
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 시계열 데이터 머신 러닝 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://chewathai27.com/to team, along with other related topics such as: 시계열 데이터 머신 러닝 시계열 데이터 머신러닝 예제, 시계열 데이터 머신러닝 전처리, 시계열 데이터 AI, LSTM 시계열 예측, 시계열 데이터 예측 알고리즘, 파이썬 시계열 머신러닝, 시계열 데이터 분석, 시계열 데이터 분류
Time series(시계열) Forecasting 시리즈 – 머신러닝 접근법 101 | DataCrew
- Article author: datacrew.tech
- Reviews from users: 38337
 Ratings
Ratings - Top rated: 3.7
- Lowest rated: 1
- Summary of article content: Articles about Time series(시계열) Forecasting 시리즈 – 머신러닝 접근법 101 | DataCrew 그러나, 시계열에 관련된 데이터들은 주위에서 쉽게 볼 수 있습니다. 가장 대표적인 것이 시계열 데이터는 주식 데이터 입니다. 1년 코스피 지수 그래프는 365개의 코스피 … …
- Most searched keywords: Whether you are looking for Time series(시계열) Forecasting 시리즈 – 머신러닝 접근법 101 | DataCrew 그러나, 시계열에 관련된 데이터들은 주위에서 쉽게 볼 수 있습니다. 가장 대표적인 것이 시계열 데이터는 주식 데이터 입니다. 1년 코스피 지수 그래프는 365개의 코스피 … Time series(시계열)이란? 시계열이라는 단어를 들어보신적이 있으신가요? 통계학을 전공한 분이라면 분명 들어보셨을 것입니다. 하지만, 통계학을 전공하지 않으신 분들은 쉽게 들어보기 어려운 단어입니다.그러나, 시계열에 관련된 데이터들은 주위에서 쉽게 볼 수 있습니다. 가장 대표적인
- Table of Contents:
Time series(시계열)이란
시계열 구성요소(components)
시계열 구성요소 간의 구성(composition)
시계열 분석

[시계열] Time Series에 대한 머신러닝(ML) 접근
- Article author: diane-space.tistory.com
- Reviews from users: 41637 Ratings
- Top rated: 3.0
- Lowest rated: 1
- Summary of article content: Articles about [시계열] Time Series에 대한 머신러닝(ML) 접근 ML Approaches for Time Series. 비-전통적인 모델로 타임시리즈를 모델링 해봅시다. 이번 포스팅에서는 타임시리즈 데이터를 분석하기위해 머신러닝 … …
- Most searched keywords: Whether you are looking for [시계열] Time Series에 대한 머신러닝(ML) 접근 ML Approaches for Time Series. 비-전통적인 모델로 타임시리즈를 모델링 해봅시다. 이번 포스팅에서는 타임시리즈 데이터를 분석하기위해 머신러닝 … 원문 towardsdatascience.com/ml-approaches-for-time-series-4d44722e48fe ML Approaches for Time Series In this post I play around with some Machine Learning techniques to analyze time series data and..creative collage portfolio : Analysis & skills
- Table of Contents:
ML Approaches for Time Series
4 — Gaussian Processes
5 — Convolutional NN
![[시계열] Time Series에 대한 머신러닝(ML) 접근](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fu05hN%2FbtqPPC3JG7p%2FEgPNaKNqLvvkSwKVJwMHWk%2Fimg.png)
[ 머신러닝 순한 맛 ] 시계열 데이터의 모든 것, RNN 정복하기!
- Article author: box-world.tistory.com
- Reviews from users: 35051 Ratings
- Top rated: 3.0
- Lowest rated: 1
- Summary of article content: Articles about [ 머신러닝 순한 맛 ] 시계열 데이터의 모든 것, RNN 정복하기! 시퀀스-투-시퀀스 네트워크(좌측 상단) ex) 주식가격 같은 시계열 데이터를 예측하는데 유용합니다. 최근 $0~N$ 일치의 주식 가격을 주입하면 … …
- Most searched keywords: Whether you are looking for [ 머신러닝 순한 맛 ] 시계열 데이터의 모든 것, RNN 정복하기! 시퀀스-투-시퀀스 네트워크(좌측 상단) ex) 주식가격 같은 시계열 데이터를 예측하는데 유용합니다. 최근 $0~N$ 일치의 주식 가격을 주입하면 … 사는 데 더 나은 방법을 찾아라 – 엘빈 토플러 – 코로나로 인해 가장 크게 떠오른 분야가 무엇이냐고 한다면, 저는 주식만한게 없다고 생각합니다. 우린 결국 돈을 벌고 싶고, 미래를 예측하여 주식 가격을 예측..인공지능 / 앱 개발의 모든 것
- Table of Contents:
Recurrent Neuron and Recureent Layer
Memory Cell
Input Sequence and Output Sequence
RNN 훈련하기
Time-Series Forecasting
기준 성능
간단한 RNN 구현하기
심층 RNN
여러 타임 스텝 앞을 예측하기
티스토리툴바
![[ 머신러닝 순한 맛 ] 시계열 데이터의 모든 것, RNN 정복하기!](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fd2HIyV%2FbtraGGxWMYR%2FCdvG4015GI3UDoxkyP5c7k%2Fimg.png)
[ 머신러닝 순한 맛 ] 시계열 데이터의 모든 것, RNN 정복하기!
- Article author: medium.com
- Reviews from users: 6074 Ratings
- Top rated: 3.0
- Lowest rated: 1
- Summary of article content: Articles about [ 머신러닝 순한 맛 ] 시계열 데이터의 모든 것, RNN 정복하기! 시계열(time-series) 데이터란 시간의 흐름에 따라 순차적으로(sequentially) 기록된 데이터를 가리키며, 관찰된 시계열 데이터를 분석하여 미래를 … …
- Most searched keywords: Whether you are looking for [ 머신러닝 순한 맛 ] 시계열 데이터의 모든 것, RNN 정복하기! 시계열(time-series) 데이터란 시간의 흐름에 따라 순차적으로(sequentially) 기록된 데이터를 가리키며, 관찰된 시계열 데이터를 분석하여 미래를 … 사는 데 더 나은 방법을 찾아라 – 엘빈 토플러 – 코로나로 인해 가장 크게 떠오른 분야가 무엇이냐고 한다면, 저는 주식만한게 없다고 생각합니다. 우린 결국 돈을 벌고 싶고, 미래를 예측하여 주식 가격을 예측..인공지능 / 앱 개발의 모든 것
- Table of Contents:
Recurrent Neuron and Recureent Layer
Memory Cell
Input Sequence and Output Sequence
RNN 훈련하기
Time-Series Forecasting
기준 성능
간단한 RNN 구현하기
심층 RNN
여러 타임 스텝 앞을 예측하기
티스토리툴바
머신러닝 시계열 예측 | 호텔리시스
- Article author: hotelysis.com
- Reviews from users: 48176 Ratings
- Top rated: 3.6
- Lowest rated: 1
- Summary of article content: Articles about 머신러닝 시계열 예측 | 호텔리시스 빅데이터 분석에 필요한 엄청난 양의 연산은 인공지능이 해결해 주었습니다. 인공지능 시계열 데이터 예측 모델들은 전통적인 통계 분석 기법들에 기반을 … …
- Most searched keywords: Whether you are looking for 머신러닝 시계열 예측 | 호텔리시스 빅데이터 분석에 필요한 엄청난 양의 연산은 인공지능이 해결해 주었습니다. 인공지능 시계열 데이터 예측 모델들은 전통적인 통계 분석 기법들에 기반을 … 최근의 미드 범죄 수사물을 보면, 얼굴 인식 기술을 활용해 CCTV에 잡힌 범죄자의 신원을 특정하는 것이 당연한 절차인 것처럼 느껴집니다. 알파고와 이세돌 9단의 대국을 보며 충격에 휩싸였던 것이 엊그제 같은데, 순식간에 인공지능은 우리 삶에 파고들어 있는 것 같습니다. 인공지능의 역사 1940년대 말부터 산발적으로 연구되던 인공지능의 가능성은 Marvin Minsky, John McCarthy, Claude Shannon, Nathan Rochester
- Table of Contents:

금융 시계열 데이터를 사용한 머신러닝 | 클라우드 아키텍처 센터 | Google Cloud
- Article author: cloud.google.com
- Reviews from users: 38624 Ratings
- Top rated: 3.1
- Lowest rated: 1
- Summary of article content: Articles about 금융 시계열 데이터를 사용한 머신러닝 | 클라우드 아키텍처 센터 | Google Cloud 이 솔루션은 Google Cloud Platform에서 금융 시계열과 함께 머신러닝을 사용하는 예시를 보여줍니다. 시계열은 금융 분석의 필수적인 부분입니다. …
- Most searched keywords: Whether you are looking for 금융 시계열 데이터를 사용한 머신러닝 | 클라우드 아키텍처 센터 | Google Cloud 이 솔루션은 Google Cloud Platform에서 금융 시계열과 함께 머신러닝을 사용하는 예시를 보여줍니다. 시계열은 금융 분석의 필수적인 부분입니다.
- Table of Contents:
목표
비용
시작하기 전에
튜토리얼 사용
다음 단계
1. 시계열 예측이란? :: 불굴의관돌로그
- Article author: undeadkwandoll.tistory.com
- Reviews from users: 38434 Ratings
- Top rated: 4.0
- Lowest rated: 1
- Summary of article content: Articles about 1. 시계열 예측이란? :: 불굴의관돌로그 관측된 시계열 데이터를 분석하여 미래를 예측하는 문제가 바로 시계열 … 일반적으로 supervised machine learning 모델은 데이터 셋을 학습 데이터 … …
- Most searched keywords: Whether you are looking for 1. 시계열 예측이란? :: 불굴의관돌로그 관측된 시계열 데이터를 분석하여 미래를 예측하는 문제가 바로 시계열 … 일반적으로 supervised machine learning 모델은 데이터 셋을 학습 데이터 … 시계열 예측(Time-Series Forecasting)이란? 시계열(Time-Series) 데이터란 시간의 흐름에 따라 순차적으로(sequentially) 기록된 데이터를 가리킨다. 관측된 시계열 데이터를 분석하여 미래를 예측하는 문제가 바..
