
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me u net 구현 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://chewathai27.com/to team, along with other related topics such as: u net 구현 U-Net PyTorch custom dataset, u-net github, U-Net custom dataset, U Net pytorch GitHub, u-net pytorch, UNet Pytorch 구현, Tensorflow U-Net, unet++
Table of Contents
Semantic Segmentation을 위한 U-Net 모델 [4탄. 모델 구현] – DACON
- Article author: dacon.io
- Reviews from users: 17740
 Ratings
Ratings - Top rated: 4.2
- Lowest rated: 1
- Summary of article content: Articles about Semantic Segmentation을 위한 U-Net 모델 [4탄. 모델 구현] – DACON 의미론적 분할을 위한 U-Net 모델 시리지의 대망의 마지막 편! [4탄. 모델 구현]입니다. 좋은 실습 예제를 가지고 왔으니 한번 따라가보시면 좋을 것 … …
- Most searched keywords: Whether you are looking for Semantic Segmentation을 위한 U-Net 모델 [4탄. 모델 구현] – DACON 의미론적 분할을 위한 U-Net 모델 시리지의 대망의 마지막 편! [4탄. 모델 구현]입니다. 좋은 실습 예제를 가지고 왔으니 한번 따라가보시면 좋을 것 … 5만 AI팀이 협업하는 인공지능 플랫폼Data Science Competition, datavisualization, DataScience, DataAnalyst, DataEngineer, DataScientist, MachineLearning, deeplearning, 데이터분석, 인공지능, 머신러닝, 딥러닝, 파이썬, 코드, 공유, AI, python, 통계, 수학, 경진대회
- Table of Contents:
[Pytorch] U-Net 밑바닥부터 구현하기
- Article author: hyunlee103.tistory.com
- Reviews from users: 11391 Ratings
- Top rated: 4.1
- Lowest rated: 1
- Summary of article content: Articles about [Pytorch] U-Net 밑바닥부터 구현하기 Pytorch Architecture Practice(PAP) #1 U_Net 이번 포스팅은 파이토치로 image segmentation network 중 하나인 UNet을 구현하면서 코드를 하나씩 … …
- Most searched keywords: Whether you are looking for [Pytorch] U-Net 밑바닥부터 구현하기 Pytorch Architecture Practice(PAP) #1 U_Net 이번 포스팅은 파이토치로 image segmentation network 중 하나인 UNet을 구현하면서 코드를 하나씩 … Pytorch Architecture Practice(PAP) #1 U_Net 이번 포스팅은 파이토치로 image segmentation network 중 하나인 UNet을 구현하면서 코드를 하나씩 뜯어보겠습니다. UNet에 대한 이론은 다음 글을 참고해주세요 ..
- Table of Contents:
UNet Modeling
Dataset & Transform
Training
Tensorbord
태그
‘ML & DL’ 관련글
티스토리툴바
![[Pytorch] U-Net 밑바닥부터 구현하기](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FmE3DX%2FbtqDRNg62X9%2FLWK4L8cVCBeXiKgWirKVj1%2Fimg.png)
U-Net 실습
- Article author: velog.io
- Reviews from users: 39246 Ratings
- Top rated: 4.8
- Lowest rated: 1
- Summary of article content: Articles about U-Net 실습 이번 포스팅에서는 지난 시간에 공부한 U-Net 톺아보기에 대한 실습을 해보려고 합니다. … Github : U-Net(Semantic Segmentation.ipynb) 파일 … …
- Most searched keywords: Whether you are looking for U-Net 실습 이번 포스팅에서는 지난 시간에 공부한 U-Net 톺아보기에 대한 실습을 해보려고 합니다. … Github : U-Net(Semantic Segmentation.ipynb) 파일 … 이번 포스팅에서는 지난 시간에 공부한 U-Net 톺아보기에 대한 실습을 해보려고 합니다. 사실 실습이라기 보다는 링크의 내용을 분석해보는 것에 불과합니다. 실습에 관련된 대부분의 내용(소스코드 포함)은 아래의 사이트를 바탕으로 작성했음을 미리 알려드립니다. 또한, 데이
- Table of Contents:
Deep Learning architecture
Cityscape Dataset
Step 1 모델 설계
Step 2 모델 학습
Step 3 모델 평가하기
Step 4 IOU Score
[논문구현하기] U-net 구현하기
- Article author: koreapy.tistory.com
- Reviews from users: 28416 Ratings
- Top rated: 4.9
- Lowest rated: 1
- Summary of article content: Articles about [논문구현하기] U-net 구현하기 GitHub – milesial/Pytorch-UNet: PyTorch implementation of the U-Net for image semantic segmentation with high quality images. …
- Most searched keywords: Whether you are looking for [논문구현하기] U-net 구현하기 GitHub – milesial/Pytorch-UNet: PyTorch implementation of the U-Net for image semantic segmentation with high quality images. https://paperswithcode.com/paper/u-net-convolutional-networks-for-biomedical https://github.com/milesial/Pytorch-UNet GitHub – milesial/Pytorch-UNet: PyTorch implementation of the U-Net for image se..
- Table of Contents:
py
[논문구현하기] U-net 구현하기 본문![[논문구현하기] U-net 구현하기](https://t1.daumcdn.net/tistory_admin/static/images/openGraph/opengraph.png)
U-net 실제 구현 코드 – Go Lab
- Article author: machinelearningkorea.com
- Reviews from users: 27895 Ratings
- Top rated: 3.5
- Lowest rated: 1
- Summary of article content: Articles about U-net 실제 구현 코드 – Go Lab U-net 실제 구현 코드 … 딥러닝연습 (영상이미지 판독) – 삼성 SDS 스터디 그룹 진행용; Unet으로 병변부위를 예측하는 연습을 합니다. …
- Most searched keywords: Whether you are looking for U-net 실제 구현 코드 – Go Lab U-net 실제 구현 코드 … 딥러닝연습 (영상이미지 판독) – 삼성 SDS 스터디 그룹 진행용; Unet으로 병변부위를 예측하는 연습을 합니다.
- Table of Contents:
Go Lab
데이터 로드¶
이미지 로딩¶
U-net 모델 만들기¶
글 탐색
One thought on “U-net 실제 구현 코드”
[U-Net] U-Net 구조
- Article author: pasus.tistory.com
- Reviews from users: 8781 Ratings
- Top rated: 4.7
- Lowest rated: 1
- Summary of article content: Articles about [U-Net] U-Net 구조 다음 코드는 EncoderBlock을 구현한 것이다. “”” Encoder Block “”” EncoderBlock(tf.keras.layers.Layer) … …
- Most searched keywords: Whether you are looking for [U-Net] U-Net 구조 다음 코드는 EncoderBlock을 구현한 것이다. “”” Encoder Block “”” EncoderBlock(tf.keras.layers.Layer) … 이미지 세그멘테이션(image segmentation)은 이미지의 모든 픽셀이 어떤 카테고리(예를 들면 자동차, 사람, 도로 등)에 속하는지 분류하는 것을 말한다. 이미지 전체에 대해 단일 카테고리를 예측하는 이미지 분류..
