x1, x2]), w12, b2) # AND 게이트 def AND(x1, x2): return MLP(np.array([x1, x2]), w2, b3) # XOR 게이트 def XOR(x1, x2): return AND(NAND(x1, x2),OR(x1, x2)) 이제 x1과 x2 값을 번갈아 대입해 가며 최종 값을 출력해 봅시다. if __name__ == '__main__': for x in [(0, 0), (1, 0), (0, 1), (1, 1)]: y = XOR(x[0], x[1]) print("입력 값: " + str(x) + " 출력 값: " + str(y)) 모두 정리하면 다음과 같습니다. import numpy as np # 가중치와 바이어스 w11 = np.array([-2, -2]) w12 = np.array([2, 2]) w2 = np.array([1, 1]) b1 = 3 b2 = -1 b3 = -1 # 퍼셉트론 def MLP(x, w, b): y = np.sum(w * x) + b if y <= 0: return 0 else: return 1 # NAND 게이트 def NAND(x1, x2): return MLP(np.array([x1, x2]), w11, b1) # OR 게이트 def OR(x1, x2): return MLP(np.array([x1, x2]), w12, b2) # AND 게이트 def AND(x1, x2): return MLP(np.array([x1, x2]), w2, b3) # XOR 게이트 def XOR(x1, x2): return AND(NAND(x1, x2),OR(x1, x2)) # x1, x2 값을 번갈아 대입하며 최종값 출력 if __name__ == '__main__': for x in [(0, 0), (1, 0), (0, 1), (1, 1)]: y = XOR(x[0], x[1]) print("입력 값: " + str(x) + " 출력 값: " + str(y)) 우리가 원하는 XOR 문제의 정답이 도출되었습니다. 이렇게 퍼셉트론 하나로 해결되지 않던 문제를 은닉층을 만들어 해결했습니다. 은닉층을 여러 개 쌓아올려 복잡한 문제를 해결하는 과정은 뉴런이 복잡한 과정을 거쳐 사고를 낳는 사람의 신경망을 닮았습니다. 그래서 이 방법을 ‘인공 신경망’이라 부르기 시작했고, 이를 간단히 줄여서 신경망이라고 통칭합니다.
퍼셉트론 – XOR (exclusive OR) 문제
728×90
반응형
진리표
컴퓨터 디지털 회로 gate 논리
AND: 둘다 1 이면 1
OR: 둘 중 하나라도 1 이면 1
XOR: 둘 중 하나만 1이면 1
분류기 퍼셉트론
300×250
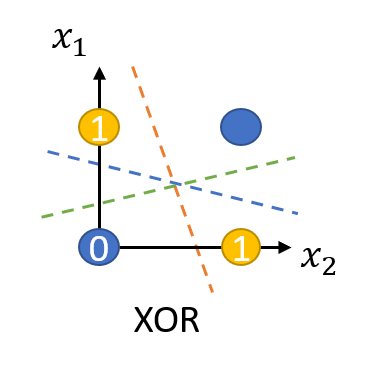
XOR (exclusive OR) 문제
그림처럼, 각각 두 개씩 다른 점이 있다고 할 때, 하나의 선을 그어 색깔별로 분류하는 방법을 생각해 보자.
어떠한 한 개의 직선으로도 분류할 수 없다…. 1969년 Marvin Minsky 가 발견
XOR 문제 해결
1990년대 다층 퍼셉트론(multilayer perceptron)으로 해결
아래 그림과 같이 2차원 평면 공간을 3차원으로 확장해서 분류할 수 있음.
즉, 차원 확장과 좌표 평면 변환 이용
XOR 문제를 해결하기 위해서는 2개의 퍼셉트론을 한번에 계산할 수 있어야 함.
은닉층(hidden layer)을 가진 다층 퍼셉트론을 구현하여 가능.
다층 퍼셉트론
1. 각 퍼셉트론의 가중치(w)와 바이어스(b)를 은닉층의 노드(n)로 보냄.