- Table of Contents:

시계열 데이터
- Article author: velog.io
- Reviews from users: 2037 Ratings
- Top rated: 3.7
- Lowest rated: 1
- Summary of article content: Articles about 시계열 데이터 단변량 시계열 데이터를 예측하는 방법으로는 머신러닝이나 딥러닝 방법보다는 전통적인 ARIMA, ETS 방법이 효과적이라고 한다. 시계열 데이터의 특성. …
- Most searched keywords: Whether you are looking for 시계열 데이터 단변량 시계열 데이터를 예측하는 방법으로는 머신러닝이나 딥러닝 방법보다는 전통적인 ARIMA, ETS 방법이 효과적이라고 한다. 시계열 데이터의 특성. 시계열 데이터 종류 및 시계열 분석에 적절하다는 머신러닝/딥러닝 종류
- Table of Contents:
머신러닝
딥러닝
ìê³ì´ ì측ì ìí AutoML ì¤ì – Azure Machine Learning | Microsoft Docs
- Article author: docs.microsoft.com
- Reviews from users: 1336 Ratings
- Top rated: 4.8
- Lowest rated: 1
- Summary of article content: Articles about ìê³ì´ ì측ì ìí AutoML ì¤ì – Azure Machine Learning | Microsoft Docs AutoMLConfig 개체는 자동화된 기계 학습 태스크에 필요한 설정 및 데이터를 정의합니다. 예측 모델의 구성은 표준 회귀 모델의 설정과 유사하지만 특히 … …
- Most searched keywords: Whether you are looking for ìê³ì´ ì측ì ìí AutoML ì¤ì – Azure Machine Learning | Microsoft Docs AutoMLConfig 개체는 자동화된 기계 학습 태스크에 필요한 설정 및 데이터를 정의합니다. 예측 모델의 구성은 표준 회귀 모델의 설정과 유사하지만 특히 … Azure Machine Learning Python SDK를 ì¬ì©íì¬ ìê³ì´ ì측 모ë¸ì íìµíëë¡ Azure Machine Learning ìëíë MLì ì¤ì í©ëë¤.
- Table of Contents:
íì êµ¬ì± ìì
íìµ ë° ì í¨ì± ê²ì¬ ë°ì´í°
ì¤í 구ì±
ì íì 구ì±
ì¤í ì¤í
ìµì 모ë¸ë¡ ì측
ëê·ëª¨ ì측
ë ¸í¸ë¶ ìì
ë¤ì ë¨ê³
딥러닝/머신러닝을 활용한 시계열 데이터 분석 | 패스트캠퍼스
- Article author: fastcampus.co.kr
- Reviews from users: 31557 Ratings
- Top rated: 3.3
- Lowest rated: 1
- Summary of article content: Articles about 딥러닝/머신러닝을 활용한 시계열 데이터 분석 | 패스트캠퍼스 시계열 데이터를 중심으로 데이터 분석을 위한 머신러닝, 딥러닝 기초까지 배울 수 있습니다. 시계열 모형을 알기 위해서는 일반적인 비시계열 자료에 쓰이는 통계적 가정 … …
- Most searched keywords: Whether you are looking for 딥러닝/머신러닝을 활용한 시계열 데이터 분석 | 패스트캠퍼스 시계열 데이터를 중심으로 데이터 분석을 위한 머신러닝, 딥러닝 기초까지 배울 수 있습니다. 시계열 모형을 알기 위해서는 일반적인 비시계열 자료에 쓰이는 통계적 가정 … 딥러닝/머신러닝 시계열 데이터 분석다변량 시계열단변량 시계열데이터 분석데이터 애널리스트데이터분석가데이터사이언스데이터사이언티스트딥러닝딥러닝 시계열머신러닝머신러닝 모델링머신러닝 시계열시계열시계열 데이터 분석시계열 예측예측 모델링
- Table of Contents:
딥러닝
머신러닝
수강료

See more articles in the same category here: Top 455 tips update new.
Time series(시계열) Forecasting 시리즈 – 머신러닝 접근법 101
Time series(시계열)이란?
시계열이라는 단어를 들어보신적이 있으신가요?
통계학을 전공한 분이라면 분명 들어보셨을 것입니다. 하지만, 통계학을 전공하지 않으신 분들은 쉽게 들어보기 어려운 단어입니다.
그러나, 시계열에 관련된 데이터들은 주위에서 쉽게 볼 수 있습니다.
가장 대표적인 것이 시계열 데이터는 주식 데이터 입니다.
1년 코스피 지수 그래프는 365개의 코스피 지수가 모여서 만들어진 그래프 입니다.
1일 그래프는 1일 동안 5분 단위로 78개의 코스피 지수가 모여서 만들어진 그래프입니다. 즉, 코스피 시계열 데이터는 시간이라는 특성(feature)와 코스피 지수라는 특성이 모여서 하나의 데이터로 만들어집니다.
주식 데이터를 통해서 살펴본 시계열 데이터를 간결하게 설명하자면 ‘시계열은 일정 시간 간격으로 한 줄로 배열된 데이터를 의미’ 라고 할 수 있습니다.
일정 시간 간격으로 배열되어 있는 데이터인 시계열을 분석을 하기 전에 시계열을 구성하는 요소들을 알아보도록 하겠습니다.
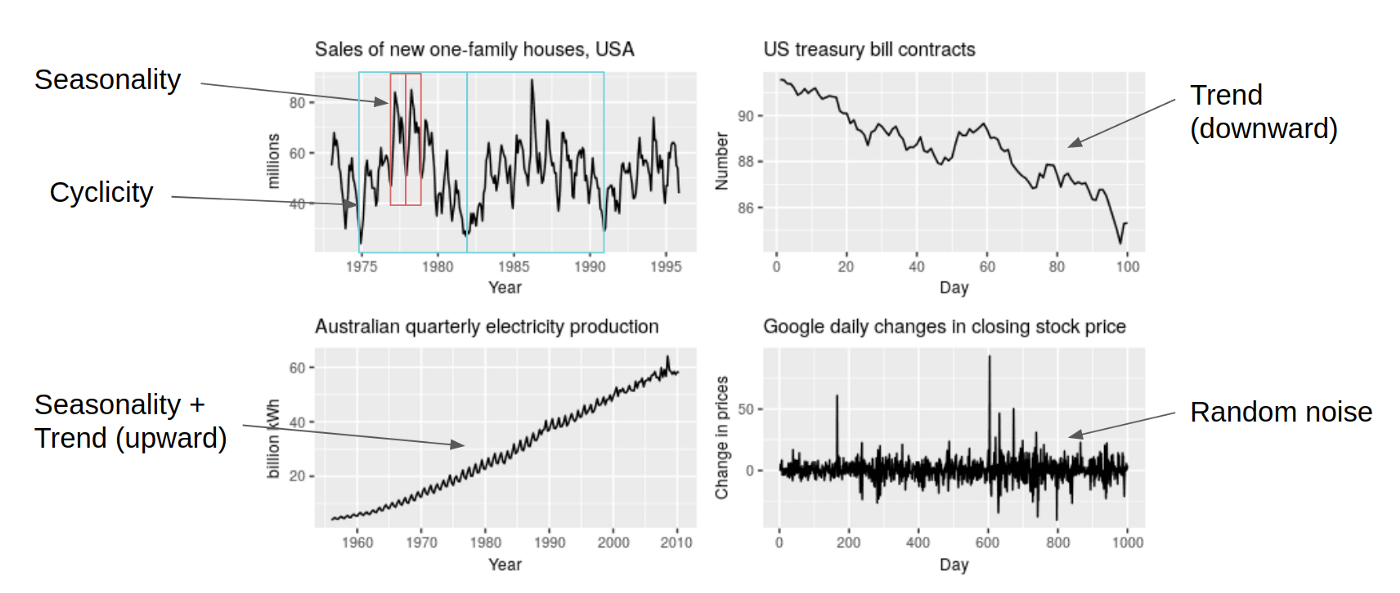
시계열 데이터는 시간에 따라 전개되는 특성과 변동주기에 따라 변화하는 특성이 있습니다. 그래서 변동 주기에 따라 추세, 순환, 계절, 불규칙 변동요인으로 구성되어 있습니다.
시계열 구성요소(components)
시계열을 구성하는 4가지 요인은 아래와 같습니다.
추세 (Trend) : 추세는 장기간 데이터의 일반적인 경향을 보여줍니다. 추세는 부드럽고 일반적인 장기적인 경향입니다. 짧은 구간에서 다른 변동을 보일 수 있지만 전체 추세는 상향, 하향 또는 안정적이어야합니다. 인구, 농업 생산, 제조 품목, 출생 및 사망자 수, 산업 또는 공장 수, 학교 또는 대학 수는 일종의 운동 경향을 보여주는 예입니다.
(Trend) : 추세는 장기간 데이터의 일반적인 경향을 보여줍니다. 추세는 부드럽고 일반적인 장기적인 경향입니다. 짧은 구간에서 다른 변동을 보일 수 있지만 전체 추세는 상향, 하향 또는 안정적이어야합니다. 인구, 농업 생산, 제조 품목, 출생 및 사망자 수, 산업 또는 공장 수, 학교 또는 대학 수는 일종의 운동 경향을 보여주는 예입니다. 순환 (Cyclic Variations ) : 1 년 이상 지속되는 시계열의 변동을 순환이라고 합니다. 이 변동은 1 년 이상의 주기를 갖습니다. Business cycle이라고 불리기도 합니다.
(Cyclic Variations ) : 1 년 이상 지속되는 시계열의 변동을 순환이라고 합니다. 이 변동은 1 년 이상의 주기를 갖습니다. Business cycle이라고 불리기도 합니다. 계절성 (Seasonal Variations ) : 1 년 미만의 기간에 걸쳐 규칙적이고 주기적으로 나타나는 변동입니다. 이러한 변동은 자연의 힘이나 사람이 만든 관습으로 인해 시작됩니다. 다양한 계절 또는 기후 조건은 계절 변화에 중요한 역할을합니다. 농작물 생산량은 계절에 따라 달라지고, 여름에 선풍기와 에어컨의 판매량이 높아지고 겨울에 판매량이 낮아지는 특징을 보이는 것을 계절성이라고 합니다.
(Seasonal Variations ) : 1 년 미만의 기간에 걸쳐 규칙적이고 주기적으로 나타나는 변동입니다. 이러한 변동은 자연의 힘이나 사람이 만든 관습으로 인해 시작됩니다. 다양한 계절 또는 기후 조건은 계절 변화에 중요한 역할을합니다. 농작물 생산량은 계절에 따라 달라지고, 여름에 선풍기와 에어컨의 판매량이 높아지고 겨울에 판매량이 낮아지는 특징을 보이는 것을 계절성이라고 합니다. 불규칙 변동요인(Random or Irregular movements) : 이 변동은 예측할 수없고 제어 할 수없고 예측할 수 없으며 불규칙합니다.
시계열의 구성요소 예시
시계열 구성요소 간의 구성(composition)
시계열 데이터를 구성하는 4가지 구성요소는 단일로 시계열을 구성할 수도 있고 가법, 승법 또한 가능합니다.
가법 모형 (addictive model) : 구성요소 간 독립적이고 가정하여 각 구성요소를 더하는 모형
(addictive model) : 구성요소 간 독립적이고 가정하여 각 구성요소를 더하는 모형 승법 모형(multiplicative model) : 구성요소 간 독립적이지 않고 상호작용 한다고 가정하여 구성요소 간 곱해주는 모형
참고로 여러 구성요소가 하나의 시계열 모형으로 있는 것을 여러개로 나누는 것을 ‘시계열 분해(de-composition)’이라고 합니다.