- Table of Contents:
태그
관련글
댓글0
전체 방문자
티스토리툴바
![[U-Net] U-Net 구조](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FVMF8W%2FbtrBOwarxLa%2F7sB5rutlMSBXGqOCymQmJk%2Fimg.png)
2. Segmentation 모델 구현 (feat. UNet) :: Time Traveler
- Article author: 89douner.tistory.com
- Reviews from users: 3530 Ratings
- Top rated: 4.8
- Lowest rated: 1
- Summary of article content: Articles about 2. Segmentation 모델 구현 (feat. UNet) :: Time Traveler 안녕하세요. 이번 글에서는 pytorch를 이용해 UNet 모델을 구현한 code를 설명할 예정입니다. 다양한 딥러닝 기반 segmentation 모델이 있지만, UNet … …
- Most searched keywords: Whether you are looking for 2. Segmentation 모델 구현 (feat. UNet) :: Time Traveler 안녕하세요. 이번 글에서는 pytorch를 이용해 UNet 모델을 구현한 code를 설명할 예정입니다. 다양한 딥러닝 기반 segmentation 모델이 있지만, UNet … 안녕하세요. 이번 글에서는 pytorch를 이용해 UNet 모델을 구현한 code를 설명할 예정입니다. 다양한 딥러닝 기반 segmentation 모델이 있지만, UNet 모델이 가장 기본이 되기 때문에 다루었습니다. 소개해 드릴 U..#Interest: World History (The past) #Work: Deep Learning (The future) #Hobby: Music, Sports
- Table of Contents:

[Deep Neural Network] U-net 구조와 code 구현하기!
- Article author: csm-kr.tistory.com
- Reviews from users: 5307 Ratings
- Top rated: 4.1
- Lowest rated: 1
- Summary of article content: Articles about [Deep Neural Network] U-net 구조와 code 구현하기! 오늘은 u-net 구조와 unet 을 활용한 colorization 에 대하여 알아보겠습니다. U-net. U-net 이 처음에 제안된 논문은 medical 분야인 MICCAI 2015 학회 … …
- Most searched keywords: Whether you are looking for [Deep Neural Network] U-net 구조와 code 구현하기! 오늘은 u-net 구조와 unet 을 활용한 colorization 에 대하여 알아보겠습니다. U-net. U-net 이 처음에 제안된 논문은 medical 분야인 MICCAI 2015 학회 … 안녕하세요 pulluper 입니다. 🙂 오늘은 u-net 구조와 unet 을 활용한 colorization 에 대하여 알아보겠습니다. U-net U-net 이 처음에 제안된 논문은 medical 분야인 MICCAI 2015 학회에서 발표 되었으며 “U-Net:..
- Table of Contents:
태그
관련글
댓글0
최근글
인기글
최근댓글
태그
전체 방문자
티스토리툴바
![[Deep Neural Network] U-net 구조와 code 구현하기!](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbu1jbB%2Fbtq3U6J6aNX%2FS6V5kfqDrpWgUD6sBIPdM1%2Fimg.png)
U-Net 구현으로 배우는 딥러닝 논문 구현 with TensorFlow 2.0 – 딥러닝 의료영상 분석 – 인프런 | 강의
- Article author: www.inflearn.com
- Reviews from users: 20011 Ratings
- Top rated: 3.4
- Lowest rated: 1
- Summary of article content: Articles about U-Net 구현으로 배우는 딥러닝 논문 구현 with TensorFlow 2.0 – 딥러닝 의료영상 분석 – 인프런 | 강의 U-Net 논문을 TensorFlow 2.0을 이용해서 밑바닥부터 구현해보며 딥러닝 논문 구현 능력을 배울 수 있는 강의입니다., – 강의 소개 | 인프런… …
- Most searched keywords: Whether you are looking for U-Net 구현으로 배우는 딥러닝 논문 구현 with TensorFlow 2.0 – 딥러닝 의료영상 분석 – 인프런 | 강의 U-Net 논문을 TensorFlow 2.0을 이용해서 밑바닥부터 구현해보며 딥러닝 논문 구현 능력을 배울 수 있는 강의입니다., – 강의 소개 | 인프런… U-Net 논문을 TensorFlow 2.0을 이용해서 밑바닥부터 구현해보며 딥러닝 논문 구현 능력을 배울 수 있는 강의입니다., – 강의 소개 | 인프런…
- Table of Contents:
현업 실무자에게 배우는 Kaggle 머신러닝 입문 – ML 엔지니어 실무 꿀팁
AI로 돈 버는 법 – 사례로 알아보는 AI Transformation
예제로 배우는 딥러닝 자연어 처리 입문 NLP with TensorFlow – RNN부터 BERT까지
비전공자입문자를 위한 Data Science(DS)와 AI 학습 & 취업 가이드
딥러닝 CNN 완벽 가이드 – Fundamental 편
비전공자를 위한 진짜 입문 올인원 개발 클래스
프로그래밍 시작하기 파이썬 입문 (Inflearn Original)
머신러닝딥러닝으로 이어지는 선형대수
See more articles in the same category here: Chewathai27.com/to/blog.
[Pytorch] U-Net 밑바닥부터 구현하기
Pytorch Architecture Practice(PAP) #1 U_Net
이번 포스팅은 파이토치로 image segmentation network 중 하나인 UNet을 구현하면서 코드를 하나씩 뜯어보겠습니다. UNet에 대한 이론은 다음 글을 참고해주세요 Wave U-Net . 구현에 사용할 데이터는 ISBI 2012 em image segmentation(http://brainiac2.mit.edu/isbi_challenge/home) 대회에서 사용한 이미지 데이터 셋을 사용했습니다.
전체 코드는 https://github.com/HyunLee103/Pytorch_practice/tree/master/Architecture/UNet 에 있으며, 한요섭 님의 코드를 참고하였습니다.
글에서는 코드 일부를 뜯어보며 파이토치가 어떻게 동작하는지 알아보겠습니다.
UNet Modeling
출처 : http://brainiac2.mit.edu/isbi_challenge/home
데이터 셋은 위 그림과 같이 input과 각 input에 해당하는 label이 총 30세트가 있다. 목적은 input data로 label에 가깝게 image segmentation하는 모델을 만드는 것이다.
import numpy as np import os from PIL import Image import matplotlib.pyplot as plt import torch import torch.nn as nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from torchvision import transforms,datasets
# ‘nn.Module’ 이라는 파이토치 base class를 상속받아서 # 사용자 정의 network 만들기 # UNet class가 instance로 할당될때 초기화되는 함수 __init__, 이 함수에서 # 네트워크에 사용될 layer들을 전부 self.net으로 선언 class UNet(nn.Module): def __init__(self): # super(subclass, self) : subclass에서 base class의 내용을 오버라이드해서 사용하고 싶을 때 super(UNet, self).__init__() # 네트워크에서 반복적으로 사용되는 Conv + BatchNorm + Relu를 합쳐서 하나의 함수로 정의 def CBR2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True): layers = [] layers += [nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias)] layers += [nn.BatchNorm2d(num_features=out_channels)] layers += [nn.ReLU()] cbr = nn.Sequential(*layers) # *으로 list unpacking return cbr # Contracting path self.enc1_1 = CBR2d(in_channels=1, out_channels=64) self.enc1_2 = CBR2d(in_channels=64, out_channels=64) self.pool1 = nn.MaxPool2d(kernel_size=2) self.enc2_1 = CBR2d(in_channels=64, out_channels=128) self.enc2_2 = CBR2d(in_channels=128, out_channels=128) self.pool2 = nn.MaxPool2d(kernel_size=2) # Expansive path self.dec5_1 = CBR2d(in_channels=1024, out_channels=512) self.unpool4 = nn.ConvTranspose2d(in_channels=512, out_channels=512, kernel_size=2, stride=2, padding=0, bias=True) self.dec4_2 = CBR2d(in_channels=2 * 512, out_channels=512) self.dec4_1 = CBR2d(in_channels=512, out_channels=256) self.unpool3 = nn.ConvTranspose2d(in_channels=256, out_channels=256, kernel_size=2, stride=2, padding=0, bias=True) # __init__ 함수에서 선언한 layer들 연결해서 data propa flow 만들기 def forward(self, x): enc1_1 = self.enc1_1(x) enc1_2 = self.enc1_2(enc1_1) pool1 = self.pool1(enc1_2) 생략 unpool1 = self.unpool1(dec2_1) cat1 = torch.cat((unpool1, enc1_2), dim=1) dec1_2 = self.dec1_2(cat1) dec1_1 = self.dec1_1(dec1_2) out = self.fc(dec1_1) return out # data가 모든 layer를 거쳐서 나온 output 값
Dataset & Transform
데이터가 흘러갈 네트워크를 선언했으니 데이터를 잘 처리해서 네트워크에 흘려보내주면 된다. 파이토치는 데이터를 불러오기 변환하는 과정을 Dataset class와 Transform class로 구현한다. 먼저 Dataset 부터 보자.