2. 은닉층으로 들어온 w, b에 시그모이드 함수를 적용하여 최종 결과값을 출력함
w와 b를 구하기 위해서 행렬로 표현하면,
반응형
연습: XOR 문제 해결
아래 예제를 통해서, XOR 진리표를 구할 수 있는지 연습해 보자.
먼저 각 노드 n1, n2를 구하고, 최종 y 출력값을 계산한다.
728×90
반응형
XOR을 위한 다층 퍼셉트론
728×90
XOR
퍼셉트론
1943년 신경과학자 Warren S McCulloch 와 논리학자 Walter Pitts는 하나의 사람 뇌 신경세포를 하나의 이진(Binary)출력을 가지는 단순 논리 게이트로 설명.
출처: https://blog.naver.com/samsjang/220948258166
여러개의 입력 신호가 가지돌기에 도착하면 신경세포 내에서 이들을 하나의 신호로 통합하고 통합된 신호값이 입계값을 초과하면 하나의 단일신호가 생성되며 이 신호가 축삭돌기를 통해 다른 신경세포로 전달하는 것으로 이해함. 이렇게 단순화 된 원리로 동작하는 뇌 세포를 MCP뉴런이라고 부름
이 MCP뉴런 모델을 기초로 퍼셉트론 학습 규칙이라는 개념을 고안하게됨
MCP뉴런이 출력신호를 발생할지 안할지 결정하기 위해, MCP뉴런으로 들어오는 각 입력값에 곱해지는 가중치 값을 자동적으로 학습하는 알고리즘을 제안
*활성함수: 순입력 함수의 결과값을 특정 임계값과 비교하고 순입력 함수 결과값이 이 임계값 보다 크면 1, 그렇지 않으면 -1로 출력하는 함수
출처: https://blog.naver.com/samsjang/220948258166
단층 퍼셉트론: 중간층이 하나의 노드로 구성되어 중간층과 출력층의 구분이 없는 구조
다층 퍼셉트론: 중간층을 구성하는 노드가 여러개 이고, 이러한 중간층이 다수로 구성되어 있는 구조, 여러개의 활성함수, 이에 따른 가중치도 여러개
이러한 다층 인공신경망을 학습하는 알고리즘을 딥러닝 이라고 함
단층 퍼셉트론에서 XOR게이트 구현이 불가능한 이유
단층 퍼셉트론의 한계: 비선형적으로 분리되는 데이터에 대해서는 제대로 된 학습이 불가능함.
그 예시가 AND연산에 대해서는 학습이 가능하지만 XOR에 대해선 학습이 불가능함
이를 극복하기 위한 방안으로 나온 것이 입력층과 출력층 사이에 하나 이상의 중간층을 두어 비선형적으로 분리되는 데이터에 대해서 학습 가능하도록 다층 퍼셉트론이 고안됨
다층 퍼셉트론을 학습할 때, 학습률(learning rate)이 모델의 학습에 미치는 영향
퍼셉트론 알고리즘에서 가중치를 업데이트 하는 식은 다음과 같습니다.
출처: http://blog.naver.com/PostView.nhn?blogId=samsjang&logNo=220948258166&parentCategoryNo=49&categoryNo=&viewDate=&isShowPopularPosts=true&from=search
wj: 트레이닝 데이터의 j번째 특성값 xj와 곱하는 가중치
y: 트레이닝 데이터의 실제 결과값에 대한 활성 함수 리턴값
y^: 예측값에 대한 활성 함수 리턴값
n: 학습률
퍼셉트론에서 학습률을 매우 작은 값으로 할당합니다.
여기서 learning rate 에 대해 알아보면
The learning rate is a hyperparameter that controls how much to change the model in response to the estimated error each time the model weights are updated
즉 학습률은 모델 학습에 있어 변화의 폭을 담당하는 것 같습니다.