시계열 분석
시계열 데이터는 머신러닝 분야에서 관심이 많은 데이터 영역 입니다. 실제 세상에서는 시간적 요소가 중요한 데이터들이 많은 케이스가 많기 때문입니다. 시계열 데이터는 시간 변수와 한 개 혹은 여러 개의 변수들로 구성되어 있습니다. 시간과 한 개의 변수로 데이터가 구성되어 있을 땐 분석이 비교적 쉽습니다. 하지만, 시간과 여러 개의 변수로 데이터가 구성되어 있으면 분석이 어렵습니다. 시계열 데이터가 아닌 데이터에 대한 다변수 분석과 비교했을 때도 다변수 시계열 데이터는 분석이 더 어렵습니다.
단변량 시계열 데이터를 예측하는 방법으로는 머신러닝이나 딥러닝 방법보다는 전통적인 ARIMA, ETS 방법이 효과적입니다.
시계열 데이터에 대한 머신러닝 기법을 알아보기 전에 전통적인 분석방법에 대한 간략한 소개를 하겠습니다.
시계열 데이터의 특성
시계열 데이터는 크게 ‘규칙성을 가지는 패턴’과 ‘불규칙한 패턴’ 2가지로 나눕니다. 지금까지 시계열 모형은 이 두가지로 나누어서 만들어졌는데, 규칙성을 가지는 패턴을 이전의 결과와 이후의 결과 사이에서 발생하는 ‘자기상관성(autocorrelativeness)’과 이전에 생긴 불규칙한 사건이 이후의 결과에 편향성을 초래하는 ‘이동평균(moving average) 현상’으로 나누어서 보고 있습니다. 불규칙한 패턴의 경우 일반적으로 White Noise라고 칭하며 평균이 0이며 일정한 분산을 가진 정규분포에서 추출된 임의의 수치라고 가정하고 있습니다.
시계열은 추세 및 계절성 성분을 가지고 있으며 시계열 분석시에는 이를 정상 과정 신호와 분리할 필요가 있다. 회귀 분석을 사용하여 이러한 성분을 분리하는 방법을 설명합니다.
정상 과정(stationary process)은 시간이 지나도 신호의 확률적 특성이 그대로 유지되는 확률 과정을 말합니다. 대부분의 시계열 분석은 정상 과정 분석 방법을 기반으로 한다. 정상 과정 모형 중 가장 대표적인 백색 잡음(white noise)과 ARMA(auto-regressive moving average) 모형에 대해 소개합니다.
비정상 과정(nonstationary process)은 시간에 지나면서 기댓값의 수준이나 분산이 커지는 등 시계열의 특성이 변화하는 확률 과정을 말합니다. 비정상 과정 모형 중 가장 대표적인 것은 ARMA 모형을 누적한 ARIMA(auto-regressive integrated moving average) 모형입니다. ARIMA 모형의 개념을 설명하고 ADF 검정 등의 단위근 검정(unit root test)를 사용하여 모형의 적분 차수(integration order)를 결정하는 법을 설명합니다.
불규칙성을 띄는 시계열 데이터에 규칙성을 부여하는 방법으로 AR,MA,ARMA,ARIMA 모델등을 이용하여 미래를 예측하는 방법이 일반적이었다. 이러한 방법들은 선형 통계적 방법들이었습니다.
시계열 데이터의 머신러닝 모델
머신러닝 방식과 전통적인 통계적 방법의 목표는 동일합니다. 둘 다 sum of squared error과 같은 손실 함수(loss function)를 최소화 함으로써 예측 정확도를 향상시키는 것이 목표입니다. 전통적인 통계적 방법은 선형 처리를 하는 반면 머신러닝 방법은 비선형 알고리즘을 사용하여 최소화를 시켜서 목표를 달성합니다. 최근에는 딥러닝을 이용하여 시계열 데이터의 연속성을 찾아내는 방법이 연구되고 있다. RNN 종류의 LSTM이 좋은 성능을 냅니다. 머신러닝 알고리즘과 세부적으로 딥러닝 알고리즘 목록은 아래와 같습니다.
머신러닝
Multi-Layer Perceptron (MLP)
Bayesian Neural Network (BNN)
Radial Basis Functions (RBF)
Generalized Regression Neural Networks (GRNN)
kernel regression K-Nearest Neighbor regression (KNN)
CART regression trees (CART)
Support Vector Regression (SVR)
Gaussian Processes (GP)
딥러닝
Recurrent Neural Network (RNN)
Long Short-Term Memory (LSTM)
다음 포스팅에서는 시계열 데이터에 대한 예측 모델에 대해서 이야기를 해보겠습니다.
Reference
– https://www.toppr.com/guides/business-mathematics-and-statistics/time-series-analysis/components-of-time-series/
– Hyndman, R. J., & Athanasopoulos, G. (2018). Forecasting: principles and practice. OTexts.
[시계열] Time Series에 대한 머신러닝(ML) 접근
원문
towardsdatascience.com/ml-approaches-for-time-series-4d44722e48fe
ML Approaches for Time Series
비-전통적인 모델로 타임시리즈를 모델링 해봅시다.
이번 포스팅에서는 타임시리즈 데이터를 분석하기위해 머신러닝 기법을 사용하고, 이 시나리오 하에서 잠재적인 사용을 분석할 것입니다.
첫번째 포스트에서는 오직 목차의 첫번째 부분만 발전 시키겠습니다. 나머지는 목차로 부터 분리된 포스트로 접근 가능할 것입니다.
Note : 이번 연구는 2017년 부터 시작되었습니다. 그래서 몇몇 라이브러리들이 업데이트 됬을 수도 있습니다.
목차
1 – 데이터 생성, 창(windows) 과 기초 모델(baseline model)
2 – 유전 프로그래밍 : 기호 회귀 분석(symbolic regression)
3 – 극단의 학습 머신
4 – 가우시안 프로세스
5 – 합성곱 신경망 (CNN)
1 – 데이터 생성, 창(windows) 과 기초 모델(baseline model)
1.1 – 데이터 생성
이번 연구에서는 비주기적 시계열 데이터에 대한 분석을 경험하게 될것입니다. 우리는 3개의 랜덤 변수인 $x_1 , x_2, x_3 $의 합성 데이터를 만들고, 이러한 변수들의 일부 시차들의 선형 조합에 약간의 노이즈를 추가한 반응 변수인 $y$를 결정할 것입니다.
이런 방식으로 우리는 함수가 100% 예측가능하진 않지만, 반응변수가 예측치에 의존한다는 것과, 반응 변수에 대해 이전의 예측치에 대한 시차 (lags)의 효과로 유발된 시간 의존성 (time dependency) 이 있다는 것을 확실히 할 수 있습니다.
이 파이썬 스크립트는 시계열 데이터를 고려하는 창(windows)를 만들 것입니다. 그 이유는 우리가 가능한 가장 완전한 정보를 모델들에게 제공할 수 있게 문제의 틀을 형성하기 위함입니다.
첫번째로 우리가 가진 데이터와 어떤 기술을 우리가 앞으로 적용해야하는지 일단 봅시다.
import numpy as np import pandas as pd import matplotlib.pyplot as plt import copy as cp
N = 600 t = np.arange(0, N, 1).reshape(-1,1) # 각 숫자에다가 랜덤 오차항을 더함 t = np.array([t[i] + np.random.rand(1)/4 for i in range(len(t)) ]) # 각 숫자에다가 랜덤 오차항을 뺌 t = np.array([t[i] – np.random.rand(1)/7 for i in range(len(t)) ]) t = np.array(np.round(t,2)) x1 = np.round((np.random.random(N) * 5).reshape(-1,1),2) x2 = np.round((np.random.random(N) * 5).reshape(-1,1),2) x3 = np.round((np.random.random(N) * 5).reshape(-1,1),2) n = np.round((np.random.random(N)*2).reshape(-1,1),2) y = np.array([((np.log(np.abs(2 + x1[t])) – x2[t-1]**2) + 0.02 * x3[t-3]*np.exp(x1[t-1])) for t in range(len(t))]) y = np.round(y+n ,2 )
fig, (ax1,ax2) = plt.subplots(nrows=2) fig.set_size_inches(30,14) ax1.plot(y, marker = “o”) # 600일간 데이터 ax2.plot(y[:100], marker = “o”) # 100일간 데이터
이제, 우리는 3개의 독립변수에 노이즈를 첨가한 반응변수 y 함수를 가지고 있습니다.
또한 반응 변수는 직접적으로 주어진 지점에서 그들의 값 뿐만 아니라 독립 변수의 시차에 연관 (correlated) 되어 있습니다. 이 방식대로 우리는 시간 의존성을 보장하고, 우리의 모델이 이런 행동들을 식별하도록 만들 것입니다.
또한, 타임스템프의 간격이 균일하지 않습니다. 이런 식으로, 우리는 우리의 모델들이 단지 관측 수 (행)로 시리즈를 다룰 수 없기 때문에 시간 의존성을 이해하기 원한다는 생각을 굳건히 합니다.
우리는 데이터에 높은 비 선형성을 유도할 목적으로 지수연산자와 로그연산자를 포함시켰습니다.
1.2 – 창(Windows) 형성하기
이번 연구에서 모든 모델들이 따르는 접근은 정확한 예측을 달성하기 위해 우리가 가지고 있는 정보를 과거로 부터 주어진 시점에서 가능한 가장 완전한 정보를 모델에 제공하는 고정된 창(windows) 으로 재구성하는 것입니다. 추가적으로, 우리는 반응 변수 자체의 이전 값을 독립 변수로 제공하는 것이 모형에 어떤 영향을 미치는지 확인할 것입니다.
어떻게 되는지 한번 봅시다.
이 그림은 오직 시간 축과 반응변수만을 보여줍니다. 우리의 경우, t 값에 대한 반응 변수들은 3개 의 변수들이 있다는 것을 기억하세요.
제일 위에있는 그림은 w 크기로 선택된 (그리고 고정된) 창을 볼 수 있습니다. 이 경우에는 창의 크기가 4 이구요. 이것은 모델이 t+1 지점에서의 예측을 통해 창에 포함된 정보를 매핑한다는 사실을 의미합니다. 반응의 크기는 r 이 있는데, 우리는 과거에 몇가지 타임 스텝을 예측할 수 있었기 때문입니다. 이는 many-to-many 관계를 가집니다. 단순하고 쉬운 시각화를 위해서, 우리는 r=1 로 두겠습니다.
우리는 이제 Sliding Window 의 효과를 확인할 수 있습니다. 모델이 매핑함수를 찾기위해 갖게되는 input과 output의 다음 짝은 window를 한 스텝 미래로 움직음으로써 얻어집니다. 그리고 이전의 스텝에서 했던 것 처럼 같은 동작을 이어나갑니다.
Ok. 그러면, 어떻게 우리가 현재 데이터 셋에 이것을 적용할 수 있을까요? 우리가 필요한 것을 한번 봅시다. 그리고 우리의 유용한 함수를 만들어봅시다.