class Dataset(torch.utils.data.Dataset): # torch.utils.data.Dataset 이라는 파이토치 base class를 상속받아 # 그 method인 __len__(), __getitem__()을 오버라이딩 해줘서 # 사용자 정의 Dataset class를 선언한다 def __init__(self, data_dir, transform=None): self.data_dir = data_dir self.transform = transform lst_data = os.listdir(self.data_dir) # 문자열 검사해서 ‘label’이 있으면 True # 문자열 검사해서 ‘input’이 있으면 True lst_label = [f for f in lst_data if f.startswith(‘label’)] lst_input = [f for f in lst_data if f.startswith(‘input’)] lst_label.sort() lst_input.sort() self.lst_label = lst_label self.lst_input = lst_input def __len__(self): return len(self.lst_label) # 여기가 데이터 load하는 파트 def __getitem__(self, index): label = np.load(os.path.join(self.data_dir, self.lst_label[index])) inputs = np.load(os.path.join(self.data_dir, self.lst_input[index])) # normalize, 이미지는 0~255 값을 가지고 있어 이를 0~1사이로 scaling label = label/255.0 inputs = inputs/255.0 label = label.astype(np.float32) inputs = inputs.astype(np.float32) # 인풋 데이터 차원이 2이면, 채널 축을 추가해줘야한다. # 파이토치 인풋은 (batch, 채널, 행, 열) if label.ndim == 2: label = label[:,:,np.newaxis] if inputs.ndim == 2: inputs = inputs[:,:,np.newaxis] data = {‘input’:inputs, ‘label’:label} if self.transform: data = self.transform(data) # transform에 할당된 class 들이 호출되면서 __call__ 함수 실행 return data
다음은 Transform인데, 이 부분은 휴리스틱하게 원하는 전처리를 해주면 된다. 일반적으로 데이터가 numpy 형태라면 tensor로 바꿔주고, 이미지의 경우 Flip(방향 뒤집기)을 통해 data augumentation 효과를 주기도 한다. 이 예제에서 데이터는 np 형태이고 이미지이므로 언급한 두 변환에 더해 정규화도 취해보자.
class ToTensor(object): def __call__(self, data): label, input = data[‘label’], data[‘input’] # numpy와 tensor의 배열 차원 순서가 다르다. # numpy : (행, 열, 채널) # tensor : (채널, 행, 열) # 따라서 위 순서에 맞춰 transpose label = label.transpose((2, 0, 1)).astype(np.float32) input = input.transpose((2, 0, 1)).astype(np.float32) # 이후 np를 tensor로 바꾸는 코드는 다음과 같이 간단하다. data = {‘label’: torch.from_numpy(label), ‘input’: torch.from_numpy(input)} return data
Training
## 하이퍼 파라미터 설정 lr = 1e-3 batch_size = 4 num_epoch = 100 data_dir = ‘/content/drive/My Drive/Colab Notebooks/파이토치/Architecture practice/UNet/data’ ckpt_dir = ‘/content/drive/My Drive/Colab Notebooks/파이토치/Architecture practice/UNet/checkpoint’ log_dir = ‘/content/drive/My Drive/Colab Notebooks/파이토치/Architecture practice/UNet/log’ device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’) # transform 적용해서 데이터 셋 불러오기 transform = transforms.Compose([Normalization(mean=0.5, std=0.5), RandomFlip(), ToTensor()]) dataset_train = Dataset(data_dir=os.path.join(data_dir,’train’),transform=transform) # 불러온 데이터셋, 배치 size줘서 DataLoader 해주기 loader_train = DataLoader(dataset_train, batch_size = batch_size, shuffle=True) # val set도 동일하게 진행 dataset_val = Dataset(data_dir=os.path.join(data_dir,’val’),transform = transform) loader_val = DataLoader(dataset_val, batch_size=batch_size , shuffle=True) # 네트워크 불러오기 net = UNet().to(device) # device : cpu or gpu # loss 정의 fn_loss = nn.BCEWithLogitsLoss().to(device) # Optimizer 정의 optim = torch.optim.Adam(net.parameters(), lr = lr ) # 기타 variables 설정 num_train = len(dataset_train) num_val = len(dataset_val) num_train_for_epoch = np.ceil(num_train/batch_size) # np.ceil : 소수점 반올림 num_val_for_epoch = np.ceil(num_val/batch_size) # 기타 function 설정 fn_tonumpy = lambda x : x.to(‘cpu’).detach().numpy().transpose(0,2,3,1) # device 위에 올라간 텐서를 detach 한 뒤 numpy로 변환 fn_denorm = lambda x, mean, std : (x * std) + mean fn_classifier = lambda x : 1.0 * (x > 0.5) # threshold 0.5 기준으로 indicator function으로 classifier 구현 # Tensorbord writer_train = SummaryWriter(log_dir=os.path.join(log_dir,’train’)) writer_val = SummaryWriter(log_dir = os.path.join(log_dir,’val’))
# 네트워크 저장하기 # train을 마친 네트워크 저장 # net : 네트워크 파라미터, optim 두개를 dict 형태로 저장 def save(ckpt_dir,net,optim,epoch): if not os.path.exists(ckpt_dir): os.makedirs(ckpt_dir) torch.save({‘net’:net.state_dict(),’optim’:optim.state_dict()},’%s/model_epoch%d.pth’%(ckpt_dir,epoch)) # 네트워크 불러오기 def load(ckpt_dir,net,optim): if not os.path.exists(ckpt_dir): # 저장된 네트워크가 없다면 인풋을 그대로 반환 epoch = 0 return net, optim, epoch ckpt_lst = os.listdir(ckpt_dir) # ckpt_dir 아래 있는 모든 파일 리스트를 받아온다 ckpt_lst.sort(key = lambda f : int(”.join(filter(str,isdigit,f)))) dict_model = torch.load(‘%s/%s’ % (ckpt_dir,ckpt_lst[-1])) net.load_state_dict(dict_model[‘net’]) optim.load_state_dict(dict_model[‘optim’]) epoch = int(ckpt_lst[-1].split(‘epoch’)[1].split(‘.pth’)[0]) return net,optim,epoch # 네트워크 학습시키기 start_epoch = 0 net, optim, start_epoch = load(ckpt_dir = ckpt_dir, net = net, optim = optim) # 저장된 네트워크 불러오기 for epoch in range(start_epoch+1,num_epoch +1): net.train() loss_arr = [] for batch, data in enumerate(loader_train,1): # 1은 뭐니 > index start point # forward label = data[‘label’].to(device) # 데이터 device로 올리기 inputs = data[‘input’].to(device) output = net(inputs) # backward optim.zero_grad() # gradient 초기화 loss = fn_loss(output, label) # output과 label 사이의 loss 계산 loss.backward() # gradient backpropagation optim.step() # backpropa 된 gradient를 이용해서 각 layer의 parameters update # save loss