학습 파라미터를 어떤식으로 초기화 하는게 좋은가
[파라미터 접근방식]지정된 파라미터: 접근 가능한 고유의 파라미터 사전을 통해 직접 접근하여 초기화
한번에 모든 파라미터 지정: collect_params 메소드를 통해 하나의 사전에 담아두고 쉽게 조회 가능
[파라미터 초기화 방식]제공되는 초기화 (빌트인 초기화)
커스텀 초기화 (init 모듈에 없을 경우)
코드
Input 데이터와 label을 행렬로 표현하는 코드입니다.
reshape 를 통해 인풋인 X는 2×4의 행렬을 만들어 주고 출력인 Y는 1×4 행렬을 만들어 줍니다.
import numpy as np X = np.array([0, 0, 1, 1, 0, 1, 0, 1]).reshape(2,4) Y = np.array([0, 1, 1, 0]).reshape(1,4) print(X) print(Y)
모든 파라미터를 0으로 초기화합니다.
XOR를 구현하기 위해선 다층 퍼셉트론이 필요하기 때문에 2개의 weight 와 bias를 사용합니다.
def init_parameters (num_hidden=2): W1 = np.zeros((2,num_hidden)) B1 = np.zeros((num_hidden,1)) W2 = np.zeros((num_hidden,1)) B2 = np.zeros((1,1)) return W1, B1, W2, B2 W1, B1, W2, B2 = init_parameters()
Hidden Layer 행렬로 표현합니다.
def affine (W, X, B): return np.dot(W.T, X) + B def sigmoid (o): return 1./(1+np.exp(-1*o)) Z1=affine(W1,X,B1) H=sigmoid(Z1) print(H)
output Layer 정의
Z2 = affine(W2,H, B2) Y_hat = sigmoid(Z2) print(Y_hat)
Loss Function 행렬로 구하기
def loss_eval (_params): W1, B1, W2, B2 = _params # Forward: input Layer Z1 = affine(W1, X, B1) H = sigmoid(Z1) # Forward: Hidden Layer Z2 = affine(W2, H, B2) Y_hat = sigmoid(Z2) loss = 1./X.shape[1] * np.sum(-1 * (Y * np.log(Y_hat) + (1-Y) * np.log(1-Y_hat))) return Z1, H, Z2, Y_hat, loss loss_eval ([W1, B1, W2, B2])[-1]
Loss에 대한 parameter 별 편미분을 이용한 parameter update rule 표현 중 gradient 구하기
def get_gradients (_params): W1, B1, W2, B2 = _params m = X.shape[1] Z1, H, Z2, Y_hat, loss = loss_eval([W1, B1, W2, B2]) # BackPropagate: Hidden Layer dW2 = np.dot(H, (Y_hat-Y).T) dB2 = 1. / 4. * np.sum(Y_hat-Y, axis=1, keepdims=True) dH = np.dot(W2, Y_hat-Y) # BackPropagate: Input Layer dZ1 = dH * H * (1-H) dW1 = np.dot(X, dZ1.T) dB1 = 1. / 4. * np.sum(dZ1, axis=1, keepdims=True) return [dW1, dB1, dW2, dB2], loss
BackPropagation을 통해 Multi-layer neural network 훈련
1000번의 iteratione동안 학습시켜 봅니다.