하지만 첫번째로, 우리는 시간이 절대값이 되는 것을 원하지 않습니다. 관찰 사이의 경과시간이 어느것인지 아는 것이 더 흥미로운 점입니다. (데이터가 균일하지 않다는 것을 기억하세요!). 그래서, $\Delta t$를 만들고, 우리의 데이터에 적용해봅시다.
dataset = pd.DataFrame(np.concatenate((t,x1,x2,x3,y), axis=1), columns = [‘t’,’x1′,’x2′,’x30′,’y’]) dataset[:7]
deltaT = np.array([(dataset.t[i+1] – dataset.t[i]) for i in range(len(dataset)-1)]) deltaT = np.concatenate( (np.array([0]), deltaT)) deltaT[:7]
dataset.insert(1,’∆t’,deltaT) dataset.head(3)
이제 우리의 데이터셋이 어떻게 생겼는지 알게되었습니다. 우리의 helper 함수가 테이블의 구성으로 무엇을 하기 원하는지 재현해봅시다.
window사이즈가 4인 경우에 :
우리의 함수가 하는 것은 window 안에 포함되어있는 모든 정보를 압축 (flatten) 하는 것입니다. 이 정보는 W window 내의 모든 값이며, 예측을 원하는 시간의 타임스탬프를 뜻합니다.
이 방식으로, 우리는 시스템을 모델링 하기 위한 2가지 다른 등식을 가지고 있으며, 새로운 예측치로 반응변 수의 이전의 값을 포함하고 있는 지에 따라 의존합니다.
함수가 리턴해야하는 결과는 이렇게 생겼습니다 :
우리는 $ l = n – (w+r) +1 $개의 windows를 만들 수 있을 것입니다, 왜냐하면 $Y(0)$ 의 첫번째 값에 대한 이전 정보가 없기 때문에 첫번째 행이 손실되기 때문입니다.
우리가 언급해온 모든 시차들은 모델의 새로운 예측치로 행동합니다 ( 이 시각화에서 Y의 이전 값이 포함되지 않았지만, 같은 값을 $X_i$ 로 따르게될 것입니다. ) 그리고 나서, (경과한) 타임스탬프는 여기서 우리가 원하는 예측값이 ∆t(4)가 되길 원할 것이며, 그에 따르는 예측에 대한 값이 Y(4)가 되야합니다. 모든 첫번째 ∆t(0) 가 0으로 초기화된다는 점에 주목하세요. 모든 window를 같은 범위로 표준화 하기를 원하기 때문입니다.
여기에 이 과정을 달성할 수 있는 코드를 만들었습니다. WindowSlider 형태의 함수가 있고 , 이 함수로 부터 파라미터를 변화하면서 다른 windows를 구성하는 객체를 만들 수 있습니다.
class WindowSlider(object): def __init__(self, window_size = 5): “”” Window Slider object ==================== w: window_size – number of time steps to look back o: offset between last reading and temperature r: response_size – number of time steps to predict l: maximum length to slide – (#obeservation – w) p: final predictors – (# predictors *w) “”” self.w = window_size self.o = 0 self.r = 1 self.l = 0 self.p = 0 self.names = [] def re_init(self, arr): “”” Helper function to initializate to 0 a vector “”” arr = np.cumsum(arr) return arr – arr[0] def collect_windows(self, X, window_size = 5, offset = 0, previous_y = False): “”” Input: X is the input matrix, each column is a variable Returns : different mappings window-output “”” cols = len(list(X))-1 N = len(X) self.o = offset self.w = window_size self.l = N – (self.w + self.r) + 1 if not previous_y: self.p = cols * self.w if previous_y: self.p = (cols +1) * self.w # Create the names of the variables in the window # Check first if we need to create that for the response itself if previous_y: x = cp.deepcopy(X) if not previous_y: x = X.drop(X.columns[-1], axis=1) for j , col in enumerate(list(x)): for i in range(self.w): name = col + (“(%d)” % (i+1)) self.names.append(name) # Incorporate the timestampes where we want to predict for k in range(self.r): name = “∆t” + (“(%d)” % (self.w + k +1)) self.names.append(name) self.names.append(“Y”) df = pd.DataFrame(np.zeros(shape = (self.l, (self.p + self.r +1))), columns = self.names) # Populate by rows in the new dataframe for i in range(self.l): slices = np.array([]) # Flatten the lags of predictors for p in range(x.shape[1]): line = X.values[i:self.w+i,p] # Reinitialization at every window for ∆T if p == 0: line = self.re_init(line) # Concatenate the lines in one slice slices = np.concatenate((slices,line)) # Incorporate the timestamps where we want to predict line = np.array([self.re_init(X.values[i:i+self.w +self.r,0])[-1]]) y = np.array(X.values[self.w + i + self.r -1, -1]).reshape(1,) slices = np.concatenate((slices,line,y)) # Incorporate the slice to the cake (df) df.iloc[i,:] = slices return df
1.2 – 기본 모델 (Baseline Model)
“항상 단순한 것을 먼저해라. 필요한 경우에만 지능을 적용해라” – Thad Starner
Windows 생성
w = 5 train_constructor = WindowSlider() train_windows = train_constructor.collect_windows(trainset.iloc[:,1:], previous_y = False) test_constructor = WindowSlider() test_windows = test_constructor.collect_windows(testset.iloc[:,1:], previous_y = False) train_constructor_y_inc = WindowSlider() train_windows_y_inc = train_constructor_y_inc.collect_windows(trainset.iloc[:,1:], previous_y = True) test_constructor_y_inc = WindowSlider() test_windows_y_inc = test_constructor_y_inc.collect_windows(testset.iloc[:,1:], previous_y = True) train_windows.head(3)
이제 모든 예측치, 남은 변수들의 과거 타임 스텝의 기록(window_length) 과 ∆t 의 누적 합을 어떻게 windows가 가져오는지 볼 수 있습니다.
예측치(prediction) = 현재(current)
우선 다음 타임스탬프의 예측으로 마지막 값(각 예측 지점에서 현재 값)을 주는 간단한 모델부터 시작해보겠습니다.
# ________________ Y_pred = current Y ________________ bl_trainset = cp.deepcopy(trainset) bl_testset = cp.deepcopy(testset) bl_train_y = pd.DataFrame(bl_trainset[‘y’]) bl_train_y_pred = bl_train_y.shift(periods = 1) bl_y = pd.DataFrame(bl_testset[‘y’]) bl_y_pred = bl_y.shift(periods = 1) bl_residuals = bl_y_pred – bl_y bl_rmse = np.sqrt(np.sum(np.power(bl_residuals,2)) / len(bl_residuals)) print(“RMSE = %.2f” % bl_rmse) print(“Time to train = 0 secconds”) >>> RMSE = 9.78 Time to train = 0 secconds
fig, ax1 = plt.subplots(nrows=1) fig.set_size_inches(40,10) ax1.plot(bl_y, marker = “o” , label = “actual”) # 100일간 데이터 ax1.plot(bl_y_pred, marker = “o”, label = “predict”) # 100일간 데이터 ax1.legend(prop={‘size’:30})
결론 우리는 이미 다가오는 결과를 비교할 가치가 있습니다.
우리는 주어진 현재 값을 예측 값으로 고려하는 단순한 룰을 적용해보았습니다. 시계열에서 반응 변수의 값이 더욱 안정적이라면(stable) (a.k.a stationary) , 이 방식은 때때로 ML 알고리즘보다 놀랍게도 더 나은 성능을 보여줄 것입니다. 이런 경우에 데이터의 지그재그(zig-zag)는 악명이 높아 예측력이 떨어지는 것으로 이어집니다.
다중 선형 회귀 (Multiple Linear Regression)
우리의 다음접근은 다중 선형회귀 모델을 구성하는 것입니다.
# ______________ MULTIPLE LINEAR REGRESSION ______________ # import sklearn from sklearn.linear_model import LinearRegression import time lr_model = LinearRegression() lr_model.fit(trainset.iloc[:,:-1], trainset.iloc[:,-1]) t0 = time.time() lr_y = testset[“y”].values lr_y_fit = lr_model.predict(trainset.iloc[:,:-1]) lr_y_pred = lr_model.predict(testset.iloc[:,:-1]) tF = time.time() lr_residuals = lr_y_pred – lr_y lr_rmse = np.sqrt(np.sum(np.power(lr_residuals,2))/len(lr_residuals)) print(“RMSE = %.2f” % lr_rmse) print(“Time to train = %.2f seconds” % (tF-t0)) >>> RMSE = 7.52 Time to train = 0.01 seconds
fig, ax1 = plt.subplots(nrows=1) fig.set_size_inches(40,10) ax1.plot(lr_y, marker = “o” , label = “actual”) # 100일간 데이터 ax1.plot(lr_y_pred, marker = “o”, label = “predict”) # 100일간 데이터 ax1.legend(prop={‘size’:30})
결론 다중 선형 회귀 모형이 얼마나 반응 변수의 동작을 포착하지 못하는지 알 수 있습니다. 이는, 반응변수와 독립변수 간의 비- 선형 관계 때문인데요. 또한 주어진 시간에 반응변수에게 영향을 미치는 것은 변수들간의 시차입니다. 따라서 이 관계를 매핑할 수 없는 모형에 대해 서로 다른 행에 값(values)들이 있습니다.
나는(저자는) windows의 구조에 대해 설명할 때 우리가 만든 가정을 이제 어떻게 확인해야 할지 궁금해졌습니다. 우리는 모든 예측 지점에 대해 완전한 정보 셋을 구성하기 원한다고 말해보겠습니다. 그래서, windows를 구성한 후의 예측력이 올라갸아합니다… 한번 가보죠 !
Windows를 가진 다중 선형 회귀 ( MLR with the Windows)
# ___________ MULTIPLE LINEAR REGRESSION ON WINDOWS ___________ lr_model = LinearRegression() lr_model.fit(train_windows.iloc[:,:-1], train_windows.iloc[:,-1]) t0 = time.time() lr_y = test_windows[‘Y’].values lr_y_fit = lr_model.predict(train_windows.iloc[:,:-1]) lr_y_pred = lr_model.predict(test_windows.iloc[:,:-1]) tF = time.time() lr_residuals = lr_y_pred – lr_y lr_rmse = np.sqrt(np.sum(np.power(lr_residuals,2))/ len(lr_residuals)) print(“RMSE = %.2f” %lr_rmse) print(“Time to Train = %.2f seconds” % (tF-t0)) >>> RMSE = 2.51 Time to Train = 0.01 seconds
fig, ax1 = plt.subplots(nrows=1) fig.set_size_inches(40,10) ax1.plot(lr_y, marker = “o” , label = “actual”) # 100일간 데이터 ax1.plot(lr_y_pred, marker = “o” , label = “predict”) # 100일간 데이터 ax1.legend(prop={‘size’:30})
Wow! 굉장한 향상을 보였습니다.
이제 우리는 물리칠 수 있는 매우 강력한 모델이 있습니다. 새로운 windows 로, 모델은 전체 window 정보와 반응변수간의 관계를 찾을 수 있을 것으로 보입니다.