loss_arr += [loss.item()] # tensorbord에 결과값들 저정하기 label = fn_tonumpy(label) inputs = fn_tonumpy(fn_denorm(inputs,0.5,0.5)) output = fn_tonumpy(fn_classifier(output)) writer_train.add_image(‘label’, label, num_train_for_epoch * (epoch – 1) + batch, dataformats=’NHWC’) writer_train.add_image(‘input’, inputs, num_train_for_epoch * (epoch – 1) + batch, dataformats=’NHWC’) writer_train.add_image(‘output’, output, num_train_for_epoch * (epoch – 1) + batch, dataformats=’NHWC’) writer_train.add_scalar(‘loss’, np.mean(loss_arr), epoch) # validation with torch.no_grad(): # validation 이기 때문에 backpropa 진행 x, 학습된 네트워크가 정답과 얼마나 가까운지 loss만 계산 net.eval() # 네트워크를 evaluation 용으로 선언 loss_arr = [] for batch, data in enumerate(loader_val,1): # forward label = data[‘label’].to(device) inputs = data[‘input’].to(device) output = net(inputs) # loss loss = fn_loss(output,label) loss_arr += [loss.item()] print(‘valid : epoch %04d / %04d | Batch %04d \ %04d | Loss %04d’%(epoch,num_epoch,batch,num_val_for_epoch,np.mean(loss_arr))) # Tensorboard 저장하기 label = fn_tonumpy(label) inputs = fn_tonumpy(fn_denorm(inputs, mean=0.5, std=0.5)) output = fn_tonumpy(fn_classifier(output)) writer_val.add_image(‘label’, label, num_val_for_epoch * (epoch – 1) + batch, dataformats=’NHWC’) writer_val.add_image(‘input’, inputs, num_val_for_epoch * (epoch – 1) + batch, dataformats=’NHWC’) writer_val.add_image(‘output’, output, num_val_for_epoch * (epoch – 1) + batch, dataformats=’NHWC’) writer_val.add_scalar(‘loss’, np.mean(loss_arr), epoch) # epoch이 끝날때 마다 네트워크 저장 save(ckpt_dir=ckpt_dir, net = net, optim = optim, epoch = epoch) writer_train.close() writer_val.close()
Tensorbord
blue : val set, orange : train set
reference
한요섭 님 https://www.youtube.com/watch?v=fWmRYmjF-Xw&t=283s
U-Net 실습
이번 포스팅에서는 지난 시간에 공부한 U-Net 톺아보기에 대한 실습을 해보려고 합니다. 사실 실습이라기 보다는 링크의 내용을 분석해보는 것에 불과합니다. 실습에 관련된 대부분의 내용(소스코드 포함)은 아래의 사이트를 바탕으로 작성했음을 미리 알려드립니다. 또한, 데이터셋도 아래 링크에서 다운받으실 수 있습니다.
[Semantic Segmentation in Self-driving Cars] [Source Code] [Dataset]기존의 코드에서 제가 따로 추가하거나 수정한 소스코드는, 아래의 깃허브에서 다운받으실 수 있습니다.
Github : U-Net(Semantic Segmentation.ipynb) 파일
Cityscape Dataset
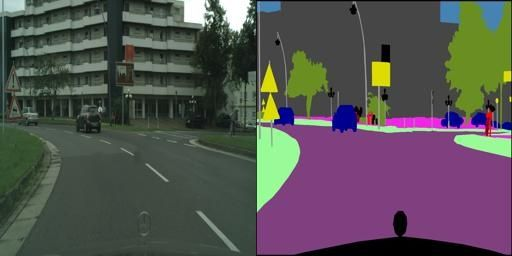
어떤 데이터를 바탕으로 학습을 하는지를 확인해보기 위해, 데이터셋 중 한 개의 이미지만을 확인해봅니다.
이미지를 확인해보면 256(세로, 행) x 512(가로, 열)의 픽셀로 구성되어 있는 것을 확인할 수 있습니다. 위의 사진에서 왼쪽의 이미지는 실제 이미지(original image)를, 오른쪽 이미지는 labeled 이미지를 나타냅니다. Cityscape Dataset은 2975개의 training 이미지 파일과 500개의 validation 이미지 파일로 이루어져 있습니다. 해당 데이터셋에 대한 자세한 설명은 다운받은 사이트에서 확인할 수 있습니다.
Step 1. 모델 설계
1.1 라이브러리 불러오기
import os from PIL import Image import numpy as np import pandas as pd import matplotlib . pyplot as plt from sklearn . cluster import KMeans import torch import torch . nn as nn import torch . nn . functional as F import torch . optim as optim from torch . utils . data import Dataset , DataLoader from torchvision import transforms from tqdm . notebook import tqdm
모델 설계하는데 필요한 라이브러리를 불러옵니다.
PIL 라이브러리
1.2 GPU 설정하기
device = “cuda:0” if torch . cuda . is_available ( ) else “cpu” device = torch . device ( device ) print ( device )
1.3 파일 시스템
root_path = ‘~/archive/ityscapes_data/’ data_dir = root_path train_dir = os . path . join ( data_dir , “train” ) val_dir = os . path . join ( data_dir , “val” ) train_fns = os . listdir ( train_dir ) val_fns = os . listdir ( val_dir ) print ( len ( train_fns ) , len ( val_fns ) )
위의 결과를 출력해보면 아래와 같은 결과를 얻을 수 있습니다.
2975 500
즉, train_fns의 길이는 2975이며 val_fns의 길이는 500입니다. 이는 데이터셋인 Cityscape Dataset의 학습(train) 및 검증(validation) 데이터와 일치하는 것을 확인할 수 있습니다.
1.4 샘플 이미지 검색
경로를 지정했으므로 이제 이 경로를 사용하여 샘플 이미지를 불러오도록 하겠습니다. 이 과정은 생략해도 되지만 불러오는 과정이 원활하게 동작하는지 확인하기 위해 실습해보도록 하겠습니다.
sample_image_fp = os . path . join ( train_dir , train_fns [ 0 ] ) sample_image = Image . open ( sample_image_fp ) . convert ( “RGB” ) plt . imshow ( sample_image ) plt . show ( )
plt.show() vs plt.imshow()
위의 소스코드를 실행하면 아래의 이미지가 출력됩니다.
1.5 Output Label 정의하기
num_items = 1000 color_array = np . random . choice ( range ( 256 ) , 3 * num_items ) . reshape ( – 1 , 3 ) print ( color_array . shape )
출력결과
(1000, 3)
num_classes = 10 label_model = KMeans ( n_clusters = num_classes ) label_model . fit ( color_array )
K-means clustering
label_model.fit(color_array)
def split_image ( image ) : image = np . array ( image ) cityscape , label = image [ : , : 256 , : ] , image [ : , 256 : , : ] return cityscape , label
cityscape , label = split_image ( sample_image ) label_class = label_model . predict ( label . reshape ( – 1 , 3 ) ) . reshape ( 256 , 256 ) fig , axes = plt . subplots ( 1 , 3 , figsize = ( 15 , 5 ) ) axes [ 0 ] . imshow ( cityscape ) axes [ 1 ] . imshow ( label ) axes [ 2 ] . imshow ( label_class ) plt . show ( )
label_model.predict( )
plt.subplots( )
1.5.1 label_model.predict( ) 궁금한 것
label_class = label_model . predict ( label . reshape ( – 1 , 1 ) ) . reshape ( 256 , 256 )
KMeans의 predict 메소드의 경우 3개의 feature를 입력으로 받으므로 reshape(-1, 3)을 해주어야 정상적으로 동작함. ValueError: X has 1 features, but KMeans is expecting 3 features as input.