def optimize (_params, learning_rate = 0.1, iteration = 1000, sample_size = 0): params = np.copy(_params) loss_trace = [] for epoch in range(iteration): dparams, loss = get_gradients(params) for param, dparam in zip(params, dparams): param += – learning_rate * dparam if (epoch % 100 == 0): loss_trace.append(loss) _, _, _, Y_hat_predict, _ = loss_eval(params) return params,loss_trace, Y_hat_predict
모델 돌리고 loss 변화하는 cost 그려보기
params = init_parameters(2) new_params, loss_trace, Y_hat_predict = optimize(params, 0.1, 100000, 0) print(Y_hat_predict) print(new_params)
코스트 함수가 변하지 않음
parameter를 random으로 초기화 하여 cost 함수 문제 해결
def init_random_parameters (num_hidden = 2, deviation = 1): W1 = np.random.rand(2,num_hidden)*deviation B1 = np.random.random((num_hidden,1))*deviation W2 = np.random.rand(num_hidden,1)*deviation B2 = np.random.random((1,1))*deviation return W1, B1, W2, B2 init_random_parameters ()
params = init_random_parameters(2, 0.1) new_params, loss_trace, Y_hat_predict = optimize(params, 0.1, 100000) print(Y_hat_predict) # Plot learning curve (with costs) plt.plot(loss_trace) plt.ylabel(‘loss’) plt.xlabel(‘iterations (per hundreds)’) plt.show()
sigmoid 말고 tanh 사용하기
Hidden layer에서 sigmiod 보다 tanh 함수가 더 좋은 성능을 낸다.
왜냐하면 tanh함수는 입력의 총합을 -1 에서 1사이의 값으로 변환해 주고 원점 중심이기 때문에 시그모이드와 달리 편향 이동이 일어나지 않는다.
def tanh(x): ex = np.exp(x) enx = np.exp(-x) return (ex-enx)/(ex+enx) def loss_eval_tanh (_params): W1, B1, W2, B2 = _params # Forward: input Layer Z1 = affine(W1, X, B1) H = tanh(Z1) # Forward: Hidden Layer Z2 = affine(W2, H, B2) Y_hat = sigmoid(Z2) loss = 1./X.shape[1] * np.sum(-1 * (Y * np.log(Y_hat) + (1-Y) * np.log(1-Y_hat))) return Z1, H, Z2, Y_hat, loss def get_gradients_tanh (_params): W1, B1, W2, B2 = _params Z1, H, Z2, Y_hat, loss = loss_eval_tanh([W1, B1, W2, B2]) # BackPropagate: Hidden Layer dW2 = np.dot(H, (Y_hat-Y).T) dB2 = 1./4. * np.sum(Y_hat-Y, axis=1, keepdims=True) dH = np.dot(W2, Y_hat-Y) # BackPropagate: Input Layer dZ1 = dH * (1 – (H * H)) # <- Changed! dW1 = np.dot(X, dZ1.T) dB1 = 1./4. * np.sum(dZ1, axis=1, keepdims=True) return [dW1, dB1, dW2, dB2], loss def optimize_tanh (_params, learning_rate = 0.1, iteration = 1000, sample_size = 0): params = np.copy(_params) loss_trace = [] for epoch in range(iteration): dparams, loss = get_gradients_tanh(params) for param, dparam in zip(params, dparams): param += - learning_rate * dparam if (epoch % 100 == 0): loss_trace.append(loss) _, _, _, Y_hat_predict, _ = loss_eval_tanh(params) return params,loss_trace, Y_hat_predict params = init_random_parameters(2, 0.1) new_params, loss_trace, Y_hat_predict = optimize_tanh(params, 0.1, 5000) print(Y_hat_predict) print(loss_trace[-1]) # Plot learning curve (with costs) plt.plot(loss_trace) plt.ylabel('loss') plt.xlabel('iterations (per hundreds)') plt.show() 코드 실행해본 Colab 링크 colab.research.google.com/drive/1XRTDwqNkH05RMDxpX38sCNPyqPSl7s2s?usp=sharing [출처] blog.naver.com/samsjang/220948258166 excelsior-cjh.tistory.com/177 728x90
So you have finished reading the 다층 퍼셉트론 xor topic article, if you find this article useful, please share it. Thank you very much. See more: 파이썬 퍼셉트론 XOR, 퍼셉트론 XOR 문제, 다층 퍼셉트론 구현, 다층 퍼셉트론 코드, 퍼셉트론 AND, 다층 퍼셉트론 예제, xor 딥러닝 코드, 다층 퍼셉트론 딥러닝 차이