2 — 기호 회귀분석 (Symbolic Regression)
기호 회귀분석은 주어진 데이터셋을 적합하는 최적의 모델을 찾기위한 수학적 표현의 공간을 찾는 회귀 분석의 한 유형입니다.
기호 회귀분석의 기본은 유전 프로그래밍인데요, 그래서 진화 알고리즘 (a.k.a. 유전 알고리즘 (Genetic Algorithm – GA)이라고 합니다.
어떻게 알고리즘이 작동하는지 몇마디로 요약하면, 첫번째로 위의 그림과 같이, 수학적 표현이 트리 구조로 표현된다는 것을 이해할 필요가 있습니다.
이런 방식으로 알고리즘은 1세대에서 많은 나무의 개체수를 가지고 시작할 것이며, 이는 적합 함수 (fitness fuction)에 따라 측정될 것입니다. 우리의 경우에는 RMSE이죠. 각 세대에 가장 우수한 개인들은 그들 사이를 가로지르고 탐험과 무작위성을 포함하기 위해 일부 돌연변이를 적용합니다. 이 반복적인 알고리즘은 정지 조건이 충족될 때 끝납니다.
이 비디오는 유전 프로그래밍에 대한 훌륭한 설명을 해주고 있습니다.
모델
####################### # CREATION OF THE MODEL ####################### # !pip instal gplearn import gplearn as gpl from gplearn.genetic import SymbolicRegressor # It is possible to create custom operations to be considered in the tree def _xexp(x): a = np.exp(x); a[np.abs(a) > 1e+9] = 1e+9 return a xexp = gpl.functions.make_function( function = _xexp , name = ‘xexp’, arity=1) #function_set = [‘add’, ‘sub’,’mul’,’div’,’sin’,’log’] # ,xexp] function_set = [‘add’, ‘sub’,’mul’,’div’] if ‘model’ in locals(): del model model = SymbolicRegressor(population_size = 3000, tournament_size = 5, generations = 25, stopping_criteria = 0.1, function_set = function_set, metric = ‘rmse’, p_crossover = 0.65, p_subtree_mutation = 0.15, p_hoist_mutation = 0.05, p_point_mutation = 0.1, verbose = 1, random_state = None, n_jobs = -1) ########################################################### # TRAIN THE NETWORK AND PREDICT – Without previous values y ########################################################### # Train t0 = time.time() model.fit(train_windows.values[:,:-1], train_windows.values[:,-1]) tF = time.time() # Predict sr_y_fit = model.predict(train_windows.values[:,:-1]).reshape(-1,1) sr_y_pred = model.predict(test_windows.values[:,:-1]).reshape(-1,1) # Calculating Errors sr_residuals = sr_y_pred – testset.iloc[5:,-1].values.reshape(-1,1) sr_rmse = np.sqrt(np.sum(np.power(sr_residuals,2))/ len(sr_residuals)) print(“RMSE = %f” % sr_rmse) print(“Time to train %.2f” % (tF-t0)) print(model._program)
fig, ax1 = plt.subplots(nrows=1) fig.set_size_inches(40,10) ax1.plot(testset.iloc[5:,-1].values, marker = “o”, label=”actual”) # 100일간 데이터 ax1.plot(sr_y_pred, marker = “o”, label=”predict”) # 100일간 데이터 ax1.legend(prop={‘size’:30})
결론
우리는 상징적 회귀분석이 검증데이터에 거의 완벽한 적합과 함께 상당히 좋은 성능을 발휘한다는 것을 보고 있습니다.
놀랍게도, 나는 더 많은 훈련 시간의 단점을 가지고도 가장 단순한 네개의 operators (덧셈, 뺄셈, 곱셈, 나눗셈) 만 포함시킴으로써 최고의 정확도를 달성했습니다.
나는 당신이 모델의 다른 파라미터들을 시도해보고 결과를 향상시키기를 기대합니다!
3 — 극단의 학습 머신 (Extreme Learning Machines)
극단의 학습 머신은 중요하고 알려진 머신러닝 기법입니다. 이 기법의 주요 측면은 모델의 파라미터들을 계산하기위해 학습 과정을 필요로 하지 않는다는 점입니다.
본질적으로, 한 EML 은 단층 피드포워드 신경망(Single-Layer-Feed-Forward Neural Network) 입니다 (SLFN) ELM 이론은 히든 레이어의 가중치 값이 조정될 필요가 없으며, 따라서 트레이닝 데이터와 독립적일 필요가 있다는 것을 보여줍니다.
보편적인 근사이론 (universal approximation property) 은 EML이 모든 숨겨진 뉴런에 대한 파라미터를 학습하기에 충분한 데이터를 가지고 있다면, 원하는 정확도로 회귀 문제를 해결할 수 있다는 것을 의미합니다.
EML은 또한 모델 구조와 정규화(regularization)의 이점을 얻는데, 이는 무작위 초기화 및 오버피팅의 부정적인 효과를 감소시킨다는 것입니다.
N개의 트레이닝 샘플 (x, t) 를 고려해보면, L개의 히든 신경망 출력값을 가진 SLFN은 다음과 같습니다 :
네트워크의 target, inputs , outputs 의 관계는 다음과 같습니다 :
히든 신경망이 입력 데이터를 두단계에 걸쳐 다른 표현으로 변형시킵니다. 첫번째로, 데이터는 입력층의 가중치와 편향을 통해 히든 레이어에 투영된 다음, 비선형 활성화 함수의 결과에 적용됩니다.
실제로, ELMs은 행렬 형태로 공통 신경망으로 해결됩니다. 행렬 형태는 다음과 같이 표현됩니다. :
그리고 여기에 이 방법이 도출하는 중요한 부분이 있습니다. T가 우리가 도달하고자 하는 target임을 감안할 때, 최소 제곱 오차 항이 있는 시스템은 무어-펜로즈 일반화된 유사 역행렬 (Moore-Penrose generalized inverse) 을 사용한 독특한 솔루션을 사용할 수 있습니다. 따라서, 우리는 한번의 작업으로 target T를 예측할 수 있는 최소한의 오차를 가진 해결책이 되는 히든레이어의 가중치 값을 계산할 수 있습니다.
이 가짜역행렬(presudoinverse)은 단수값 분해(Singular Value Decomposition)를 사용하여 계산되었습니다.
이 글에서는 어떻게 EML이 작동하는지, 그리고 EML의 높은 성능의 Toolbox 패키지와 MATLAB과 Python의 실행에 대해 상세하게 잘 정리된 설명이 있습니다.
모델
class Network(object): def __init__(self, input_dim, hidden_dim = 10, output_dim = 1): “”” Neural Network object “”” self.N = input_dim self.M = hidden_dim self.O = output_dim self.W1 = np.matrix(np.random.rand(self.N, self.M)) self.W2 = np.matrix(np.random.rand(self.M, self.O)) self.U = 0 self.V = 0 self.S = 0 self.H = 0 self.alpha = 0 # for regularization # Helper function def sigmoid(self, x): return 1.0 / (1.0 + np.exp(-0.1 * x)) – 0.5 def predict(self,x): “”” Forward pass to calculate the output “”” x = np.matrix(x) y = self.sigmoid( x @ self.W1) @ self.W2 return y def train(self, x, y): “”” Compute W2 that lead to minimal LS “”” X = np.matrix(x) Y = np.matrix(y) self.H = np.matrix(self.sigmoid(X @ self.W1)) H = cp.deepcopy(self.H) self.svd(H) iH = np.matrix(self.V) @ np.matrix(np.diag(self.S)).I @ np.matrix(self.U).T self.W2 = iH * Y print(‘W2 values updated…’) return H @ self.W2 – Y def svd(self, h): “”” Compute the Singualr Value Decomposition of a matrix H “”” H = np.matrix(h) self.U , self.S , Vt = np.linalg.svd(H, full_matrices = False) self.V = np.matrix(Vt).T print(‘SVD computed.. calulating Pseudoinverse..’) return np.matrix(self.U), np.matrix(self.S), np.matrix(self.V)
y의 이전 값을 features로 고려하지 않겠습니다.
############################################################### # TRAIN THE NETWORK AND PREDICT – Without previous values of y ############################################################### in_dim = train_windows.shape[1] -1 NN = Network(input_dim = in_dim, hidden_dim = 20, output_dim = 1) t0 = time.time() eml_residuals = NN.train(x =train_windows.iloc[:,:-1], y = train_windows.iloc[:,-1].values.reshape(-1,1)) tF = time.time() fit = NN.predict(train_windows.iloc[:,:-1]) predictions = NN.predict(test_windows.iloc[:,:-1]) eml_fit = cp.deepcopy(fit) eml_pred = cp.deepcopy(predictions) eml_residuals = eml_pred – testset.iloc[w:,-1].values.reshape(-1,1) eml_rmse = np.sqrt(np.sum(np.power(eml_residuals,2)) / len(eml_residuals)) print(‘RMSE = %.2f’ % eml_rmse) print(“Time to train %.2f” % ( tF-t0)) >>> ############################################################### # TRAIN THE NETWORK AND PREDICT – Without previous values of y ############################################################### in_dim = train_windows.shape[1] -1 NN = Network(input_dim = in_dim, hidden_dim = 20, output_dim = 1) t0 = time.time() eml_residuals = NN.train(x =train_windows.iloc[:,:-1], y = train_windows.iloc[:,-1].values.reshape(-1,1)) tF = time.time() fit = NN.predict(train_windows.iloc[:,:-1]) predictions = NN.predict(test_windows.iloc[:,:-1]) eml_fit = cp.deepcopy(fit) eml_pred = cp.deepcopy(predictions) eml_residuals = eml_pred – testset.iloc[w:,-1].values.reshape(-1,1) eml_rmse = np.sqrt(np.sum(np.power(eml_residuals,2)) / len(eml_residuals)) print(‘RMSE = %.2f’ % eml_rmse) print(“Time to train %.2f” % ( tF-t0)) >>> SVD computed.. calulating Pseudoinverse.. W2 values updated… RMSE = 3.70 Time to train 0.03
fig, ax1 = plt.subplots(nrows=1) fig.set_size_inches(40,10) ax1.plot(testset.iloc[w:,-1].values, marker = “o”, label = “actual”) # 100일간 데이터 ax1.plot(eml_pred, marker = “o”, label=”predict”) # 100일간 데이터 ax1.legend(prop={‘size’:30})
결론
우리는 어떻게 EMLs가 우리의 데이터에 굉장한 예측력을 가지는지 볼 수 있었습니다. 또한, 반응변수의 이전 값을 예측 변수로 포함시킨 결과도 훨씬 더 나빠졌습니다.
확실히, EMLs는 계속해서 탐구해야할 모델입니다. 이것은 빠르게 구현함으로써 이미 그들의 엄청난 힘을 보여주었고, 단순한 역행렬과 몇번의 조작으로 그 정확성(accuracy)을 계산할 수 있었습니다.
온라인 학습
EMLs의 절대적으로 큰 장점은 온라인 모델을 구현하기 위해 계산적으로 매우 저렴하다는 것입니다. 이 글에서는 업데이트 및 다운데이트 작업에 대한 자세한 정보를 볼 수 있습니다.