print ( label . shape ) print ( label . reshape ( – 1 , 3 ) . shape ) print ( label_model . predict ( label . reshape ( – 1 , 3 ) ) . shape print ( label_class . shape )
위의 출력 결과는 각각 아래와 같습니다. (256, 256, 3) (65536, 3) (65536,) (256, 256)
1.6 데이터셋 정의하기
class CityscapeDataset ( Dataset ) : def __init__ ( self , image_dir , label_model ) : self . image_dir = image_dir self . image_fns = os . listdir ( image_dir ) self . label_model = label_model def __len__ ( self ) : return len ( self . image_fns ) def __getitem__ ( self , index ) : image_fn = self . image_fns [ index ] image_fp = os . path . join ( self . image_dir , image_fn ) image = Image . open ( image_fp ) image = np . array ( image ) cityscape , label = self . split_image ( image ) label_class = self . label_model . predict ( label . reshape ( – 1 , 3 ) ) . reshape ( 256 , 256 ) label_class = torch . Tensor ( label_class ) . long ( ) cityscape = self . transform ( cityscape ) return cityscape , label_class def split_image ( self , image ) : image = np . array ( image ) cityscape , label = image [ : , : 256 , : ] , image [ : , 256 : , : ] return cityscape , label def transform ( self , image ) : transform_ops = transforms . Compose ( [ transforms . ToTensor ( ) , transforms . Normalize ( mean = ( 0.485 , 0.56 , 0.406 ) , std = ( 0.229 , 0.224 , 0.225 ) ) ] ) return transform_ops ( image )
Tensor.long()
dataset = CityscapeDataset ( train_dir , label_model ) print ( len ( dataset ) ) cityscape , label_class = dataset [ 0 ] print ( cityscape . shape ) print ( label_class . shape )
# 출력 결과 2975 torch.Size([3, 256, 256]) torch.Size([256, 256])
위의 출력 결과를 통해, 학습 데이터가 2975개 있다는 것을 다시 한번 확인할 수 있습니다. 또한, cityscape과 label_class의 shape도 알 수 있습니다. cityscape의 경우 transforms.ToTensor()를 통과하여 [3, 256, 256]의 텐서 형태를 가지게 되는 것을 확인할 수 있습니다.
1.7 U-Net 모델 정의하기
이전 포스팅에서 다룬 U-Net 모델을 사용하여 Sementic Segmentation을 진행하겠습니다. 아래의 사진을 바탕으로 U-Net 모델을 만듭니다.
class UNet ( nn . Module ) : def __init__ ( self , num_classes ) : super ( UNet , self ) . __init__ ( ) self . num_classes = num_classes self . contracting_11 = self . conv_block ( in_channels = 3 , out_channels = 64 ) self . contracting_12 = nn . MaxPool2d ( kernel_size = 2 , stride = 2 ) self . contracting_21 = self . conv_block ( in_channels = 64 , out_channels = 128 ) self . contracting_22 = nn . MaxPool2d ( kernel_size = 2 , stride = 2 ) self . contracting_31 = self . conv_block ( in_channels = 128 , out_channels = 256 ) self . contracting_32 = nn . MaxPool2d ( kernel_size = 2 , stride = 2 ) self . contracting_41 = self . conv_block ( in_channels = 256 , out_channels = 512 ) self . contracting_42 = nn . MaxPool2d ( kernel_size = 2 , stride = 2 ) self . middle = self . conv_block ( in_channels = 512 , out_channels = 1024 ) self . expansive_11 = nn . ConvTranspose2d ( in_channels = 1024 , out_channels = 512 , kernel_size = 3 , stride = 2 , padding = 1 , output_padding = 1 ) self . expansive_12 = self . conv_block ( in_channels = 1024 , out_channels = 512 ) self . expansive_21 = nn . ConvTranspose2d ( in_channels = 512 , out_channels = 256 , kernel_size = 3 , stride = 2 , padding = 1 , output_padding = 1 ) self . expansive_22 = self . conv_block ( in_channels = 512 , out_channels = 256 ) self . expansive_31 = nn . ConvTranspose2d ( in_channels = 256 , out_channels = 128 , kernel_size = 3 , stride = 2 , padding = 1 , output_padding = 1 ) self . expansive_32 = self . conv_block ( in_channels = 256 , out_channels = 128 ) self . expansive_41 = nn . ConvTranspose2d ( in_channels = 128 , out_channels = 64 , kernel_size = 3 , stride = 2 , padding = 1 , output_padding = 1 ) self . expansive_42 = self . conv_block ( in_channels = 128 , out_channels = 64 ) self . output = nn . Conv2d ( in_channels = 64 , out_channels = num_classes , kernel_size = 3 , stride = 1 , padding = 1 ) def conv_block ( self , in_channels , out_channels ) : block = nn . Sequential ( nn . Conv2d ( in_channels = in_channels , out_channels = out_channels , kernel_size = 3 , stride = 1 , padding = 1 ) , nn . ReLU ( ) , nn . BatchNorm2d ( num_features = out_channels ) , nn . Conv2d ( in_channels = out_channels , out_channels = out_channels , kernel_size = 3 , stride = 1 , padding = 1 ) , nn . ReLU ( ) , nn . BatchNorm2d ( num_features = out_channels ) ) return block def forward ( self , X ) : contracting_11_out = self . contracting_11 ( X ) contracting_12_out = self . contracting_12 ( contracting_11_out ) contracting_21_out = self . contracting_21 ( contracting_12_out ) contracting_22_out = self . contracting_22 ( contracting_21_out ) contracting_31_out = self . contracting_31 ( contracting_22_out ) contracting_32_out = self . contracting_32 ( contracting_31_out ) contracting_41_out = self . contracting_41 ( contracting_32_out ) contracting_42_out = self . contracting_42 ( contracting_41_out ) middle_out = self . middle ( contracting_42_out ) expansive_11_out = self . expansive_11 ( middle_out ) expansive_12_out = self . expansive_12 ( torch . cat ( ( expansive_11_out , contracting_41_out ) , dim = 1 ) ) expansive_21_out = self . expansive_21 ( expansive_12_out ) expansive_22_out = self . expansive_22 ( torch . cat ( ( expansive_21_out , contracting_31_out ) , dim = 1 ) ) expansive_31_out = self . expansive_31 ( expansive_22_out ) expansive_32_out = self . expansive_32 ( torch . cat ( ( expansive_31_out , contracting_21_out ) , dim = 1 ) ) expansive_41_out = self . expansive_41 ( expansive_32_out ) expansive_42_out = self . expansive_42 ( torch . cat ( ( expansive_41_out , contracting_11_out ) , dim = 1 ) ) output_out = self . output ( expansive_42_out ) return output_out
super(UNet, self).init()
nn.Module
model = UNet ( num_classes = num_classes )
data_loader = DataLoader ( dataset , batch_size = 4 ) print ( len ( dataset ) , len ( data_loader ) ) X , Y = iter ( data_loader ) . next ( ) print ( X . shape ) print ( Y . shape )
# 출력결과 2975 744 torch.Size([4, 3, 256, 256]) torch.Size([4, 256, 256])
Y_pred = model ( X ) print ( Y_pred . shape )
torch.Size([4, 10, 256, 256])
원래 U-Net 논문에는 no padding이지만 링크의 저자는 padding을 추가해주었습니다. 또한 논문에서는 1×1 convolution이 마지막 레이어에 존재하지만 이 포스팅에서는 존재하지 않습니다. 추측하건대 논문의 이미지 크기와, 우리가 인식하려는 이미지의 크기가 다르기 때문에 약간의 변형을 해준 것 같습니다.