몇줄 안가서, 우리는 모델이 적응이되었다고 말할 수 있으며, 만약 예측 오차가 안정된 임계값을 초과하면, 이 특정한 데이터 지점이 SVD에 통합됩니다. 그래서 모델이 값비싼 완전한 재트레이닝을 요구하지 않습니다. 이런 방식으로 모델은 프로세스에서 일어날 수 있는 변화로 부터 적응하고 배울 수 있습니다.
4 — Gaussian Processes
가우시안 프로세스 (Gaussian Processes) 는 그러한 변수의 모든 유한한 집합이 다변량 정규 분포를 가지도록 하는 랜덤 변수의 집합이며, 이는 이들 변수의 가능한 모든 선형 조합이 정규 분포를 따른 다는 것을 의미합니다. (가우시안 프로세스는 다변량 정규 분포의 유한-차원의 일반화로 볼 수 있습니다)
GP의 분포는 모든 랜덤 변수들의 결합 분포입니다. 몇마디로 줄이자면, GPs는 보이지 않는 지점에 대한 값을 예측하는 점들 사이의 유사성을 결정하는 커널 함수를 사용합니다.
이 비디오는 CO2 수준을 예측하는 가우시안 프로세스에 대한 훌륭하고 짧은 인트로를 소개합니다.
이 책은 가우시안 프로세스에 대한 주요 가이드 입니다.
GP의 한가지 분명한 장점은 예측을 중심으로 신뢰 구간을 쉽게 형성하기에, 모든 예측치에서 표준 편차를 얻을 수 있다는 사실입니다.
모델
매우 간단한 CNN을 가져와 보겠습니다 :
####################### # CREATION OF THE MODEL ####################### from sklearn.gaussian_process import GaussianProcessRegressor as GP from sklearn.gaussian_process.kernels import ConstantKernel as C from sklearn.gaussian_process.kernels import RBF from sklearn.gaussian_process.kernels import ExpSineSquared as ES from sklearn.gaussian_process.kernels import DotProduct as DP from sklearn.gaussian_process.kernels import Matern from sklearn.gaussian_process.kernels import WhiteKernel as WK l = 2. kernels = {‘cnt’: C(constant_value=0.1), ‘rbf’: RBF(length_scale=1), ‘ex2’: ES(length_scale=1), ‘dot’: DP(sigma_0 = 0.1), ‘mat’: Matern(length_scale=1, nu=1.5), ‘whi’: WK(noise_level=0.01)} k = kernels[‘cnt’] + kernels[‘ex2’] + kernels[‘rbf’] if ‘gp’ in locals(): del gp gp = GP(kernel = k , n_restarts_optimizer = 9, normalize_y = True)
y의 이전값을 feature로 고려하지 않겠습니다.
##################################################### # TRAIN THE NETWORK AND PREDICT – Without previous y ##################################################### # Train tranX = train_windows.values[:,:-1] tranY = train_windows.values[:,-1] testX = test_windows.values[:,:-1] testY = test_windows.values[:,-1] t0 = time.time() gp.fit(train_windows.values[:,:-1], train_windows.values[:,-1]) tF = time.time() # Predict gp_y_fit = gp.predict(train_windows.values[:,:-1], return_std = False) gp_y_pred, gp_y_std = gp.predict(test_windows.iloc[:,:-1], return_std = True) gp_y_up = (gp_y_pred + 1.96 * gp_y_std).reshape(-1,) gp_y_lw = (gp_y_pred – 1.96 * gp_y_std).reshape(-1,) gp_y_pred = gp_y_pred.reshape(-1,1) # Calculating Errors gp_residuals = gp_y_pred – testset.iloc[5:,-1].values.reshape(-1,1) gp_rmse = np.sqrt(np.sum(np.power(gp_residuals,2))/ len(gp_residuals)) print(“RMSE = %f” % gp_rmse) print(“Time to train % .2f” %(tF-t0)) >>> RMSE = 1.429122 Time to train 22.79
fig, ax1 = plt.subplots(nrows=1) fig.set_size_inches(40,10) ax1.plot(testset.iloc[5:,-1].values, marker = “o”, label = “actual”) # 100일간 데이터 ax1.plot(gp_y_pred, marker = “o”, label=”predict”) # 100일간 데이터 ax1.legend(prop={‘size’:30})
결론
우리는 가우시안 프로세스가 또 다른 높은 예측력을 가진 얼마나 아름다운 접근인지 볼 수 있었습니다. 이 모델은 또한 반응 변수의 이전 값을 예측치로 가져왔을 때 결과가 더욱 나빠졌습니다.
요점은, 튜닝된 커널의 거의 무한한 조합을 가지고 놀 수 있다는 것입니다. 즉, 그들의 결합 분포가 우리의 모델에 더 잘 맞는 랜덤 변수의 조합을 찾을 수 있다는 것입니다. 나는 당신만의 커널을 시도해보고, 이 결과를 향상시키길 권합니다.
5 — Convolutional NN
아이디어는 주어진 시간에 프로세스의 상태를 이전의 값의 window가 pucture로 정의한다는 것입니다.
그래서, 우리는 “pictures”를 반응 변수에 매핑하는 패턴을 찾고자 하기 때문에 이미지 인식의 평행도 (parallelism)을 사용하고자 합니다. 우리는 우리의 timeseries.py에 새로운 함수인 WindowsToPictures()를 포함하였습니다.
이 함수는 우리가 inputs 값으로 사용하던 windows를 가져가고, 반응 변수의 각 값에 대해 모든 열의 window 길이에 대한 이전의 모든 값을 가지고 picture를 만듭니다.
만약 우리가 chatper 1에서 windows를 reshape했던 것을 기억한다면, 이번에는 windows를 평활화 시키지 않을 것입니다. 대신에, 3D 텐서의 3차원으로 쌓을 것입니다. 여기서 각각의 slice는 각각 독특한 반응 변수로 매핑될 것입니다. 여기에 설명 그림이 있습니다.
CNN에 학습될 데이터 재구조화
def WindowsToPictures( data, window_size): dataset = data w = window_size arr = np.empty((0,w,3) , int) for i in range(0,len(dataset)-w+1): chunk = dataset.iloc[i:i+w,2:5].values chunk = chunk.reshape((1,)+chunk.shape) arr = np.append(arr,chunk, axis=0) xdata = arr arr_y= np.empty((0,)) for i in range(w-1,len(dataset)): chunk = dataset.iloc[i,5] chunk = chunk.reshape((1,)+chunk.shape) arr_y = np.append(arr_y,chunk, axis=0) ydata = arr_y return xdata, ydata
xdata , ydata = WindowsToPictures(dataset,5) xdata.shape #(596.5.3) ydata.shape # (596,) xtrain = xdata[:500] ytrain = ydata[:500] xtest = xdata[500:] ytest = ydata[500:] xtrain.shape # (500,5,3) ytrain.shape # (500,) xtest.shape # (96,5,3) ytest.shape # (96,)
모델
# !pip install keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers.convolutional import Conv1D, MaxPooling1D, AveragePooling1D “”” KERAS IMPLEMENTATION “”” # Research on parameter : Dilation_Rate of the convolution if ‘model’ in locals(): del model if ‘history’ in locals(): del history model = Sequential() model.add(Conv1D(filters = 32, input_shape = (5,3), data_format = ‘channels_last’, kernel_size = 2, # strides = (1,1), activation = ‘relu’)) # model.add(MaxPooling1D(pool_size=2)) ?? # model.add(AveragePooling1D(pool_size=2)) ?? model.add(Dropout(0.2)) model.add(Conv1D(filters = 12, data_format = ‘channels_last’, kernel_size = 2, # strides = (1,1), activation = ‘relu’)) # model.add(MaxPooling1D(pool_size=2)) ?? # model.add(AveragePooling1D(pool_size=2)) ?? model.add(Dropout(0.1)) model.add(Flatten()) model.add(Dropout(0.2)) model.add(Dense(45, activation = ‘relu’)) model.add(Dense(1)) model.compile(optimizer=’adam’, loss=’mean_squared_error’) model.summary()
history = model.fit(xtrain, ytrain,epochs=500, verbose=0) plt.plot(history.history[‘loss’])
model.evaluate(xtest,ytest) >>> 3/3 [==============================] – 0s 1ms/step – loss: 7.5618 7.561756610870361
y_predict=model.predict(xtest) fig, ax1 = plt.subplots(nrows=1) fig.set_size_inches(40,10) ax1.plot(ytest, marker = “o”, label = “actual”) # 100일간 데이터 ax1.plot(y_predict, marker = “o”, label=”predict”) # 100일간 데이터 ax1.legend(prop={‘size’:30})
결론
프로세스의 이전 상태를 매 타임 스텝마다 프로세스의 picture로 보는 것은 다변량 시계열 예측을 위한 합리적인 접근방식 처럼 보입니다. 이 접근방식은 재무 시계열 예측, 온도/날씨 예측, 프로세스 변수 모니터링 등 문제의 최고 책임자에게 문제를 구조화할 수 있습니다.
나는 여전히 결과를 개선하기 위해 windows와 picture를 만드는 새로운 방법에 대해서 생각해보고 싶지만, 내가 보기엔, 우리가 다 해보고 나서 볼 수 있듯이, 결코 실제 값을 넘어서지 않는 견고한 모듈 처럼 보입니다.
나는 당신이 이를 개선하기 위해 무엇을 생각해냈는지 많이 알고싶네요!
CNN 부분은 코드가 있지않아 직접 작성해보았습니다.
여러 시계열 예측을 해본 결과 가우시안 프로세스가 가장 낮은 RMSE 값을 가져왔네요,
혹시 오역이나 문제가될 사항이 있다면 문의를 댓글로 남겨주세요!
[ 머신러닝 순한 맛 ] 시계열 데이터의 모든 것, RNN 정복하기!
반응형
사는 데 더 나은 방법을 찾아라
– 엘빈 토플러 –
코로나로 인해 가장 크게 떠오른 분야가 무엇이냐고 한다면, 저는 주식만한게 없다고 생각합니다. 우린 결국 돈을 벌고 싶고, 미래를 예측하여 주식 가격을 예측할 수 있다면 더할 나위가 없겠죠^^
이미 월가를 비롯해 주식시장의 최전방에 위치해있는 기업들은 실제로 다양한 기술을 이용하여 주식 가격의 미래를 예측하여 이를 실제로 수익과 연결시킵니다. 이번 포스팅에서는 순환 신경망 RNN(Recurrent Neural Network)에 대해 알아보겠습니다.
이 RNN은 우리가 그동안 봐왔던 대부분의 네트워크처럼 고정된 길이의 Input이 아닌 임의의 길이를 가진 시퀀스를 다룰 수 있습니다. 시퀀스의 예로는 문장, 문서, 오디오 샘플 등 가변적인 길이가 가진 것들을 예시로 들 수 있고, 이것은 자동 번역, Speech to Text 같은 자연어 처리(NLP)에 매우 유용합니다.
Recurrent Neuron and Recureent Layer
지금까지 우리가 봐온 네트워크들에서 Input이라 하면, 출력층을 향해서 한 방향으로만 흘러가는 Feed-Forward Network였습니다. 그러나 지금부터 우리가 볼 RNN은 출력으로 나온 Output이 다시 입력으로 순환하여 들어가는 연결이 있다는 점에서 기존과 차이점을 보입니다.
위 그림의 가장 왼쪽에 있는 것은 입력 $x$를 받아서 출력 $y$를 내보내고 이것을 다시 자기 자신에게 입력으로 보내는 가장 간단한 RNN입니다. 이것은 각 타임 스텝 $t$(하나의 단위 데이터가 들어올 때마다)마다 $x_{(t)}$와 이전 타임 스텝의 출력인 $y_{(t-1)}$을 입력으로 받습니다. 이때 가장 첫번째 타임 스텝에서는 이전 출력이 없기 때문에 $y_{(t-1)}$를 0으로 잡습니다.
왼쪽의 가장 간단한 RNN이 매 타임스텝마다 $x$와 $y_{(t-1)}$를 받아 $y_{(t)}$를 내보내는 과정을 시간을 축으로 하여 위 그림의 오른쪽처럼 표현할 수 있습니다. 이를 시간에 따라 네트워크를 펼쳤다라고 말합니다.(즉 동일 뉴런을 타임 스텝마다 하나로 표현한 것입니다.)
이러한 하나의 순환 뉴런 여러개가 모여 구성된 층(Layer)는 쉽게 만들 수 있습니다.
뉴런이 여러개라는 건 입력이 여러 개라는 것이기 때문에 이제 입력은 스칼라가 아닌 벡터 $x_(t)$가 되고, 이전 타임 스텝의 출력 $y_{(t)}$ 또한 벡터가 됩니다. (하나의 뉴런의 출력은 스칼라입니다)
각 순환 뉴런은 두 개의 가중치 벡터를 가집니다. 하나는 입력 벡터 $x_(t)$, 다른 하나는 이전 타임 스텝의 출력 $y_{(t)}$을 위한 것입니다. 이것들을 각각 $W_x$, $W_y$라고 하겠습니다. 그렇다면 순환 뉴런의 출력 $y_{(t)}$는 다음 식으로 계산될 수 있습니다.
$∅$는 Relu와 같은 활성화 함수입니다. 보통 RNN에서는 Relu보단 tanh 함수를 선호합니다.
여기에 더 나아가서 이번엔 입력이 벡터 단위가 아니라, 미니 배치로써 여러 벡터가 들어온다고 하면 이를 행렬 $X_{(t)}$로 만들어 출력을 한번에 계산할 수 있습니다.
$Y_{(t)}$는 $X_{(t)}$와 $Y_{(t-1)}$을 입력으로 받는 함수이고, $Y_{(t-1)}$는 $X_{(t-1)}$와 $Y_{(t-2)}$을 입력으로 받고, 다시 $Y_{(t-2)}$는 $X_{(t-2)}$와 $Y_{(t-3)}$을 입력으로 받게됩니다. 여기서 알 수 있는 점은 $Y_{(t)}$는 맨 처음 $t=0$에서부터 모든 입력을 받은 뉴런의 출력값이라는 점입니다.
Memory Cell
타임 스텝 $t$에서 뉴런의 출력은 이전 타임 스텝의 모든 입력에 대한 함수이므로 이를 일종의 메모리 형태라고 할 수 있습니다. 그래서 타임 스텝에 걸쳐 형성된 어떤 상태를 보존하는 RNN의 구성 요소를 메모리 셀 간단하게 셀이라고 부릅니다. –
하나의 순환 뉴런 Layer는 일반적으로 10 타임 스텝 내외를 학습할 수 있는 기본적인 셀이지만, 뒤에서 더욱 긴 패턴을 학습할 수 있는 강력한 셀에 대해 공부하게 됩니다.
일반적으로 타임 스텝 $t$에서의 셀의 상태 $h_{(t)}$는 $t$에서의 Input과 이전 타임 스텝의 셀 $h_{(t-1)}$에 대한 함수입니다. 타임 스텝 $t$에서의 출력 $y_{(t)}$도 이전 $h$와 현재 Input에 대한 함수이므로, 기본적인 셀의 경우 출력 $y_{(t)}$와 $h_{(t)}$는 같다고 할 수 있습니다. 하지만 모든 종류의 셀에서 그런 것은 아닙니다.
Input Sequence and Output Sequence
RNN에는 다양한 네트워크 구조가 있습니다. 크게 <(입력)-투-(출력) 네트워크>에서 입출력의 형태가 시퀀스냐, 벡터냐에 따라 구조의 이름이 결정됩니다. 시퀀스와 벡터를 나누는 기준은 간단합니다. 벡터가 여러개가 들어가거나 여러개가 나가면 시퀀스, 하나의 벡터만 들어가거나 나오면 벡터입니다.
– 시퀀스-투-시퀀스 네트워크(좌측 상단) ex) 주식가격 같은 시계열 데이터를 예측하는데 유용합니다. 최근 $0~N$ 일치의 주식 가격을 주입하면 네트워크는 하루 앞선 가격 즉 $1~N+1$일치 주식 가격을 출력해야 합니다.
– 시퀀스-투-벡터 네트워크(우측 상단) : 마지막 출력($Y_{(3)}$)을 제외한 나머지 출력을 모두 무시하는 네트워크 입니다. ex) 한 문장의 영화 리뷰가 있다고 할때, 문장을 구성하는 단어를 하나의 입력 벡터라고 생각할 수 있습니다. 이때 이 리뷰의 평점을 계산한다 할때, 각 단어(입력 벡터)가 들어갈 때마다 평점이 계산되어 나오는 것이 아니라, 모든 단어(시퀀스)가 들어간 후에 최종적인 한번의 평점(벡터)이 출력되는 것입니다.
– 벡터-투-시퀀스 네트워크 ex) 하나의 이미지(입력 벡터)를 넣어주면 이미지에 대한 설명문(문장은 단어로 구성된 시퀀스이다)으로 출력할 수 있습니다.
– (우측 하단) : 마지막은 인코더라 부르는 시퀀스-투-벡터 네트워크 뒤에 디코더라 부르는 벡터-투-시퀀스 네트워크를 연결한 구조입니다. ex) 한국말을 영어로 번역하는데 사용될 수 있습니다. 즉 한국어 문장으 주입하면 인코더는 이를 하나의 벡터 표현으로 변환하고 디코더가 이 벡터를 영어 문장으로 디코딩합니다.
이러한 인코더-디코더 모델은 시퀀스-투-시퀀스 RNN을 사용하여 한 단어씩 번역하는 것보다 훨씬 더 잘 작동합니다. 왜냐하면 RNN의 경우엔 문장의 마지막 단어가 번역의 첫번째 단어에 영향을 줄 수 있기 때문입니다. 따라서 하나의 단어가 들어올때 마다 번역해서 단어를 뽑아내는 것(RNN의 방식)이 아닌 전체 문장이 주입될 때까지 기다렸다 번역해야 더 좋은 성능을 낼 수 있습니다.(인코더-디코더 모델)
RNN 훈련하기
RNN 훈련 방식으로 타임 스텝으로 네트워크를 펼치고, 보통의 역전파(Back Propagation)을 사용하는 것인데 이를 BPTT(Backpropagation through time)이라고 합니다. 본격적으로 훈련 방식을 차례대로 살펴보겠습니다.
위 그림을 살펴보면서 이해해보겠습니다. 우선 회색 점선 화살표 방향으로 네트워크를 통과하면서 비용 함수 $C(Y_{(0)}, Y_{(1)} … Y_{(T)})$(T는 최대 타임 스텝)을 사용하여 출력 시퀀스를 평가됩니다. 이때 비용 함수는 Y_{(0)}, Y_{(1)}과 같은 일부 출력을 무시할 수 있습니다.
그 다음 비용함수의 Gradient는 짙은 회색선의 방향으로 전파되면서 모델 파라미터는 업데이트 됩니다. 이때 Gradient는 마지막 출력 $Y_{(4)}$에만 전달되어 노란색 박스 간의 수평방향으로 전달되는 것이 아니라, 비용 함수에 사용된 Y_{(2)}, Y_{(3)}, Y_{(4)}에 모두 각각 전달됩니다. 또한 각 타임 스텝마다 같은 매개변수 $W$와 $b$가 사용되기 때문에 역전파가 진행되면 모든 타임 스텝에 걸쳐 합산될 것입니다.
Time-Series Forecasting
어떤 웹사이트에서 1) 시간당 접속 사용자의 수, 2) 도시의 날짜별 온도, 3) 여러 feature를 사용하여 기업의 분기별 재정 안정성 등을 연구한다고 가정해보겠습니다. 이 경우 들어오는 Input Data는 타임 스텝마다 하나 이상의 값을 가지는 시퀀스이며 이를 Time-Series Data라고 부릅니다.
[1) 시간당 접속 사용자의 수, 2) 도시의 날짜별 온도]는 타임 스텝마다 하나의 feature를 가지므로 단변량 시계열 (univariate time series)이고, 3)기업의 분기별 재정 안정성은 회사의 수입, 부채 등의 여러 feature를 이용하므로 다변량 시계열(multiivariate time series)입니다.이런 Time-Series Data를 가지고 할 수 있는 몇가지 Task가 있는데 첫번째가 미래 예측(Forecasting)입니다. 또 하나는 기존 데이터에서 비어 있는 값을 채우는 Imputation입니다.
다음은 앞서 예시로 든 데이터와 별개의 3개의 단변량 시계열입니다. 각 타임 스텝은 50개이며, 목표는 51번째 타임 스텝의 값을 예측 하는 것입니다.
다음 코드에서 간단하게 $sin$ 곡선과 약간의 잡음으로 이뤄진 시계열 데이터를 생성해보겠습니다.
def generate_time_series(batch_size, n_steps): freq1, freq2, offsets1, offsets2 = np.random.rand(4, batch_size, 1) time = np.linspace(0, 1, n_steps) series = 0.5 * np.sin((time – offsets1) * (freq1 * 10 + 10)) # wave 1 series += 0.2 * np.sin((time – offsets2) * (freq2 * 20 + 20)) # + wave 2 series += 0.1 * (np.random.rand(batch_size, n_steps) – 0.5) # + noise return series[…, np.newaxis].astype(np.float32)
이 함수는 n_steps 길이의 시계열을 batch_size만큼 만들어냅니다. 각 시계열의 타임 스텝에는 하나의 값이 존재 즉 단변량이며 [배치 크기, 타임 스텝 수, 1]크기의 넘파이 배열을 반환합니다. 이러한 리턴 타입은 일반적으로 임의 길이의 time-series 데이터를 다룰 때 사용하며, 단변량은 dimensionallity가 1이고, 다변량은 1이상입니다.