1.7.1 U-Net 모델 코드 수정
논문에서 마지막 레이어에 1×1 convolution을 추가하였기 때문에, 궁금하여 이전의 소스코드에서 1×1 conv. layer를 추가해보았습니다. 수정한 코드는 아래와 같습니다.
class UNet ( nn . Module ) : def __init__ ( self , num_classes ) : super ( UNet , self ) . __init__ ( ) self . num_classes = num_classes self . contracting_11 = self . conv_block ( in_channels = 3 , out_channels = 64 ) self . contracting_12 = nn . MaxPool2d ( kernel_size = 2 , stride = 2 ) self . contracting_21 = self . conv_block ( in_channels = 64 , out_channels = 128 ) self . contracting_22 = nn . MaxPool2d ( kernel_size = 2 , stride = 2 ) self . contracting_31 = self . conv_block ( in_channels = 128 , out_channels = 256 ) self . contracting_32 = nn . MaxPool2d ( kernel_size = 2 , stride = 2 ) self . contracting_41 = self . conv_block ( in_channels = 256 , out_channels = 512 ) self . contracting_42 = nn . MaxPool2d ( kernel_size = 2 , stride = 2 ) self . middle = self . conv_block ( in_channels = 512 , out_channels = 1024 ) self . expansive_11 = nn . ConvTranspose2d ( in_channels = 1024 , out_channels = 512 , kernel_size = 3 , stride = 2 , padding = 1 , output_padding = 1 ) self . expansive_12 = self . conv_block ( in_channels = 1024 , out_channels = 512 ) self . expansive_21 = nn . ConvTranspose2d ( in_channels = 512 , out_channels = 256 , kernel_size = 3 , stride = 2 , padding = 1 , output_padding = 1 ) self . expansive_22 = self . conv_block ( in_channels = 512 , out_channels = 256 ) self . expansive_31 = nn . ConvTranspose2d ( in_channels = 256 , out_channels = 128 , kernel_size = 3 , stride = 2 , padding = 1 , output_padding = 1 ) self . expansive_32 = self . conv_block ( in_channels = 256 , out_channels = 128 ) self . expansive_41 = nn . ConvTranspose2d ( in_channels = 128 , out_channels = 64 , kernel_size = 3 , stride = 2 , padding = 1 , output_padding = 1 ) self . expansive_42 = self . conv_block ( in_channels = 128 , out_channels = 64 ) self . output = nn . Conv2d ( in_channels = 64 , out_channels = 64 , kernel_size = 3 , stride = 1 , padding = 1 ) self . output1 = nn . Conv2d ( in_channels = 64 , out_channels = num_classes , kernel_size = 1 , stride = 1 , padding = 1 ) def conv_block ( self , in_channels , out_channels ) : block = nn . Sequential ( nn . Conv2d ( in_channels = in_channels , out_channels = out_channels , kernel_size = 3 , stride = 1 , padding = 1 ) , nn . ReLU ( ) , nn . BatchNorm2d ( num_features = out_channels ) , nn . Conv2d ( in_channels = out_channels , out_channels = out_channels , kernel_size = 3 , stride = 1 , padding = 1 ) , nn . ReLU ( ) , nn . BatchNorm2d ( num_features = out_channels ) ) return block def forward ( self , X ) : contracting_11_out = self . contracting_11 ( X ) contracting_12_out = self . contracting_12 ( contracting_11_out ) contracting_21_out = self . contracting_21 ( contracting_12_out ) contracting_22_out = self . contracting_22 ( contracting_21_out ) contracting_31_out = self . contracting_31 ( contracting_22_out ) contracting_32_out = self . contracting_32 ( contracting_31_out ) contracting_41_out = self . contracting_41 ( contracting_32_out ) contracting_42_out = self . contracting_42 ( contracting_41_out ) middle_out = self . middle ( contracting_42_out ) expansive_11_out = self . expansive_11 ( middle_out ) expansive_12_out = self . expansive_12 ( torch . cat ( ( expansive_11_out , contracting_41_out ) , dim = 1 ) ) expansive_21_out = self . expansive_21 ( expansive_12_out ) expansive_22_out = self . expansive_22 ( torch . cat ( ( expansive_21_out , contracting_31_out ) , dim = 1 ) ) expansive_31_out = self . expansive_31 ( expansive_22_out ) expansive_32_out = self . expansive_32 ( torch . cat ( ( expansive_31_out , contracting_21_out ) , dim = 1 ) ) expansive_41_out = self . expansive_41 ( expansive_32_out ) expansive_42_out = self . expansive_42 ( torch . cat ( ( expansive_41_out , contracting_11_out ) , dim = 1 ) ) output_out = self . output ( expansive_42_out ) output_out1 = self . output ( output_out ) return output_out1
Step 2. 모델 학습
batch_size = 4 epochs = 10 lr = 0.01 dataset = CityscapeDataset ( train_dir , label_model ) data_loader = DataLoader ( dataset , batch_size = batch_size ) model = UNet ( num_classes = num_classes ) . to ( device ) criterion = nn . CrossEntropyLoss ( ) optimizer = optim . Adam ( model . parameters ( ) , lr = lr ) step_losses = [ ] epoch_losses = [ ] for epoch in tqdm ( range ( epochs ) ) : epoch_loss = 0 for X , Y in tqdm ( data_loader , total = len ( data_loader ) , leave = False ) : X , Y = X . to ( device ) , Y . to ( device ) optimizer . zero_grad ( ) Y_pred = model ( X ) loss = criterion ( Y_pred , Y ) loss . backward ( ) optimizer . step ( ) epoch_loss += loss . item ( ) step_losses . append ( loss . item ( ) ) epoch_losses . append ( epoch_loss / len ( data_loader ) )
tqdm 라이브러리
학습을 통해 얻은 손실함수를 확인해보겠습니다.
print ( len ( epoch_losses ) ) print ( epoch_losses )
출력 결과 10 [1.2644546631202902, 0.8764938149721392, 0.7952614437828782, 0.7531729845270034, 0.7165372273934785, 0.6903373579023987, 0.6792501089393451, 0.6337115100474768, 0.6319557054629249, 0.6149069263890226]
학습을 통해 손실함수가 감소한 것을 확인할 수 있습니다.
이제 학습의 결과(training losses)를 그래프를 통해 확인해보겠습니다.
fig , axes = plt . subplots ( 1 , 2 , figsize = ( 10 , 5 ) ) axes [ 0 ] . plot ( step_losses ) axes [ 1 ] . plot ( epoch_losses ) plt . show ( )
왼쪽이 step_losses, 오른쪽이 epoch_losses의 결과 그래프입니다.
모델 저장
이제 학습시킨 모델을 저장합니다.
model_name = “UNet.pth” torch . save ( model . state_dict ( ) , root_path + model_name )
Step 3. 모델 평가하기
model_path = root_path + model_name model_ = UNet ( num_classes = num_classes ) . to ( device ) model_ . load_state_dict ( torch . load ( model_path ) )
model_.load_state_dict( ) – 1
model_load_state_dict( ) – 2
pickle 모듈
역직렬화
test_batch_size = 8 dataset = CityscapeDataset ( val_dir , label_model ) data_loader = DataLoader ( dataset , batch_size = test_batch_size ) X , Y = next ( iter ( data_loader ) ) X , Y = X . to ( device ) , Y . to ( device ) Y_pred = model_ ( X ) print ( Y_pred . shape ) Y_pred = torch . argmax ( Y_pred , dim = 1 ) print ( Y_pred . shape )
# 출력결과 => test_batch_size에 따라 8은 변할 수 있음 torch.Size([8, 64, 256, 256]) torch.Size([8, 256, 256])
inverse_transform = transforms . Compose ( [ transforms . Normalize ( ( – 0.485 / 0.229 , – 0.456 / 0.224 , – 0.406 / 0.225 ) , ( 1 / 0.229 , 1 / 0.224 , 1 / 0.225 ) ) ] )
fig , axes = plt . subplots ( test_batch_size , 3 , figsize = ( 3 * 5 , test_batch_size * 5 ) ) iou_scores = [ ] for i in range ( test_batch_size ) : landscape = inverse_transform ( X [ i ] ) . permute ( 1 , 2 , 0 ) . cpu ( ) . detach ( ) . numpy ( ) label_class = Y [ i ] . cpu ( ) . detach ( ) . numpy ( ) label_class_predicted = Y_pred [ i ] . cpu ( ) . detach ( ) . numpy ( ) intersection = np . logical_and ( label_class , label_class_predicted ) union = np . logical_or ( label_class , label_class_predicted ) iou_score = np . sum ( intersection ) / np . sum ( union ) iou_scores . append ( iou_score ) axes [ i , 0 ] . imshow ( landscape ) axes [ i , 0 ] . set_title ( “Landscape” ) axes [ i , 1 ] . imshow ( label_class ) axes [ i , 1 ] . set_title ( “Label Class” ) axes [ i , 2 ] . imshow ( label_class_predicted ) axes [ i , 2 ] . set_title ( “Label Class – Predicted” ) plt . show ( )
pytorch의 permute( ) – 1
pytorch의 permute( ) – 2
# 출력결과 Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
test_batch_size = 8로 설정하여 8개의 이미지에 대한 결과가 출력되었습니다.
3.1.1 궁금한 것
Y_pred = torch . argmax ( Y_pred , dim = 0 )
위와 같이 이전의 코드를 변경하면 아래와 같은 이미지를 얻을 수 있습니다.
dim = 0과 dim = 1의 차이로 인해 정확도는 71.9%로 떨어졌다. 아직 이러한 결과가 발생하는 원인에 대해서 파악하지 못했습니다. 어째서 dim = 1로 주었는지 조금 더 생각해봐야겠습니다.
Step 4. IOU Score
지금까지 학습시킨 모델에 대하여, 정확도를 산출해보겠습니다. 흔히 알려진 평가지표인, IOU를 기준으로 정확도를 계산하겠습니다.
print ( sum ( iou_scores ) / len ( iou_scores ) )
# 출력결과 0.9954032897949219
우리가 학습시킨 모델의 IOU는 99.5%가 넘는 정확도를 보여줍니다!
+ 추가
batch_size와 test_batch_size 등에 따라 정확도가 달라지는 것을 확인하였습니다. 때문에 이 포스팅의 내용처럼 99프로가 나오지 않을 수 있습니다. 하지만 대부분 90프로 이상의 성능을 보여줍니다.
마지막으로, 긴 글 읽어주셔서 고맙다는 말씀드리며 딥러닝을 공부한지 얼마되지 않아 틀린 것이 있더라도 너그러이 이해해주시기 바랍니다~! 수정해야할 사항은 언제든지 댓글로 알려주세요!
[U-Net] U-Net 구조
이미지 세그멘테이션(image segmentation)은 이미지의 모든 픽셀이 어떤 카테고리(예를 들면 자동차, 사람, 도로 등)에 속하는지 분류하는 것을 말한다.
이미지 전체에 대해 단일 카테고리를 예측하는 이미지 분류(image classification)와는 달리, 이미지 세그멘테이션은 픽셀 단위의 분류를 수행하므로 일반적으로 더 어려운 문제로 인식되고 있다.
위 그림에서 semantic segmentation은 이미지 내에 있는 객체들을 의미 있는 단위로 분할해내는 것이고, instance segmentation 은 같은 카테고리에 속하는 서로 다른 객체까지 더 분할하여 semantic segmentation 범위를 확장한 것이다.
이미지 세그멘테이션은 의료 이미지 분석(종양 경계 추출 등), 자율주행 차량(도로면, 보행자 감지 등) 및 증강현실과 같은 광범위한 분야에서 사용되고 있다.
딥러닝을 이용한 이미지 세그멘테이션은 수백개의 알고리즘이 제안되어 있다고 하는데, 그 중 U-Net 모델을 Tensorflow 2로 구현해보고자 한다.
U-Net은 ‘U-Net: Convolutional Networks for Biomedical Image Segmentation’ 이라는 논문에서 제안한 구조로서 매우 적은 수의 학습 데이터로도 정확한 이미지 세그멘테이션 성능을 보여주었으며 ISBI 세포 추적 챌린지 2015에서 큰 점수 차이로 우승했다고 한다.
U-Net은 오토인코더(autoencoder)와 같은 인코더-디코더(encoder-decoder) 기반 모델에 속한다. 보통 인코딩 단계에서는 입력 이미지의 특징을 포착할 수 있도록 채널의 수를 늘리면서 차원을 축소해 나가며, 디코딩 단계에서는 저차원으로 인코딩된 정보만 이용하여 채널의 수를 줄이고 차원을 늘려서 고차원의 이미지를 복원한다. 하지만 인코딩 단계에서 차원 축소를 거치면서 이미지 객체에 대한 자세한 위치 정보를 잃게 되고, 디코딩 단계에서도 저차원의 정보만을 이용하기 때문에 위치 정보 손실을 회복하지 못하게 된다.
U-Net의 기본 아이디어는 저차원 뿐만 아니라 고차원 정보도 이용하여 이미지의 특징을 추출함과 동시에 정확한 위치 파악도 가능하게 하자는 것이다. 이를 위해서 인코딩 단계의 각 레이어에서 얻은 특징을 디코딩 단계의 각 레이어에 합치는(concatenation) 방법을 사용한다. 인코더 레이어와 디코더 레이어의 직접 연결을 스킵 연결(skip connection)이라고 한다.
원래 논문에서는 신경망 구조를 스킵 연결을 평행하게 두고 가운데를 기준으로 좌우가 대칭이 되도록 레이어를 배치하여, 이름 그대로 U자 형으로 만들었다.
U-Net 은 인코더 또는 축소경로(contracting path)와 디코더 또는 확장경로(expending path)로 구성되며 두 구조는 서로 대칭적이다. 인코더와 디코더를 연결하는 부분을 브릿지(bridge)라고 한다. 인코더와 디코더에서는 모두 3×3 컨볼루션을 사용한다. 인코더의 자세한 구조는 다음 그림과 같다. 맨 아래의 블록은 브릿지이다.
그림에서 세로 방향 숫자는 맵(map)의 차원을 표시하고 가로 방향 숫자는 채널 수를 표시한다. 예를 들면 세로 방향 숫자 256×256 과 가로 방향 숫자 128 은 해당 레이어의 이미지가 256x256x128 임을 의미한다. 입력 이미지는 512x512x3 이므로 RGB 3개 채널을 갖고 크기가 512×512 인 이미지를 나타낸다.
그림에서 파란색 박스가 인코더의 각 단계마다 계속 반복하여 나타나는 것을 볼 수 있는데, 이 박스는 3×3 컨볼루션, Batch Normalization, ReLU 활성화 함수가 차례로 배치된 것을 나타낸다. 이 박스 두 개를 한데 묶어서 한 개의 레이어 블록으로 구현하여 사용하면 편리하다. 이 블록 이름을 ConvBlock이라고 하자.
다음 코드는 ConvBlock을 구현한 것이다.