이제 이 함수를 사용해 데이터를 train, validation, test set으로 나누겠습니다.
np.random.seed(42) n_steps = 50 series = generate_time_series(10000, n_steps + 1) X_train, y_train = series[:7000, :n_steps], series[:7000, -1] X_valid, y_valid = series[7000:9000, :n_steps], series[7000:9000, -1] X_test, y_test = series[9000:, :n_steps], series[9000:, -1]
기준 성능
본격적으로 RNN을 구현하기 전, 우리가 구현할 RNN이 잘 작동하는지 판단하기 위해서는 기준이 되는 무언가가 필요합니다. 가장 간단한건 각 시계열의 마지막 값을 그대로 예측하는 것입니다. 이를 naive forecasting이라고 부르는데 이 성능을 뛰어넘는 것이 매우 어렵스빈다. 이 경우 MSE가 0.020이 나오네요
y_pred = X_valid[:, -1] np.mean(keras.losses.mean_squared_error(y_valid, y_pred)) >> 0.020211367
또 다른 방법은 Fully Connected Network를 사용하는 것입니다. 이 네트워크는 입력마다 1차원 feature 배열을 기대하므로 Flatten Layer를 추가해줘야 합니다.
model = keras.models.Sequential([ keras.layers.Flatten(input_shape=[50, 1]), keras.layers.Dense(1) ]) model.compile(loss=”mse”, optimizer=”adam”) history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid)) model.evaluate(X_valid, y_valid) >>0.004168086685240269
0.004의 MSE의 값을 얻었는데 naive한 forecasting보다 훨씬 낫습니다.
간단한 RNN 구현하기
이제 간단한 RNN을 사용해 방금 구현한 네트워크들을 앞설 수 있는지 확인해보겠습니다.
model = keras.models.Sequential([ keras.layers.SimpleRNN(1, input_shape=[None, 1]) ]) optimizer = keras.optimizers.Adam(lr=0.005) model.compile(loss=”mse”, optimizer=optimizer) history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
위 코드가 가장 간단하게 만들 수 있는 RNN으로 하나의 뉴런을 가지는 하나의 layer로 이루어져 있습니다. 코드에서 input_shape에 None이 들어있는 이유는 RNN은 어떤 길이의 타임 스텝도 처리할 수 있기 때문에 길이를 지정해 줄 필요가 없습니다.
기본적으로 SimepleRNN Layers는 tanh를 activation function으로 사용합니다. 작동방식은 앞서 이론에서 살펴보았던 것과 완전히 동일합니다.
model.evaluate(X_valid, y_valid) >> 0.010881561785936356
우리가 구현한 RNN을 통해 얻은 0.014의 MSE는 naive forecasting보단 낫지만, 간단한 FC Layer 기반 선형 모델을 앞지르지 못합니다. 이는 선형 모델에서는 전체 타임스텝이 50개라 했을 때, 50개의 뉴런이 준비되어 각 입력을 받고 하나의 입력마다 하나의 파라미터를 가지고 편향까지 존재합니다. 최종적으로 51개의 파라미터가 있는 셈이죠.
반면 기본 RNN의 순환 뉴런은 Input과 셀 h의 차원마다 하나의 파라미터를 가지고 편향이 있습니다. 그러니 3개의 파라미터가 있는 셈인데, 선형 모델보다 파라미터 갯수가 월등히 적기 때문에 성능도 그만큼 덜 나오는 것입니다.
트렌드와 계절성
가중 이동 평균(weighted moving average)이나 자동 회귀 누적 이동 평균(ARIMA)같이 Time-Series Data를 forecasting하는 방법은 많습니다. 그런데 올바른 forecasting을 위해서 일부는 트렌드(Trend)나 계절성(Seasonality)를 제거해야 합니다. 트렌드라 하면 전체적인 데이터가 상승하거나 내려가거나 하는 추세를 의미합니다. 예를 들어 매달 10% 성장하는 추세의 웹사이트의 접속 사용자 수를 조사한다면, 시계열에서 트렌드를 삭제하고 예측한 후 최종 결과에 다시 이 트렌드를 더해야합니다.
비슷하게 매달 선크림 판매량 예측 시 여름에 특히 더 잘 팔리는 계절성을 관찰할 수 있습니다. 따라서 마찬가지로 최종 예측 후 이러한 계절성을 더해줘야합니다.
하지만 RNN을 사용하면 이런 작업이 필요 없습니다. 그만큼 RNN은 좋은 성능을 내기에 단순합니다. 더 많은 Layer를 추가하면 됩니다!
심층 RNN
RNN은 셀을 여러 층으로 쌓는 것이 일반적입니다. 이렇게 만든 것을 심층 RNN (Deep RNN)이라 부릅니다.
구현은 그저 SimpleRNN을 쌓아주면 됩니다.
model = keras.models.Sequential([ keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]), keras.layers.SimpleRNN(20, return_sequences=True), keras.layers.SimpleRNN(1) ])
이 모델의 MSE는 0.003으로 드디어 선형 모델을 이기게 되었습니다! 그러나 마지막 층을 좀 더 손볼 필요가 있어 보입니다. 단변량 시계열을 예측한다는 건 하나의 유닛이 필요하고 이는 타임 스텝마다 하나의 출력을 만들어야 한다는 뜻입니다. 하나의 유닛을 가진다는 건 h가 스칼라 값이라는 것입니다.
그런데 마지막 Layer의 h는 그리 필요하지 않습니다. 게다가 SimpleRNN Layer는 tanh 함수를 사용하여 forecasting 값이 -1과 1 사이의 범위에 놓입니다. 따라서 보통은 이런 이유로 출력층을 Dense 층으로 바꾸는데, 이를 통해 빠르면서 정확도는 거의 비슷합니다. 다만 이렇게 바꾸려면 두 번째 순환 층에 return_sequences=True를 제거해줘야합니다.
model = keras.models.Sequential([ keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]), keras.layers.SimpleRNN(20), keras.layers.Dense(10) ])
여러 타임 스텝 앞을 예측하기
지금까지는 다음 타임 스텝의 값만 예측했지만, 1스텝 앞이 아니라, 10스텝 앞의 값으로 타깃을 바꾸어 10 스텝 앞을 예측하는 것도 그리 어려운 일이 아닙니다. 하지만 1개의 값이 아니라 한번에 10개를 예측하고 싶다면 어떻게 해야할까요?
첫 번째 방법은 pre-trained model을 사용하여 다음 스텝의 값을 예측한 후 이 값을 다시 입력으로 추가해나가며 10개를 예측하는 것입니다. 코드는 다음과 같습니다.
series = generate_time_series(1, n_steps + 10) X_new, Y_new = series[:, :n_steps], series[:, n_steps:] X = X_new for step_ahead in range(10): y_pred_one = model.predict(X[:, step_ahead:])[:, np.newaxis, :] X = np.concatenate([X, y_pred_one], axis=1) Y_pred = X[:, n_steps:]
당연하지만 다음 스텝에 대한 예측이 훨씬 더 미래의 예측보다 정확합니다. 훨씬 더 미래의 예측은 오차가 누적될 수 있기 때문입니다. 어쨌든 위 방식을 적용하면 약 0.029의 MSE를 얻습니다. 성능은 비슷할지라도 task가 훨씬 어렵기 때문에 단순 비교는 어렵습니다.
두 번째 방법은 RNN을 훈련하여 다음 값 10개를 한번에 예측하는 것입니다. 시퀀스-투-벡터 모델을 사용하지만, 1개가 아닌 값 10개를 출력합니다.
series = generate_time_series(10000, n_steps + 10) X_train, Y_train = series[:7000, :n_steps], series[:7000, -10:, 0] X_valid, Y_valid = series[7000:9000, :n_steps], series[7000:9000, -10:, 0] X_test, Y_test = series[9000:, :n_steps], series[9000:, -10:, 0] model = keras.models.Sequential([ keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]), keras.layers.SimpleRNN(20), keras.layers.Dense(10) ])
이 모델의 다음 10개 스텝에 대한 MSE는 약 0.008로 선형 모델보다 훨씬 좋습니다. 다만 개선할 여지가 있는데, 마지막 타임스텝에서만 10개를 예측하도록 훈련하는게 아니라, 모든 타임 스텝에서 다음 10개를 예측하도록 모델을 훈련할 수 있습니다. 즉 시퀀스-투-벡터에서 시퀀스-투-시퀀스로 바꿀 수 있는 것입니다.(타임 스텝 0에서는 타임 스텝 1~10까지 예측을 담은 벡터를, 타임 스텝 1에서는 2~11까지의 예측을 담는 벡터를 출력합니다.)
이것의 장점은 모든 타임 스텝에서 forecasting을 진행하며 이것들에 대한 출력이 loss에 포함되면서 더 많은 오차 그레디언트가 모델로 흐르게 되고 결과적으로 안정적인 훈련과 함께 훈련 속도를 높이게 됩니다. 다음은 구현 코드입니다.
model = keras.models.Sequential([ keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]), keras.layers.SimpleRNN(20, return_sequences=True), keras.layers.TimeDistributed(keras.layers.Dense(10)) ])
시퀀스-투-시퀀스 모델로 바꾸려면 우선 모든 SimpleRNN 층의 return_sequences=True로 지정합니다. 그 다음 모든 타임 스텝 층에 Dense 층을 적용해야하는데 이를 위해 바로 TimeDistributed Layer를 사용합니다.
TimeDistributed Layer는 각 타임 스텝을 별개의 샘플처럼 다루도록 입력의 크기를 바꿉니다. ([배치 크기, 타임 스텝 수, 입력 차원] -> [배치 크기 x 타임 스텝 수, 입력 차원]) 그 다음 Dense Layer에 적용하고 마지막으로 출력 크기를 시퀀스로 되돌립니다. ([배치 크기 x 타임 스텝 수, 입력 차원] -> [배치 크기, 타임 스텝 수, 입력 차원])
def last_time_step_mse(Y_true, Y_pred): return keras.metrics.mean_squared_error(Y_true[:, -1], Y_pred[:, -1]) model.compile(loss=”mse”, optimizer=keras.optimizers.Adam(lr=0.01), metrics=[last_time_step_mse]) history = model.fit(X_train, Y_train, epochs=20, validation_data=(X_valid, Y_valid))
검증 MSE로 0.006을 얻었는데, 이는 이전 모델보다 25%나 향상된 것입니다.
다음 시간에는 좀 더 긴 시퀀스의 예측 시 사용하는 LSTM과 경량화된 모델인 GRU에 대해 공부해보겠습니다. 오늘도 읽어주셔서 감사합니다. 행복한 하루 보내시길 바랍니다 🙂
반응형
So you have finished reading the 시계열 데이터 머신 러닝 topic article, if you find this article useful, please share it. Thank you very much. See more: 시계열 데이터 머신러닝 예제, 시계열 데이터 머신러닝 전처리, 시계열 데이터 AI, LSTM 시계열 예측, 시계열 데이터 예측 알고리즘, 파이썬 시계열 머신러닝, 시계열 데이터 분석, 시계열 데이터 분류