“”” Conv Block “”” class ConvBlock(tf.keras.layers.Layer): def __init__(self, n_filters): super(ConvBlock, self).__init__() self.conv1 = Conv2D(n_filters, 3, padding=’same’) self.conv2 = Conv2D(n_filters, 3, padding=’same’) self.bn1 = BatchNormalization() self.bn2 = BatchNormalization() self.activation = Activation(‘relu’) def call(self, inputs): x = self.conv1(inputs) x = self.bn1(x) x = self.activation(x) x = self.conv2(x) x = self.bn2(x) x = self.activation(x) return x
인코더 그림을 보면 보라색 박스안에 한 개의 ConvBlock이 있고 이 박스가 인코더의 각 단계마다 나타나는 것을 볼 수 있다. 이 박스에서 나오는 출력이 2개인데, 한 개의 출력은 U-Net의 디코더로 복사하기 위한 연결선이며, 또 한 개의 출력은 2×2 max pooling 으로 다운 샘플링(down sampling)하여 인코더의 다음 단계로 내보내는 빨간색 화살선이다. 이 박스도 한 개의 레이어 블록으로 구현하여 사용하면 편리하다. 이 블록 이름을 EncoderBlock이라고 하자.
다음 코드는 EncoderBlock을 구현한 것이다.
“”” Encoder Block “”” class EncoderBlock(tf.keras.layers.Layer): def __init__(self, n_filters): super(EncoderBlock, self).__init__() self.conv_blk = ConvBlock(n_filters) self.pool = MaxPooling2D((2,2)) def call(self, inputs): x = self.conv_blk(inputs) p = self.pool(x) return x, p
브릿지는 두개의 파란색 박스로만 구성되어 있으므로 1개의 ConvBlock 레이어로 표현할 수 있다.
디코더의 자세한 구조는 다음 그림과 같다.
그림에서 파란색 박스 2개는 인코더에 있는 ConvBlock와 동일하다. 녹색 박스는 스킵 연결을 통해서 인코더에 있는 맵을 복사한 것이다. 노란색 박스는 디코더의 하위 단계에서 전치 컨볼루션(transposed convolution)을 통해서 맵의 차원을 두배로 늘리면서 채널 수를 반으로 줄인 것이다. 두 개의 맵을 서로 합쳐서(concatenation) 저차원 이미지 정보뿐만 아니라 고차원 정보도 이용할 수 있는 것이다.
디코더의 그림에서도 회색 박스가 반복적으로 나타나므로 한 개의 레이어 블록으로 구현하여 사용하면 편리하다. 이 블록 이름을 DecoderBlock 이라고 하자.
다음 코드는 DecoderBlock을 구현한 것이다.
“”” Decoder Block “”” class DecoderBlock(tf.keras.layers.Layer): def __init__(self, n_filters): super(DecoderBlock, self).__init__() self.up = Conv2DTranspose(n_filters, (2,2), strides=2, padding=’same’) self.conv_blk = ConvBlock(n_filters) def call(self, inputs, skip): x = self.up(inputs) x = Concatenate()([x, skip]) x = self.conv_blk(x) return x
디코더 그림의 맨 상단의 오른쪽 부분은 U-Net의 출력으로서 1×1 컨볼루션으로 특징 맵을 처리하여 입력 이미지의 각 픽셀을 분류하는 세그멘테이션 맵을 생성하는 부분이다. 컨볼루션 필터의 개수는 분류할 카테고리 개수이며 활성 함수로는 카테고리 수가 1개라면 sigmoid 함수를, 여러 개라면 softmax 함수를 사용한다.
EncoderBlock과 DecoderBlock 을 사용하면 U-Net을 다음과 같이 간단히 코드로 구현할 수 있다.
“”” U-Net Model “”” class UNET(tf.keras.Model): def __init__(self, n_classes): super(UNET, self).__init__() # Encoder self.e1 = EncoderBlock(64) self.e2 = EncoderBlock(128) self.e3 = EncoderBlock(256) self.e4 = EncoderBlock(512) # Bridge self.b = ConvBlock(1024) # Decoder self.d1 = DecoderBlock(512) self.d2 = DecoderBlock(256) self.d3 = DecoderBlock(128) self.d4 = DecoderBlock(64) # Outputs if n_classes == 1: activation = ‘sigmoid’ else: activation = ‘softmax’ self.outputs = Conv2D(n_classes, 1, padding=’same’, activation=activation) def call(self, inputs): s1, p1 = self.e1(inputs) s2, p2 = self.e2(p1) s3, p3 = self.e3(p2) s4, p4 = self.e4(p3) b = self.b(p4) d1 = self.d1(b, s4) d2 = self.d2(d1, s3) d3 = self.d3(d2, s2) d4 = self.d4(d3, s1) outputs = self.outputs(d4) return outputs
U-Net 모델의 전체 코드는 다음과 같다.
unet_model.py
# U-Net model # coded by st.watermelon import tensorflow as tf from tensorflow.keras.layers import Conv2D, MaxPooling2D, Conv2DTranspose from tensorflow.keras.layers import Activation, BatchNormalization, Concatenate “”” Conv Block “”” class ConvBlock(tf.keras.layers.Layer): def __init__(self, n_filters): super(ConvBlock, self).__init__() self.conv1 = Conv2D(n_filters, 3, padding=’same’) self.conv2 = Conv2D(n_filters, 3, padding=’same’) self.bn1 = BatchNormalization() self.bn2 = BatchNormalization() self.activation = Activation(‘relu’) def call(self, inputs): x = self.conv1(inputs) x = self.bn1(x) x = self.activation(x) x = self.conv2(x) x = self.bn2(x) x = self.activation(x) return x “”” Encoder Block “”” class EncoderBlock(tf.keras.layers.Layer): def __init__(self, n_filters): super(EncoderBlock, self).__init__() self.conv_blk = ConvBlock(n_filters) self.pool = MaxPooling2D((2,2)) def call(self, inputs): x = self.conv_blk(inputs) p = self.pool(x) return x, p “”” Decoder Block “”” class DecoderBlock(tf.keras.layers.Layer): def __init__(self, n_filters): super(DecoderBlock, self).__init__() self.up = Conv2DTranspose(n_filters, (2,2), strides=2, padding=’same’) self.conv_blk = ConvBlock(n_filters) def call(self, inputs, skip): x = self.up(inputs) x = Concatenate()([x, skip]) x = self.conv_blk(x) return x “”” U-Net Model “”” class UNET(tf.keras.Model): def __init__(self, n_classes): super(UNET, self).__init__() # Encoder self.e1 = EncoderBlock(64) self.e2 = EncoderBlock(128) self.e3 = EncoderBlock(256) self.e4 = EncoderBlock(512) # Bridge self.b = ConvBlock(1024) # Decoder self.d1 = DecoderBlock(512) self.d2 = DecoderBlock(256) self.d3 = DecoderBlock(128) self.d4 = DecoderBlock(64) # Outputs if n_classes == 1: activation = ‘sigmoid’ else: activation = ‘softmax’ self.outputs = Conv2D(n_classes, 1, padding=’same’, activation=activation) def call(self, inputs): s1, p1 = self.e1(inputs) s2, p2 = self.e2(p1) s3, p3 = self.e3(p2) s4, p4 = self.e4(p3) b = self.b(p4) d1 = self.d1(b, s4) d2 = self.d2(d1, s3) d3 = self.d3(d2, s2) d4 = self.d4(d3, s1) outputs = self.outputs(d4) return outputs
So you have finished reading the u net 구현 topic article, if you find this article useful, please share it. Thank you very much. See more: U-Net PyTorch custom dataset, u-net github, U-Net custom dataset, U Net pytorch GitHub, u-net pytorch, UNet Pytorch 구현, Tensorflow U-Net, unet++